ES简介
Elasticsearch 是一款开源的全文搜索与分析引擎,它拥有高扩展、大容量数据的存储和处理特性,有着近乎实时的处理效果。elasticsearch 的使用场景还是比较多的,比如 APP 的搜索服务、ELK 实现日志收集与分析、BI 商业智能等。
优势
- 分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
- 近乎实时分析的分布式搜索引擎。
- 分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
- 负载再平衡和路由在大多数情况下自动完成。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据(官网是这么说的)。也可以运行在单台PC上(已测试)。
- 支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
基本概念
近实时 NRT
近实时(Near Realtime,NRT):一个文档从被索引(存储使文档可搜索)到真正能被搜索之间有一个短暂的延迟,而非实时,这个延迟默认是 1 秒。当然,默认延迟可以修改的。
集群 Cluster
集群是节点的集合。
集群实现了在多节点上进行大容量数据存储和搜索的能力。每个集群都拥有唯一名称,而节点正是根据集群的名称决定是否加入某个集群。不同环境的集群的名称不能相同,如开发、测试、线上三套环境,集群可分别命名为 logging-dev、logging-test、logging-prod。
节点 Node
节点,集群组成的一部分,负责具体的事务处理,比如数据存储、文档索引、搜索执行等。节点也有唯一个名称,如果没有指定将随机生成。
节点可通过配置集群名称,指定加入哪个集群,节点默认的集群名称是 elasticsearch。如果我们在一个网络环境下启动多个节点,并且它们之间可以相互发现,就将会自动组织一个名称为 elasticsearch 的集群。
分片 Shard
ES 的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。降低单服务器的压力,构成分布式搜索,提高整体检索的效率(分片数的最优值与硬件参数和数据量大小有关)。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
副本 Replica
副本是一个分片的精确复制,每个分片可以有零个或多个副本。副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
一句话简述,每个索引可以由多个分片组成,而每个分片也可以拥有多个副本。
数据架构
索引 Index
索引是一系列相似文档的集合,例如,我们把客户信息存放到一个索引,订单信息存储到另一个索引中。索引可通过名称识别,名称必须小写。当操作文档时,我们需要通过索引名称指定。
索引的数量,集群中并没有限制定义索引的数量。
类型 Type
类型是索引内部的逻辑分区(category/partition)。 类型将在Elasticsearch 7.0.0中的API中弃用,并在8.0.0中完全删除。
文档 Document
文档是被索引的基础信息单元,比如一个客户、一件产品、或是一笔订单。
文档基于JSON格式进行表示,由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。索引中,我们可以存放任意数量的文档。
映射 Mapping
映射是定义文档及其包含的字段如何存储和索引的过程。
例如,使用映射来定义:
- 哪些字符串字段应该被视为全文字段。
- 哪些字段包含数字、日期或地理位置。
- 文档中所有字段的值是否应该被索引到
catch-all _all字段中。 - 日期值的格式。
- 用于控制动态添加字段的映射的自定义规则。
每个索引都有一个映射类型,它决定了文档的索引方式。
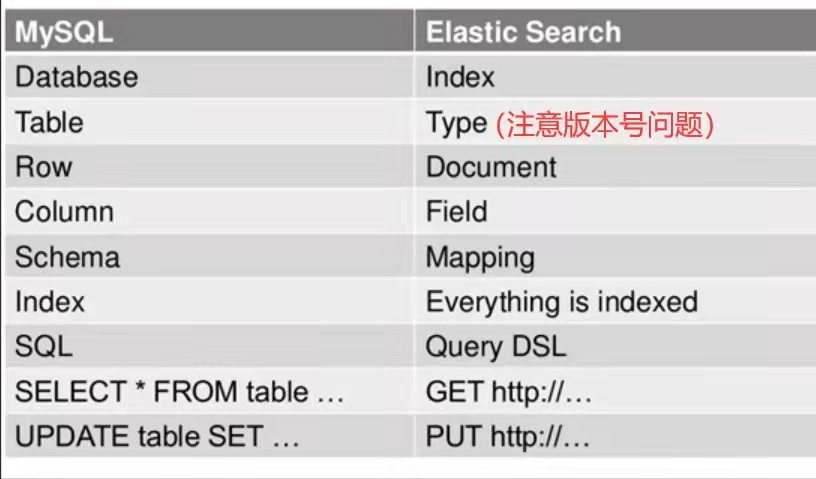
横向对比
ElasticSearch VS MySQL
1 参考
官方文档 Getting Started Elasticsearch 快速开始 ElasticSearch系列02:ES基础概念详解 ElasticSearch系列03:ES的数据类型