异质性干预效应
定义外生变量为 $X$,干预变量为 $T$,评估异质性干预效应的公式如下: $$ \underset{T}{argmax} \ E[Y|X, T] $$
- 举例来说,$Y$ 可以是每日销售额,$X$ 是背景特征(无法控制的外生变量,比如前几天的平均销售额),而 $T$ 是可以提高销售额的干预变量(比如价格调整、库存水平或营销策略)
- 通过背景特征 $X$ 来定义个体类型,从而实现干预的异质化,即找到针对个体的最佳干预方式
线性回归示例
估计条件平均干预效应(CATE),以
定义外生变量为 $X$,干预变量为 $T$,评估异质性干预效应的公式如下: $$ \underset{T}{argmax} \ E[Y|X, T] $$
估计条件平均干预效应(CATE),以
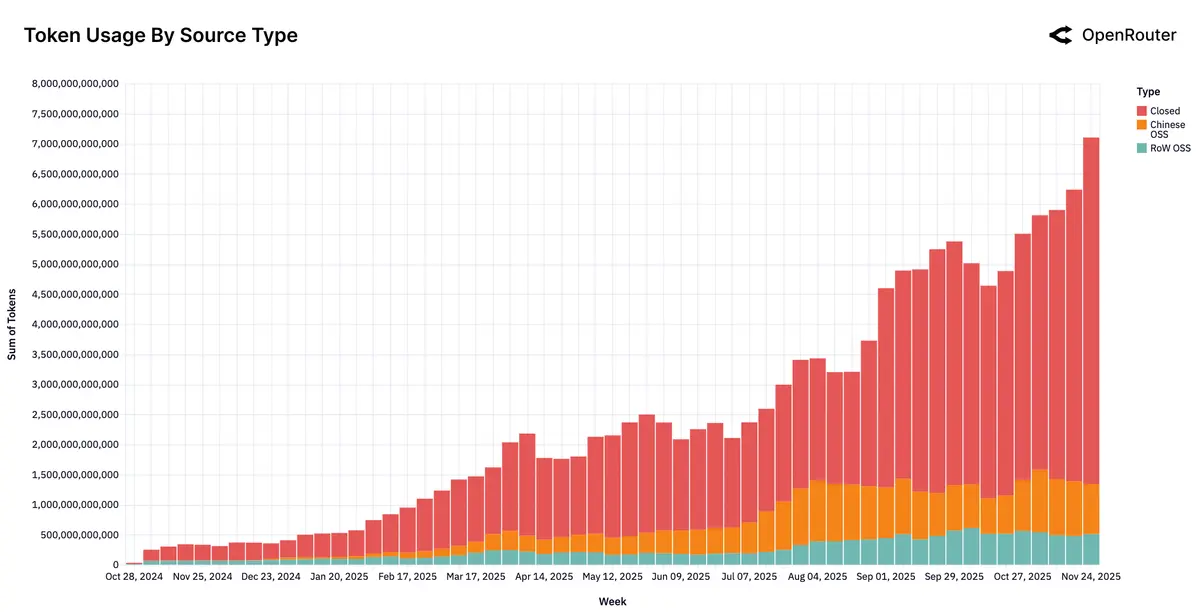
OpenRouter 作为流行大模型 API 路由平台
本文内容主要参考自:基于 OpenRouter 百万亿 token 消耗的 AI 现状研究报告
开源模型与闭源模型的绝对市场占比:
因果效应评估之配平法
配平法的常见算法:回归调整、倾向得分匹配、熵平衡、双重稳健估计
虚拟回归(Regression for Dummies)
缺点:建模能力弱,只能捕捉到变量之间的线性关系
异方
生存分析(Survival analysis),也称失效分析
起始事件和失效事件是相对应,并且可应用于不
相关资源:FreshRSS 用户手册、FreshRSS 官方文档、插件汇总
/var/www/FreshRSS/data,该路径映射的外部路径为:/var/lib/docker/volumes/freshrss_data/_datadata 文件夹;FreshRSS 的全局配置文件是 data/config.php;假设用户名称为 qwq,则用户配置文件是 data/users/qwq/co增强语言模型(Augmented Language Models,ALM)
按照模型增强的方式可大致分为:检索增强、编程增强、工具增强、综合增强
编程增强: