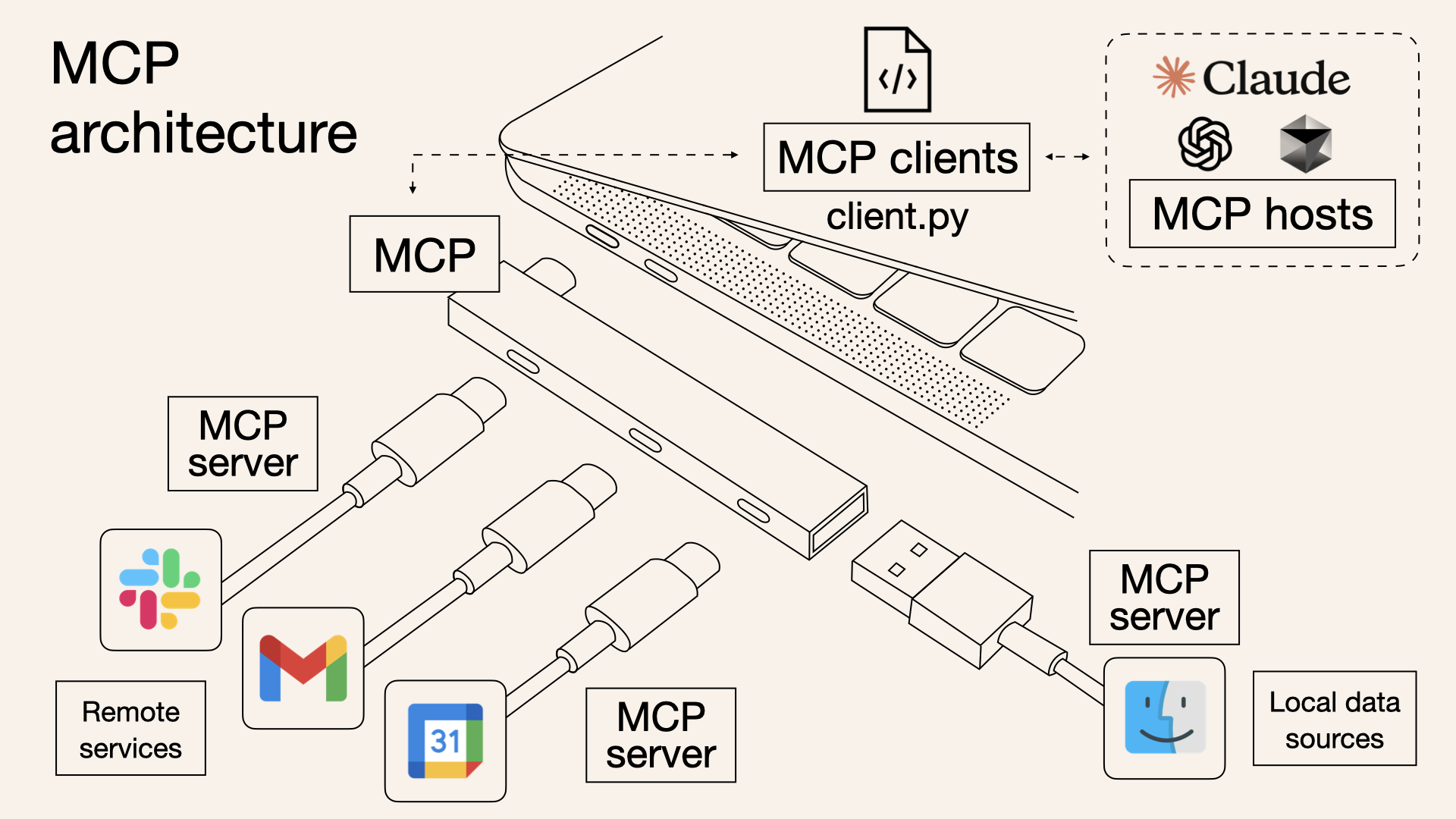
本文内容存在时效性问题,LLMs 最新排名可点击链接跳转查看
FACTS Grounding 谷歌和 Kaggle 推出的 AI 模型的真实性和基础推理能力

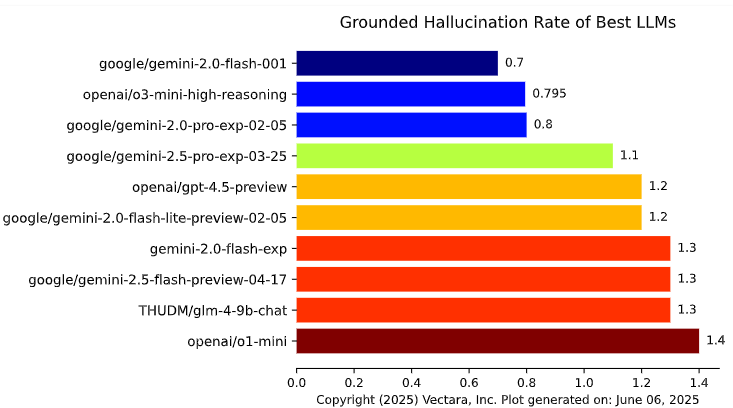
HHEM Leaderboard 幻觉测试排名
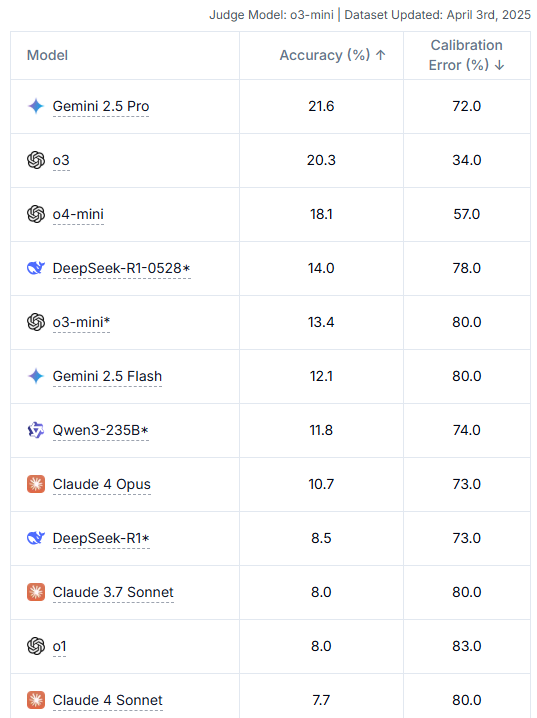
HLE:LLMs 基准测试|人类终极考试
LiveBench:动态测试|防作弊 LLMs 榜单
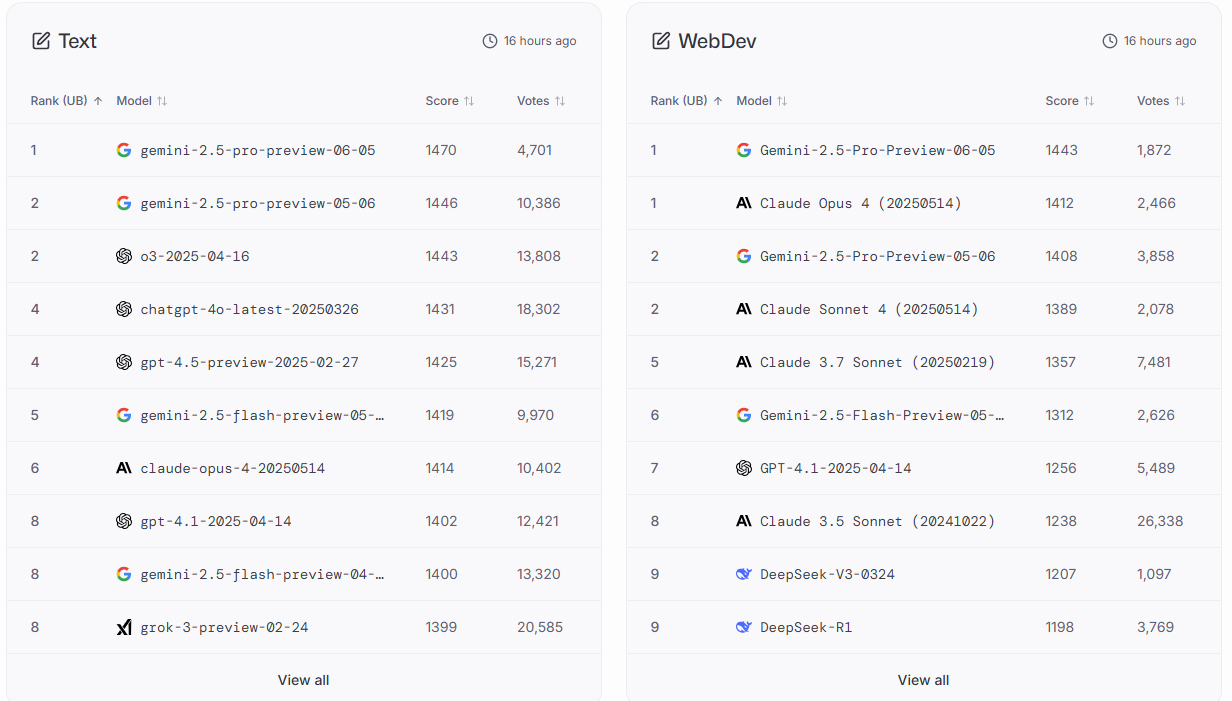
大模型斗兽场 LLMs 排名|ELO 评分系统
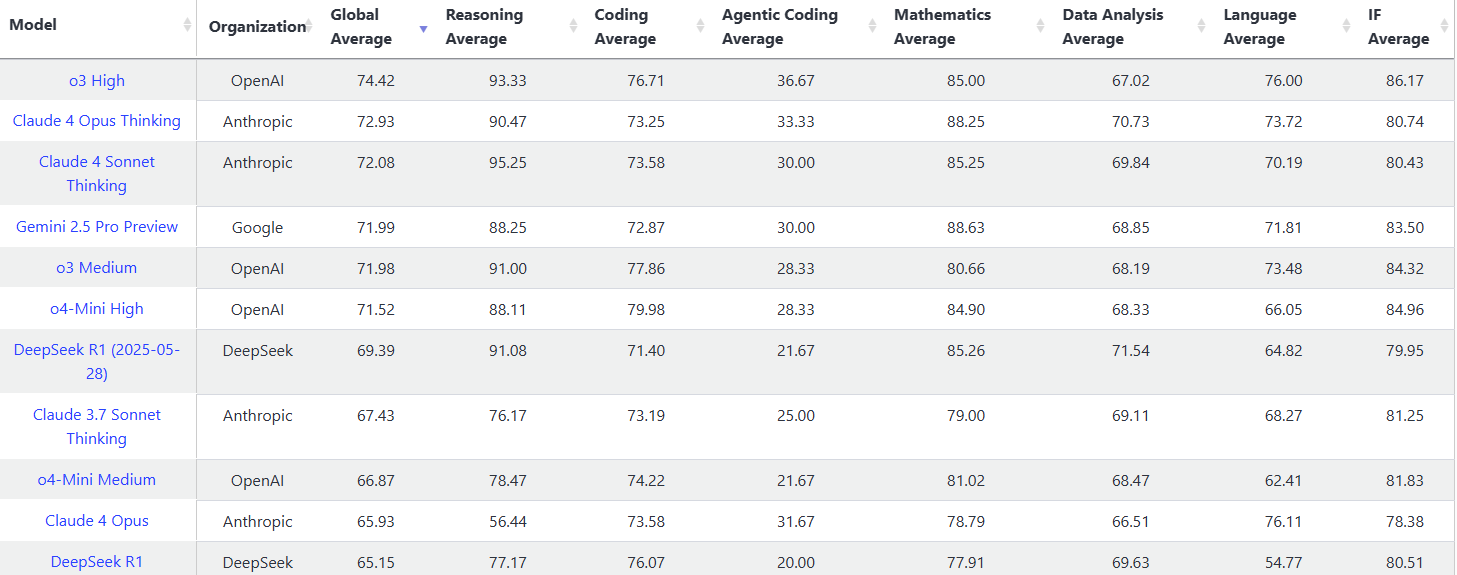
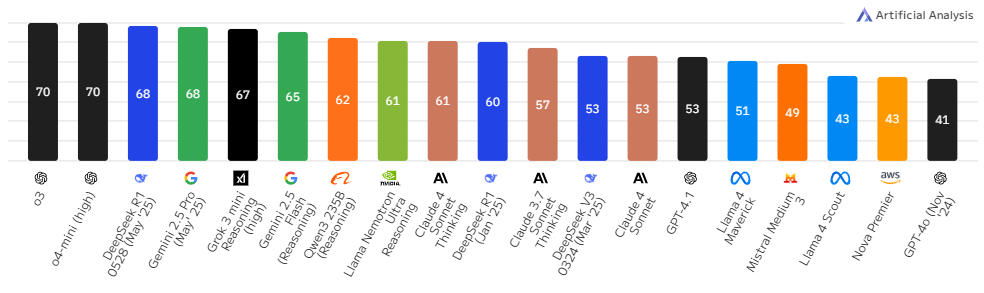
Artificial Analysis 人工智能分析综合指数,包含 7 项评估:MMLU-Pro、GPQA Diamond、人类最后考试、LiveCodeBench、SciCode、AIME、MATH-500
其他: