OpenRouter 作为流行大模型 API 路由平台
- 覆盖了 60 多个供应商的 300+多个活跃模型,服务数百万开发者和终端用户
- 积累了大量 AI 模型的消耗记录,其局限性在于其中超过 50%的使用源自美国境
本文内容主要参考自:基于 OpenRouter 百万亿 token 消耗的 AI 现状研究报告
开源模型与闭源模型
开源模型与闭源模型的绝对市场占比:
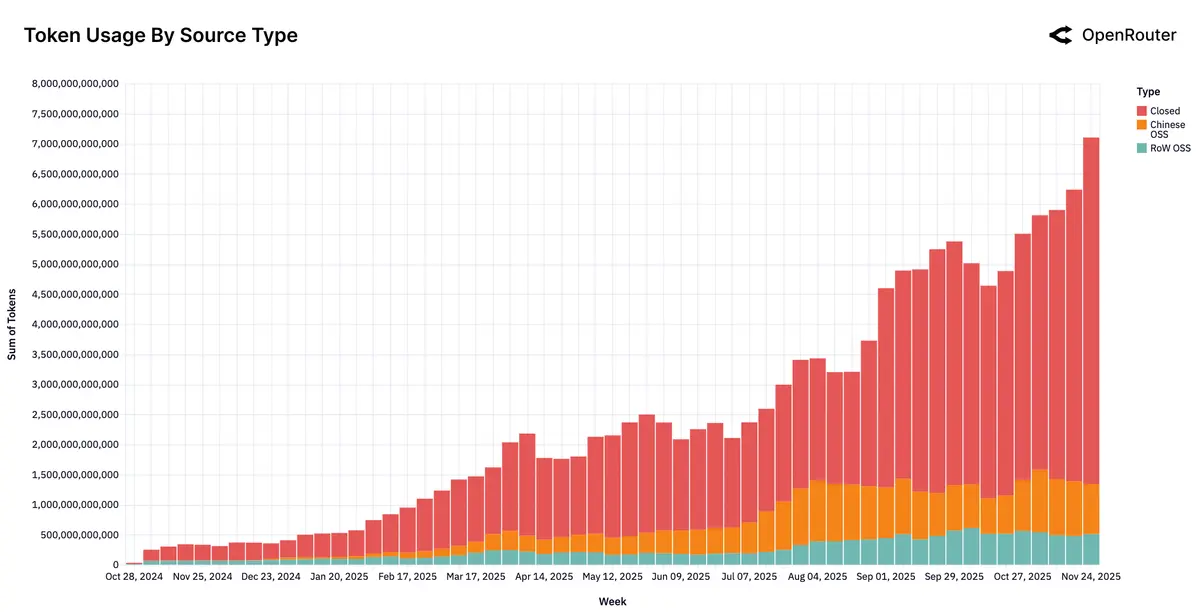
- 深红色表示闭源模型(Closed),橙色表示中国开源模型(Chines
分类目录归档:碎碎念念
OpenRouter 作为流行大模型 API 路由平台
本文内容主要参考自:基于 OpenRouter 百万亿 token 消耗的 AI 现状研究报告
开源模型与闭源模型的绝对市场占比:
相关资源:FreshRSS 用户手册、FreshRSS 官方文档、插件汇总
/var/www/FreshRSS/data,该路径映射的外部路径为:/var/lib/docker/volumes/freshrss_data/_datadata 文件夹;FreshRSS 的全局配置文件是 data/config.php;假设用户名称为 qwq,则用户配置文件是 data/users/qwq/co前置知识:检索增强 RAG
问题现象:知识库中缺少上下文,导致 RAG 给出一个看似合理但错误的答案
解决方案:
问题现象:不合理的检索排序导致关键文档被遗漏,没有被正确返回给 LLM
解决方案:
摘录自 《医疗 CoT 全面分析》
思路分析:
提示文本:
# 多位分析师 + 多轮迭代 做 病例诊断
你是临床问诊专家,有强大的临床思维和海量的医学疾病的模式识别,你和顶尖医生在数据源:基于匿名化的数十亿 Microsoft 365 的全球聚合信息(很权威)
总结如下(原始报告):
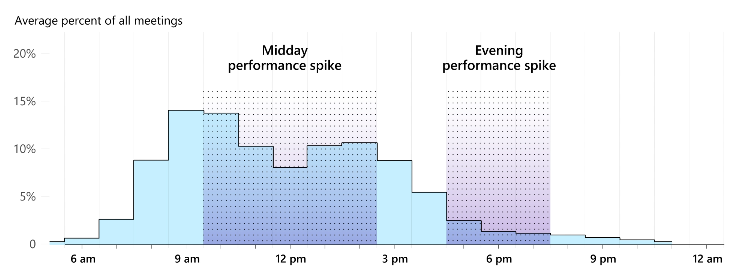
清晨:工作日的一天从打开塞满邮件的收件箱开始~
中午:工作日最宝贵的黄金时间被拆分的七零八落~
本文内容存在时效性问题,部分工具或链接可能失效
Perplexity 流行的 AI 搜索
Morphic AI 搜索引擎|开源
OnionAISearch AI 搜索引擎聚合
OpenEvidence 医疗 AI 信息平台 (国内不可用)

Harvey 法律领域专业 AI 工具
Lovart 专注设计的 AI 绘图工具

Flux Tools | 自定义海报中的文案

Gamma PPT 和网站生成|支持灵活的布局调整(推荐)

FateTell - AI 命理解读|日运日签
本文内容存在时效性问题,LLMs 最新排名可点击链接跳转查看
FACTS Grounding 谷歌和 Kaggle 推出的 AI 模型的真实性和基础推理能力

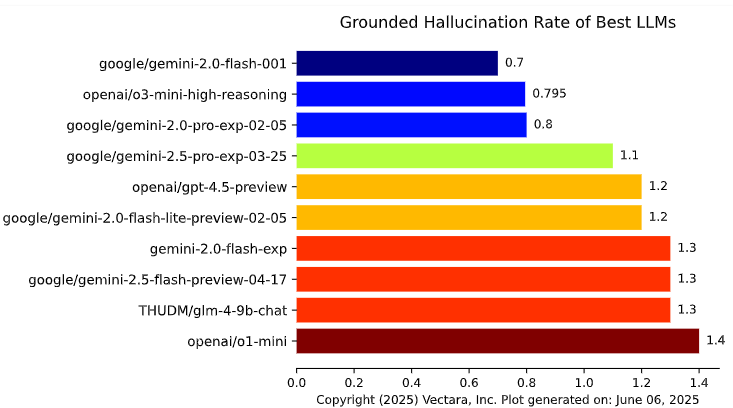
HHEM Leaderboard 幻觉测试排名
HLE:LLMs 基准测试|人类终极考试
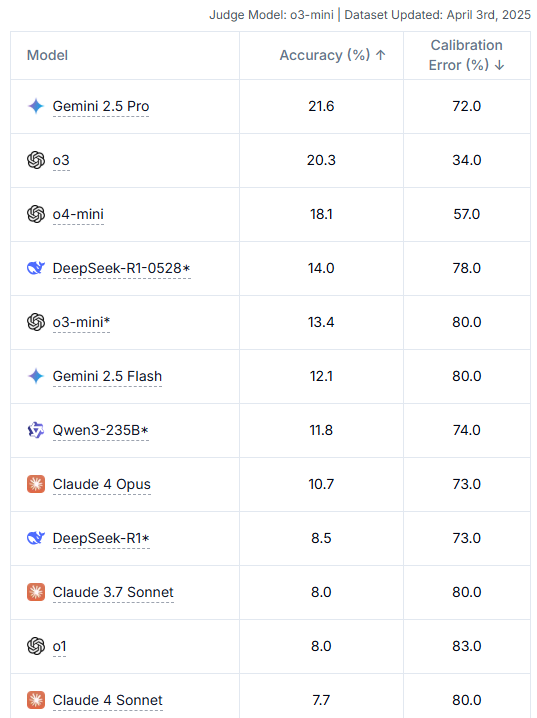
LiveBench:动态测试|防作弊 LLMs 榜单
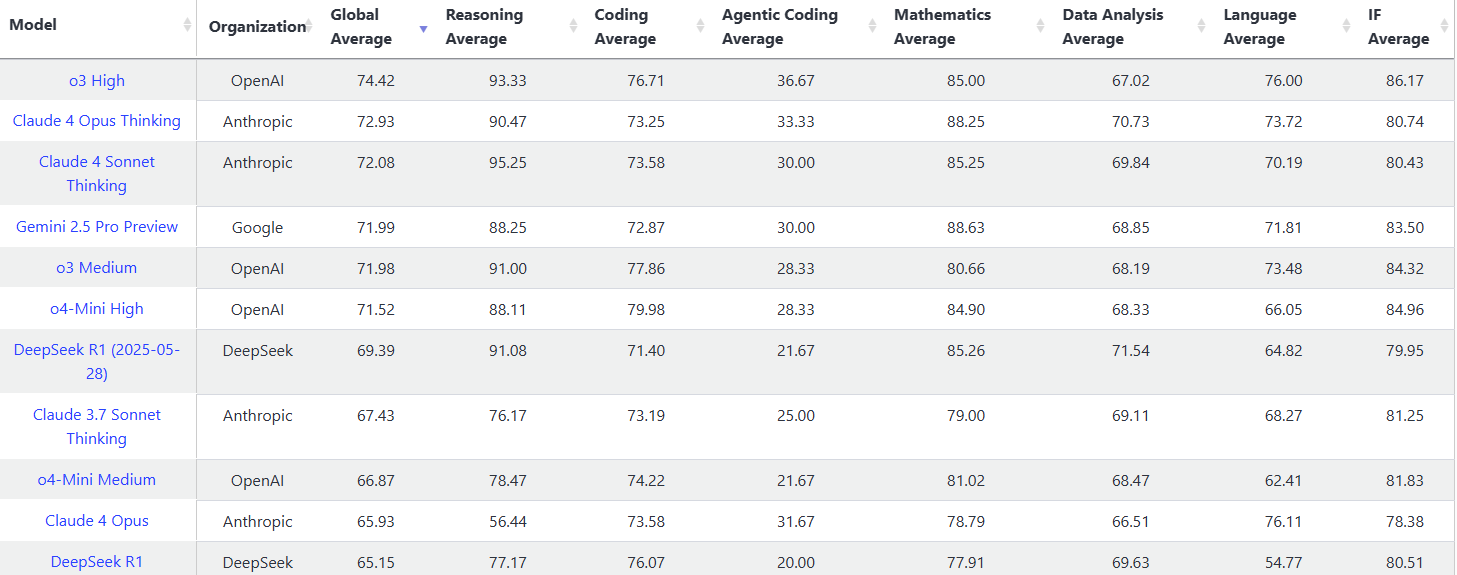
大模型斗兽场 LLMs 排名|ELO 评分系统
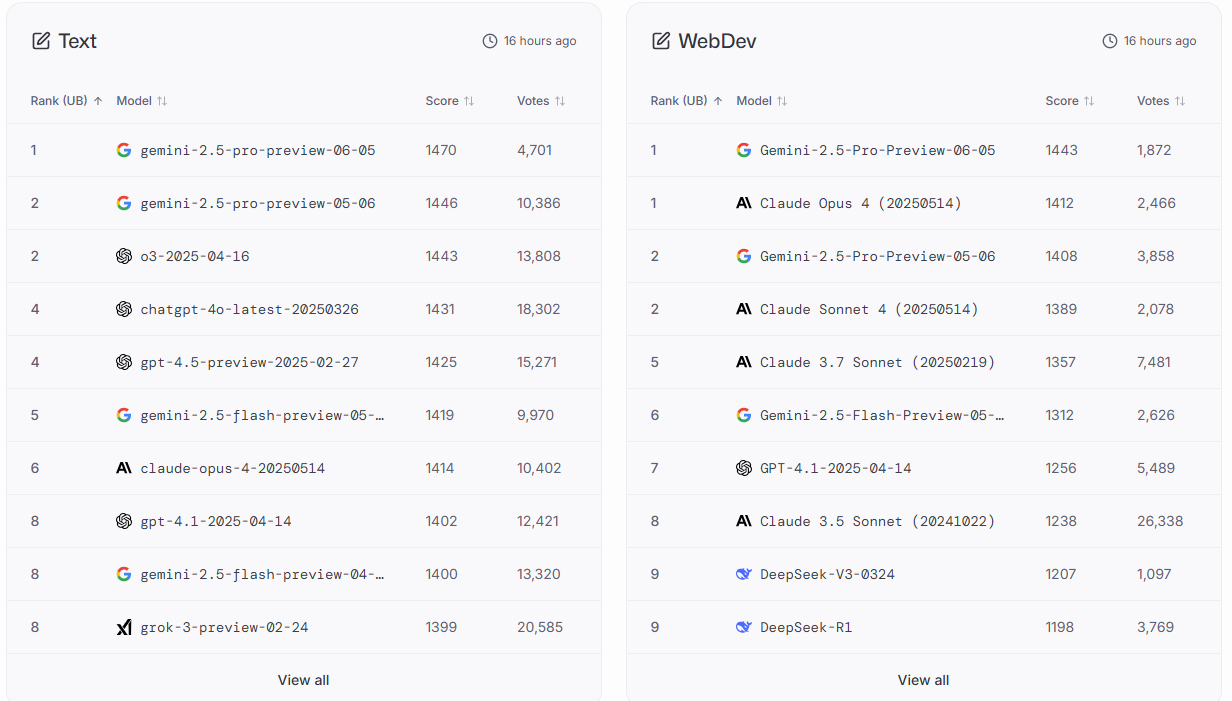
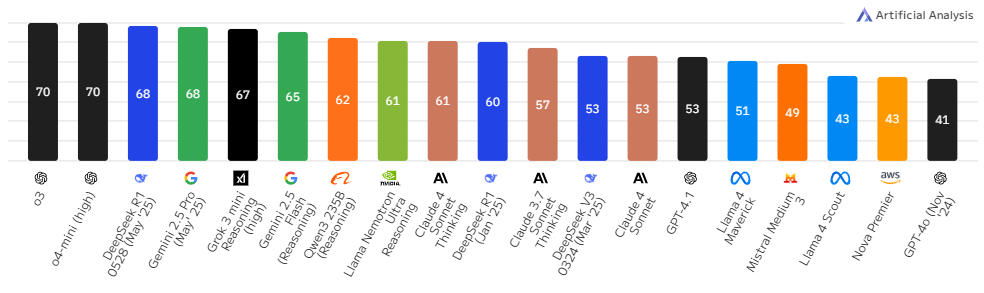
Artificial Analysis 人工智能分析综合指数,包含 7 项评估:MMLU-Pro、GPQA Diamond、人类最后考试、LiveCodeBench、SciCode、AIME、MATH-500
其他: