1 基本介绍
对抗性鲁棒性工具集(Adversarial Robustness Toolbox,ART)是用于机器学习安全性的Python库
- 从逃逸,数据污染,模型提取和推断的对抗性威胁等方面捍卫和评估模型
- 适用广泛,支持所有常见的数据类型、机器学习任务、机器学习框架
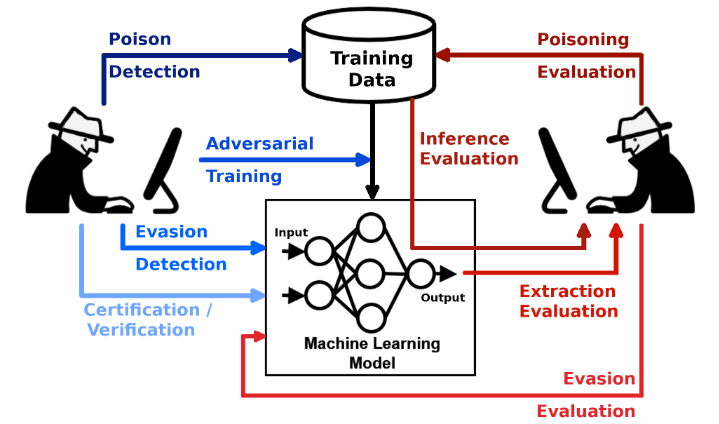
本项目由IBM团队在2019年开源。项目文档不是特别完善,但是示例丰富,API设计
对抗性鲁棒性工具集(Adversarial Robustness Toolbox,ART)是用于机器学习安全性的Python库
本项目由IBM团队在2019年开源。项目文档不是特别完善,但是示例丰富,API设计
对于回归方程$Y = a + bX + e$,当解释变量$X$和误差项$e$存在相关性时,说明回归模型存在内生性问题
内生性问题的产生原因:
内生性问题的后果:在小样本下,内生变量和外生变量估计系数都有偏。在大样本下,内生变量估计系数不一致。外

许立志(1990年7月28日-2014年9月30日),曾用笔名浅晓痕,中国诗人
1990年7月28日,许立志生于广东省揭阳市玉湖镇东寮村。2010年,开始诗歌创作。2011年初,进入深圳富士康工厂成为一名流水线工人。2012年起,在厂刊《富士康人》上发表诗歌、散文等30余篇。2014年9月30日,从深圳龙华一座大厦的17层跳楼身亡,终年24岁。
按照习俗,自杀者不能归葬祖坟。2014年10月15日傍晚,许立志的哥哥将他的骨灰撒进了深圳南澳的海水中。
这大海葬着立志——陈年喜
后来人们
核密度估计(kernel density estimation,简称KDE)是核平滑对概率密度估计的应用,即一种以核为权重估计随机变量概率密度函数的非参数方法。由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window)
核密度估计的实现:
贝叶斯优化是一种通用的黑盒优化算法,不需要计算梯度便可快速解决最优化问题,贝叶斯优化适合处理目标函数计算成本高或求导困难的情况。贝叶斯优化最常用的场景是超参搜索(尤其是神经网络类算法,计算成本高,超参数还多)
贝叶斯优化(Bayesian Optimization,BO)
目的是要找到一组最优的超参组合x,能使评价/目标函数f(x)达到全局最优
由于评价/目标函数f(x)计算成
常见读取函数:
| 函数名称 | 简单描述 |
| ---------------- | ------------------------------------------------------------- |
| read_csv | 从文件、URL、文件型对象中加载带分隔符的数据,默认分隔符为逗号 |
| read_fwf |