上下文工程的重要性:
- 降低从零开始训练模型中可能存在的沉没成本
- 增加迭代速度,提高将模型转化为应用/交付的效率
- 模型与产品解耦,并发挥基座模型持续进步的红利
- 上下文工程影响 Agent 的速度、纠错能力和扩展性
经验 1:将 KV-cache 命中率作为生产的重要指标
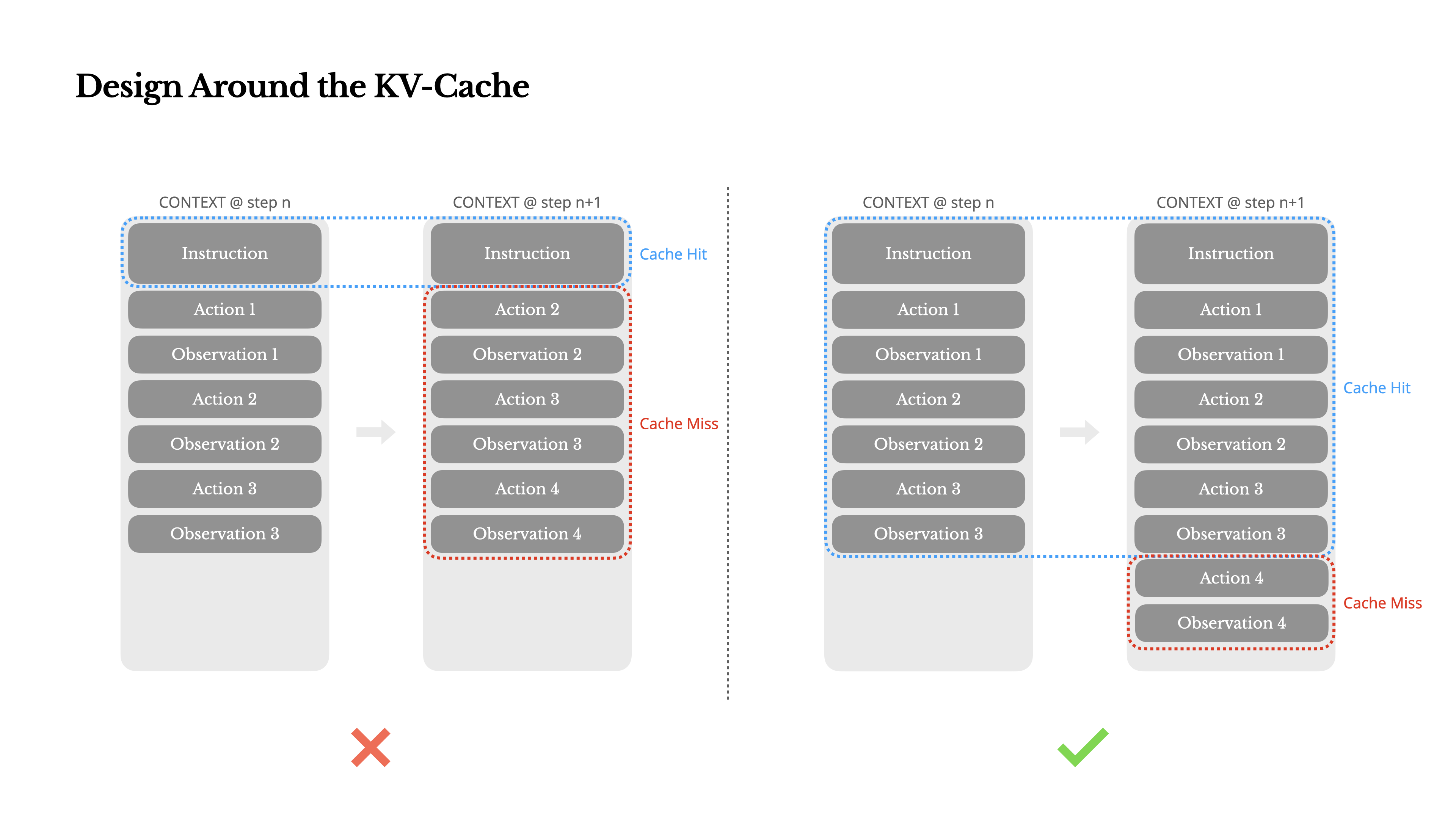
- KV-cache 命中率直接影响延迟和成本;以 Claude Sonnet 为例,输入 token 借助 KV 缓存技术能够降低 10 倍的推力成本(3 美元/百万 token -> 0.3 美元/百万 token)
- 保持 Prompt 文本稳定性,提高KV-cache 命中率;(1)避免将时间戳等动态信息引入系统提示(2)避免修改历史的操作或观察, 多考虑追加操作以减少对缓存的影响(3)在必要时,显式标记出缓存断电
经验 2:使用遮蔽(Mask)来管理工具的可用性
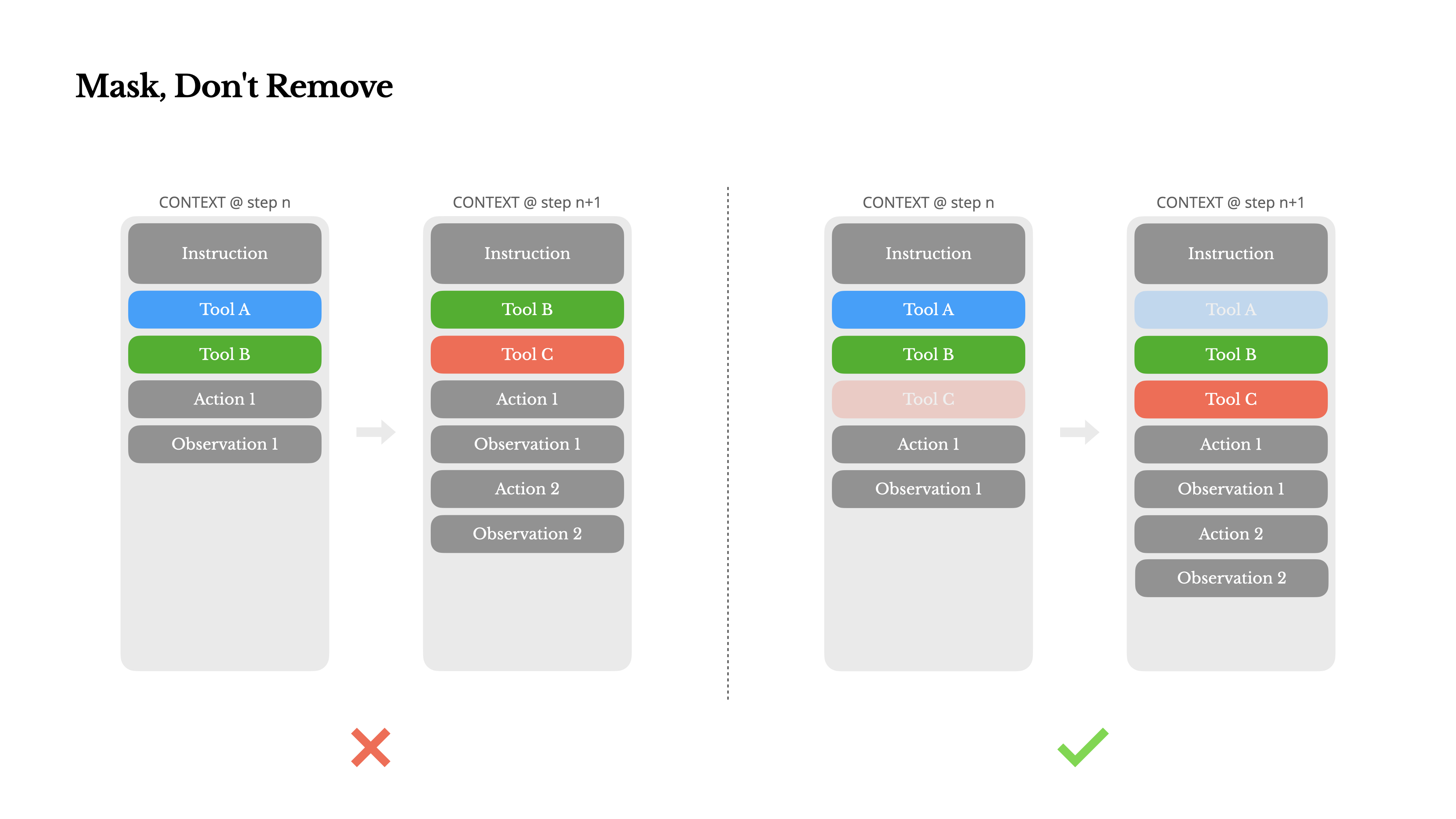
- MCP 等服务的流行会引入过多的 Agent 工具,反而影响 Agent 的性能
- Agent 应该尽量避免在迭代过程中动态添加或移除工具;因此(1)对工具定义的动态修改,可能导致后续 KV 缓存失效(2)迭代过程中工具定义的不一致,容易影响模型性能(违规/幻觉)
- 当前函数调用通常有三种模式来约束动作空间(1)自动模式,模型自主选择/决定函数的调用(2)必需模式,约束模型必须调用函数,但不限制具体函数(3)指定模式,约束模型必须从特定子集中调用函数
经验 3:使用文件系统作为上下文
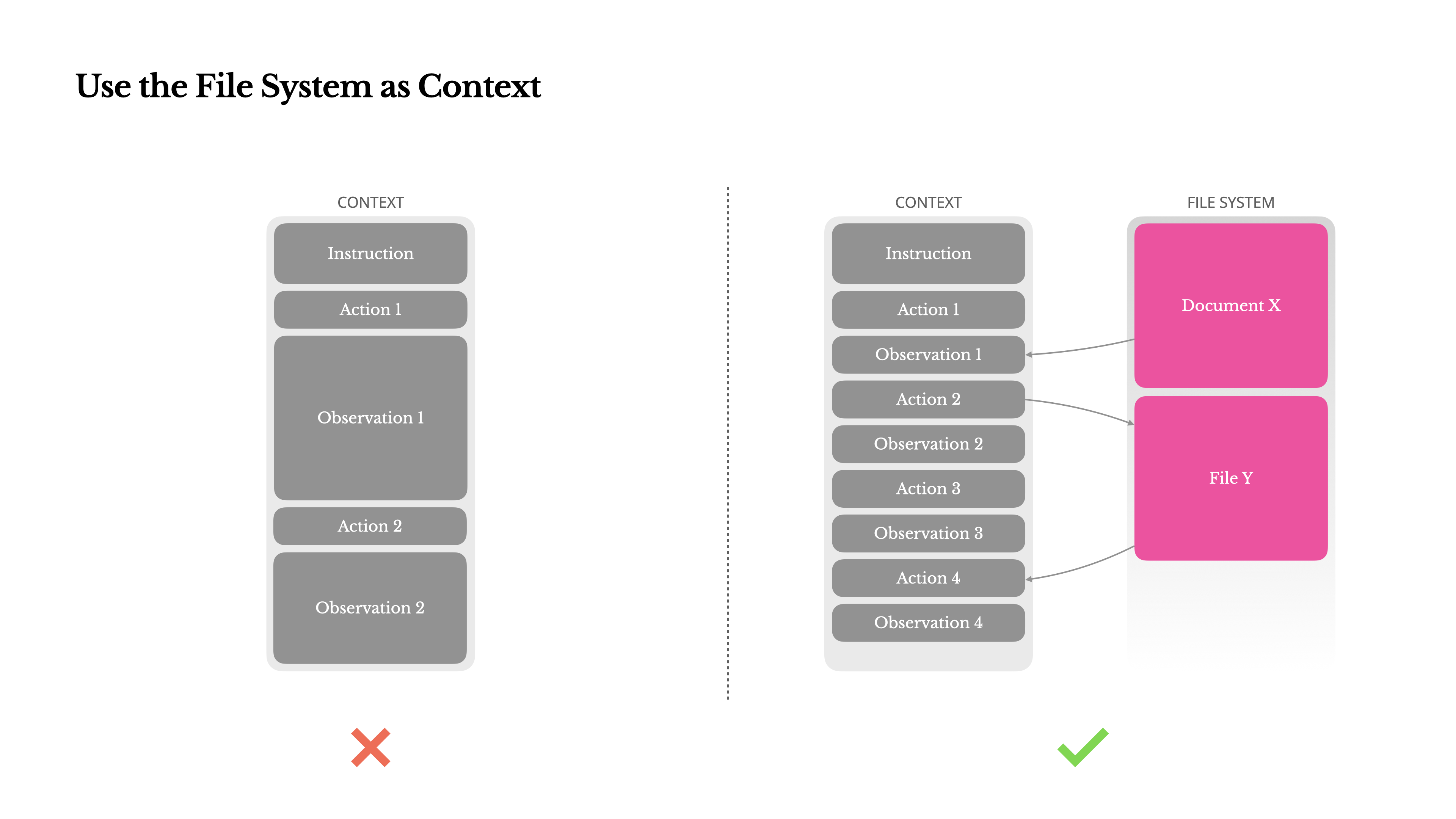
- 当前主流 LLMs 所支持的上下文存在不足(1)与 PDF/网页等非结构化数据交互时,容易超出上下文限制(2)当上下文长度超过一定阈值后,模型性能存在下降(3)输入文本过长时推理成本高
- 已有 Agent 系统多采用上下文截断或压缩策略,但容易导致信息丢失;一个根本性问题在于,Agent 本质上必须掌握所有历史状态,才能更好地预测下一个动作;任何不可逆的压缩都存在风险
- 用文件系统作为上下文的好处(1)上下文大小不受限制(2)内容天然持久化,并且 Agent 可以直接操作(3)Agent 可以按需写入和读取文件,并作为存储/外部记忆(4)使用可恢复的压缩策略
经验 4:利用待办任务清单来保持 Agent 的注意力
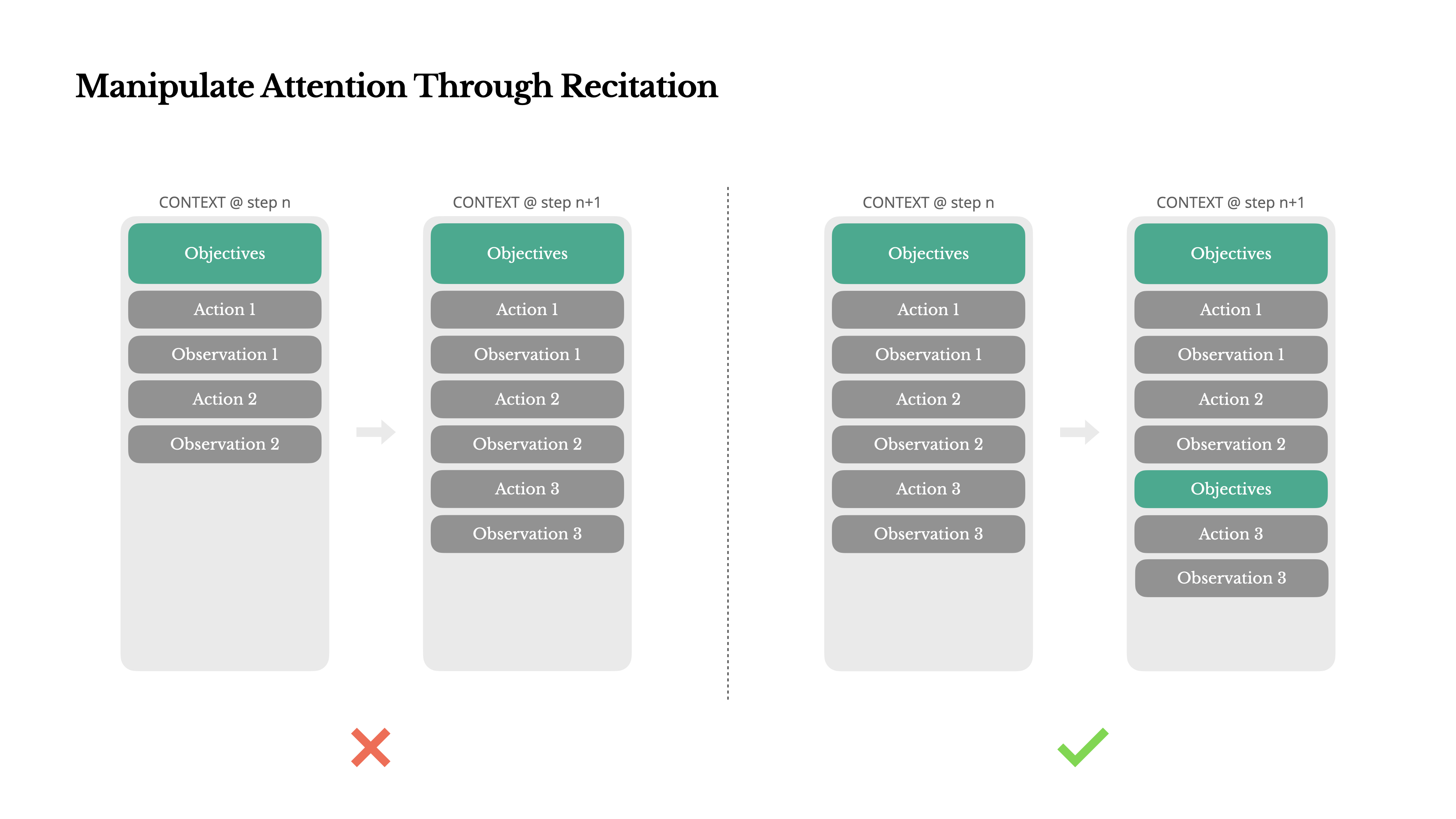
- 在处理复杂任务时,Agent 倾向于创建一个待办任务清单,并在任务进行过程中逐步更新它,勾选已完成的项目;该方式能操纵 Agent 注意力,保持迭代中的任务一致性,避免主题偏离或遗忘等问题
经验 5:用错题本来促进模型的改进

- 在多步骤任务中,失败不是例外,而是正常迭代/循环的一部分
- 在上下文中记录错误的尝试,是改善 Agent 行为的简单有效方法
经验 6:避免单一少样本提示引发的困难
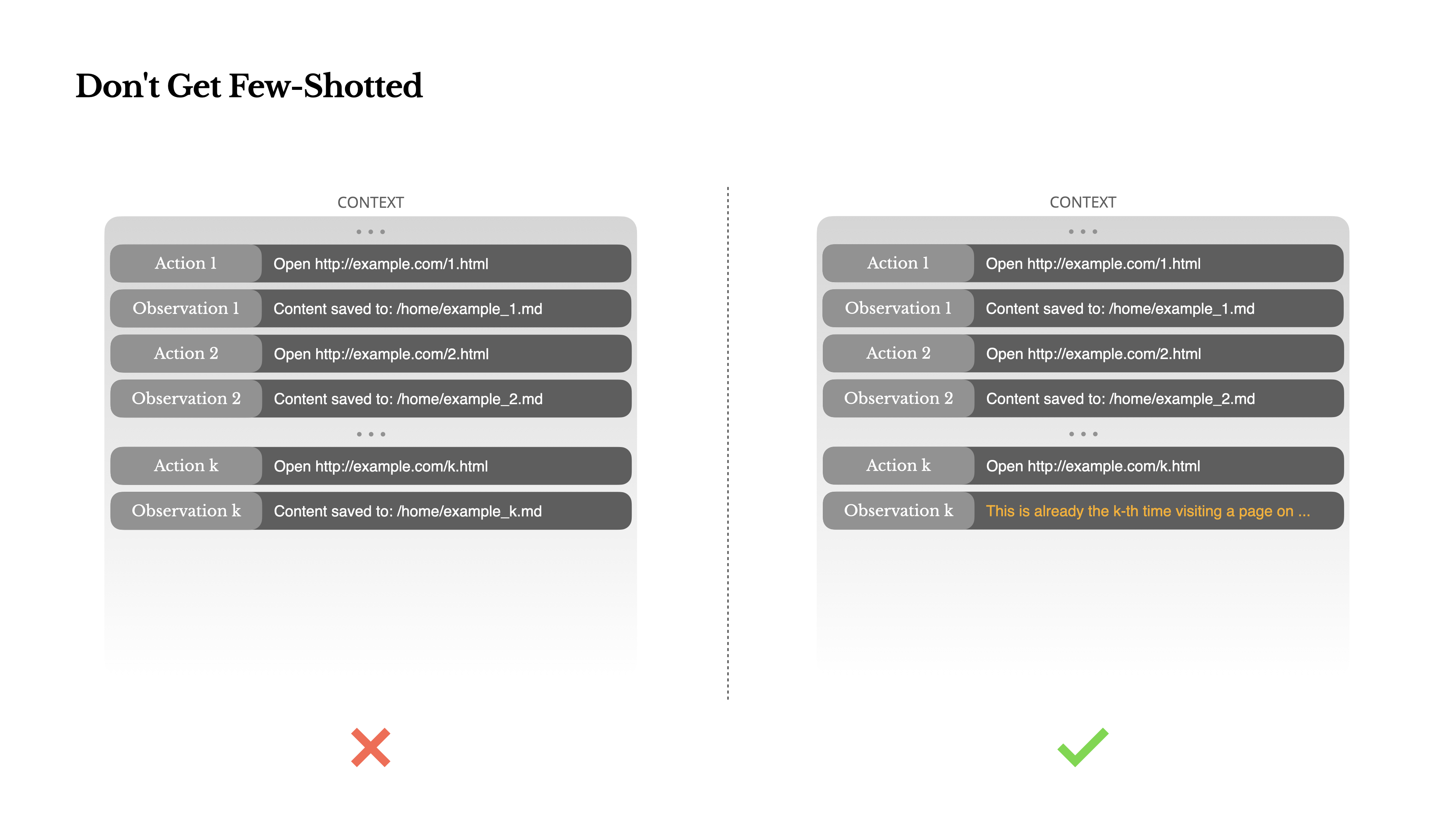
- 少样本提示是优化 LLM 输出的常见技术;但过度单一且重复的少样本提示,将导致模型的行为刻板化,进而导致结果的偏离、过度泛化,或有时产生幻觉
- 一个合理的解决方法是增加多样性,即在少样本提示基础上引入不同的序列化模板、替代性措辞、顺序或格式上的微小噪音。这种受控的随机性有助于打破模式并调整模型的注意力