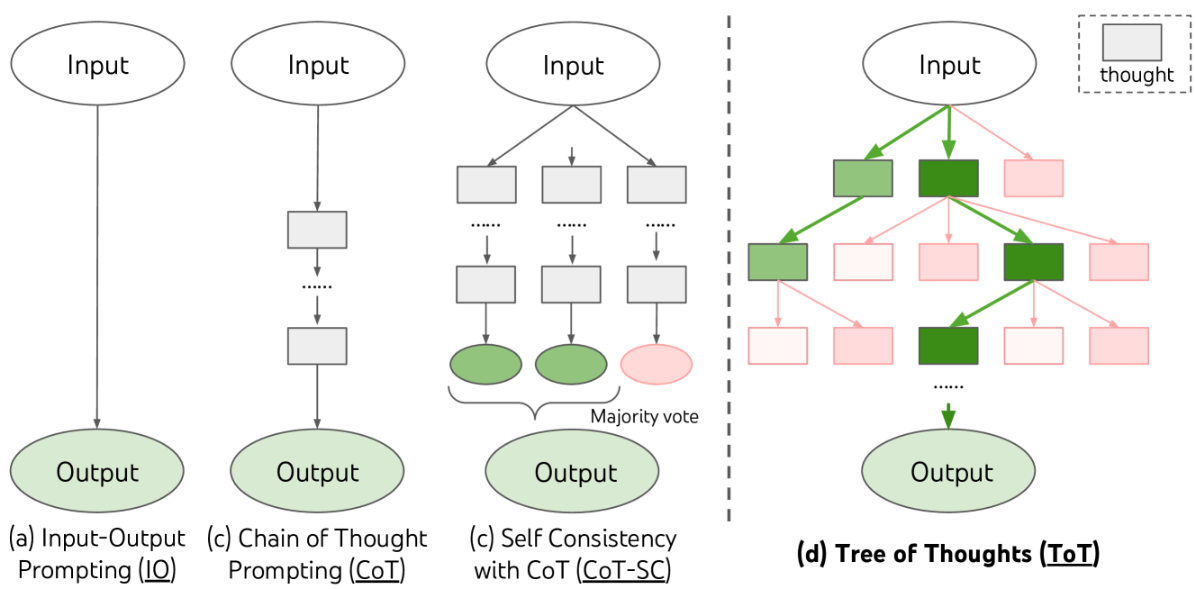
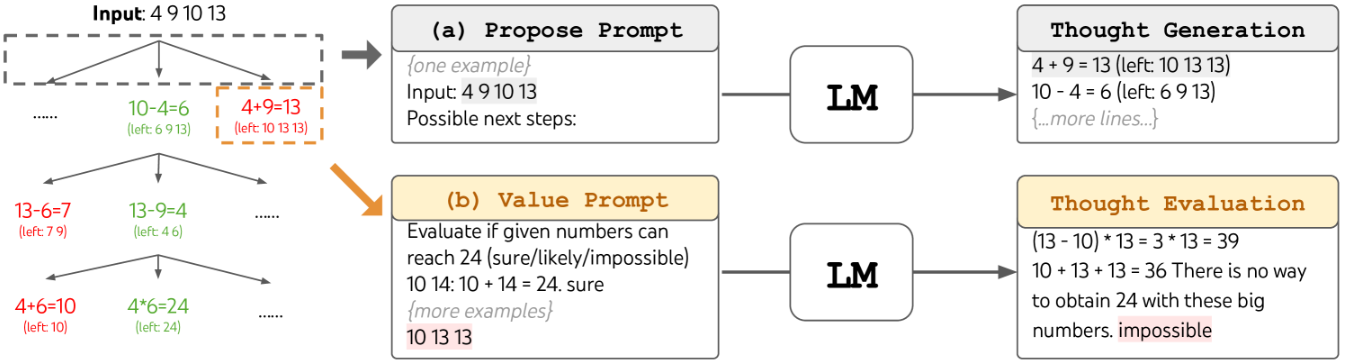
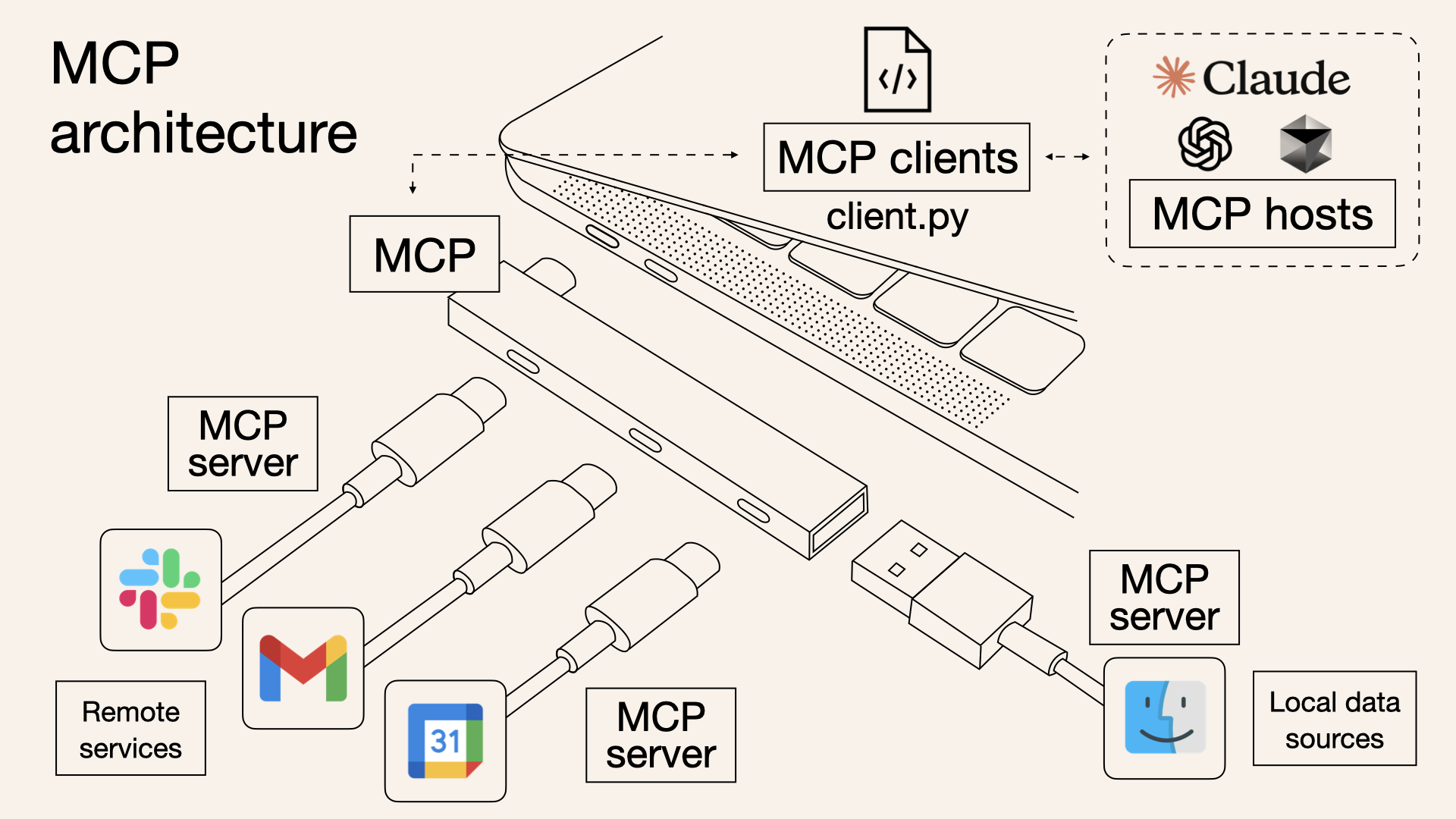
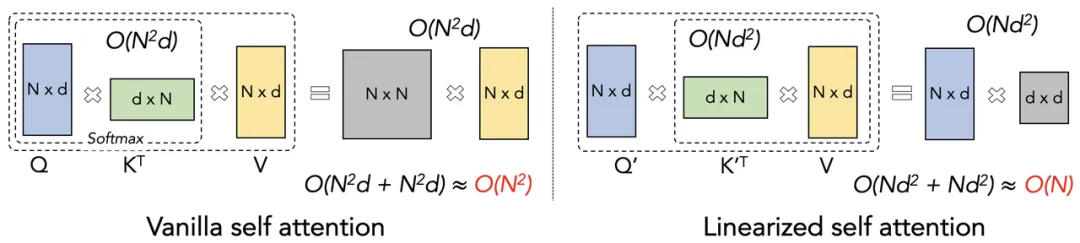
增强语言模型(Augmented Language Models,ALM)
- ALM 指 LLM 使用各种非参数的外部模块/工具,来扩展上下文处理能力
- LLM 在事实确认、信息更新、算术推理和程序编译等方面存在客观局限性
- LLM 可以通过提示、微调、强化学习等方式优化,来更好地利用外部工具
- ALM 常用外部工具:搜索引擎、浏览器、编程工具、其他模型、智能硬件
按照模型增强的方式可大致分为:检索增强、编程增强、工具增强、综合增强
编程增强:
- 直接利用 LLM 来生成包含文本和 Python 代码的混合输出
- 代码交给 Python 解释