大语言模型(LLMs)的上下文学习:经过预训练的 LLMs 能根据文本提示或任务示例来直接对下游任务进行预测,而无需更新模型权重,这种能力也被称为上下文学习(in-context learning,ICL)或语境学习
简单来说,ICL 就是在不更新模型参数的前提下,通过输入经典示例作为提示来增强模型的能力
以情感分析为例,来说明 ICL 的一般流程(图源):
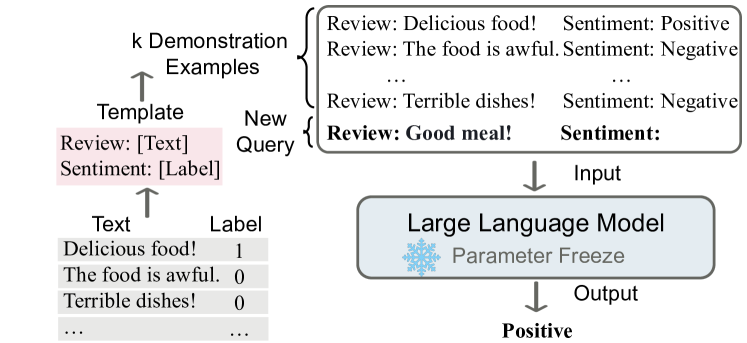
- ICL 需要一些示例来形成一个用于情景演示的上下文,作为提示输入来增强 LLMs
- ICL 示例一般用自然语言模板编写,并拼接真实的输入查询(Text)与结果(Label)
ICL 的分类:
- Few-shot learning,