TabPFN 的主要特点:
- 一种面向小规模表格数据(样本量<=10000)的预训练 Transformer 模型
- 不同与以往基于 X 预测 Y 的传统模型,TabPFN 更类似于 AutoML 或者元学习的思路,其先基于真实数据进行大量的合成和采样来生成数据,之后再通过对部分 label 的掩码操作进行预测训练,试图找到一种最优的算法模式来模拟数据的采样合成过程,从而实现对后验预测概率分布的直接近似
- 与传统机器学习不同,TabPFN 的每个训练"样本"是一个数据集,而不是数据集中的某一行
- 在预训练过程中,TabPFN 综合考虑了贝叶斯神经网络(Bayesian Neural Networks, BNNs)和结构因果模型(Structural Causal Models, SCMs)的先验,分别用于捕获表格数据中复杂的特征依赖和潜在的因果机制
- 最终 TabPFN 在小规模表格数据中展现出了出色的泛化能力,以及超越传统树模型的预测性能,同时模型在推理效率上也实现了较大提升
1 TabPFN 算法原理
前置知识:贝叶斯算法、贝叶斯神经网络 BNN
1.1 先验数据拟合网络 PFNs
首先,给出后验预测分布(Posterior Predictive Distribution,PPD)的定义: $$\begin{array}{c}{{p(y|x,D)=\displaystyle\int_{\Phi}p(y|x,\phi)p(\phi|D)d\phi}} \\ {{\propto\displaystyle\int_{\Phi}p(y|x,\phi)p(D|\phi)p(\phi)d\phi}}\end{array}$$
- PPD 是指在已知历史数据 $D$ 和算法模式 $\phi$ 时,对新数据 $x$ 的后验预测分布
- 算法模式 $\phi \in \Phi$ 表示一种采样合成策略,用于从一个数据集中采样合成来生成新数据
- $p(y|x,\phi)$ 表示似然估计函数,即给定输入 $x$ 和算法模式 $\phi$ 时,输出 $y$ 的概率
- $p(\phi|D)$ 表示模型根据历史数据 $D$ 推断出算法模式为 $\phi$ 的后验概率
- $p(D|\phi)$ 表示当算法模式/采样合成策略为 $\phi$ 时,生成历史数据 $D$ 的概率
- $p(\phi)$ 表示算法模式 $\phi$ 的先验分布,反映了采样合成策略的固有知识和规则
公式理解:先遍历所有可能的算法模式,然后根据历史数据 $D$ 分析不同算法模式的后验概率 $p(\phi|D)$,并以此为权重对不同算法模式下的预测分布 $p(y|x,\phi)$ 进行求和,得到最终的后验预测分布(PDD)
先验数据拟合网络 PFNs 的损失函数定义: $$\begin{align*} \ell_{\theta} &= \mathbb{E}_{D \cup x, y \sim p(\mathcal{D})}[-\log q_{\theta}(y | x, D)] \quad &(1) \\ &= -\int_{D, x, y} p(x, y, D) \log q_{\theta}(y | x, D) \quad &(2) \\ &= -\int_{D, x} p(x, D) \int_{y} p(y | x, D) \log q_{\theta}(y | x, D) \quad &(3) \\ &= \int_{D, x} p(x, D) \mathrm{H}\left(p(\cdot | x, D), q_{\theta}(\cdot | x, D)\right) \quad &(4) \\ &= \mathbb{E}_{x, D \sim p(\mathcal{D})}[\mathrm{H}\left(p(\cdot | x, D), q_{\theta}(\cdot | x, D)\right)] \quad &(5) \end{align*}$$
- (1)$l_{\theta}$ 表示模型 $q_{\theta}$ 在给定训练集 $D$ 和新输入 $x$ 的情况下对预测值 $y$ 的负对数似然的期望,其中 $D \cup x, y$ 表示 $|D|+1$ 个来自同一个算法模式的合成数据
- (2)将期望展开为积分形式,其中 $p(x, y, D)$ 是数据的联合分布
- (3)利用条件概率的性质,将联合分布分解为 $p(x,D)$ 和 $p(y|x,D)$
- (4)根据交叉熵的定义,将内层积分进一步转化为交叉熵的形式
- (5)将积分形式重新写为期望形式,其中 $p(\cdot | x, D)$ 恰好为 PDD 的定义
损失函数理解 1:用负对数似然的期望作为 $l_{\theta}$ ,其思路等价于最大似然估计
损失函数理解 2:$\ell_{\theta}$ 实际上是 PDD 与模型输出分布之间的交叉熵,因此 PFNs 模型的训练过程,其本质就是在实现对后验预测概率分布 PDD 的直接近似
损失函数理解 3:$\ell_{\theta}$ 实际上还是 PDD 与模型输出分布之间的 KL 散度(加上一个常数项),推导和证明过程略(具体细节可参阅原论文的附录 A)
先验数据拟合网络 PFNs 的其他细节补充:
- 训练机制:给定一个先验分布为 $p$ 的数据集,大量采样并合成数据集并随机掩码其中的一个 $x$ 的 label,然后计算预测值 $y$ 的负对数似然的期望($l_{\theta}$ ),并借此使用梯度随机下降法来更新 PFNs 模型的参数 $\theta$
- 模型结构:输入为可变长度的序列特征,其中包含 label 被掩住的样本;所有输入经过一个简单的线性投影后,输入到由 12 层的双向 Transformer 构成的注意力模块;其中行内注意力用于捕捉样本内部不同特征之间的关联,列间注意力用于学习同一特征在不同样本之间的模式;剔除了位置编码,以保持数据集的排列不变性
- 模型推理:将需要预测的无标签数据掺入带有标签的数据集,并输入到 PFNs 中,PFNs 会有专门的预测头给出无标签数据的预测结果,目的是追求数据集的整体预测分布与 PDD 的差异最小
- 处理分类任务:对于二分类问题使用 sigmoid 作为预测头;对于多分类问题使用 softmax 作为预测头
- 处理回归任务:利用黎曼分布(一种看起来像条形图的离散连续分布)来对输出进行离散化处理,再将每个条形替换为适当缩放的半正态分布(该过程可以简单理解为将回归任务转化为多个分类任务来处理)
- 实验效果:对于不同超参设置的高斯过程或贝叶斯神经网络,PFNs 模型能根据其合成数据集实现 PDD 的快速近似;在小规模表格数据上,PFNs 模型表现出超过 XGBoost 等 baseline 的性能,以及极强的稳定性和少样本学习能力
PFNs 通过对 PDD 进行建模和近似,实现了以贝叶斯的方式解决有监督学习问题
PFNs 的优点是保持了 Transformer 强大的上下文学习(in-context learning)能力
1.2 从 PFNs 到 TabPFN
前置知识:结构因果模型
PFNs 模型选择基于贝叶斯神经网络(BNN)的先验,而 TabPFN 则在此基础上,扩展了基于结构因果模型(SCMs)的先验,而 PFNs 的一个关键优势,就是能通过贝叶斯的方式组合不同超参数或不同类型下的先验,既处理了超参数的不确定性,也可以融合了不同类型先验的优势
TabPFN 的构建过程保持奥卡姆剃刀的原则,即用尽量少的超参数与因果关系来进行建模
基于 SCM 和 BNN 创建 TabPFN 先验:
- 首先需要定义一个随机采样的 SCM,包括 DAG 结构(因果图)和确定性函数 $f$;每个SCM 可以由一组结构方程 $Z:=({z_{1},..,z_{}})$ 组成,其中 $z_{i}$ 的公式定义如下:
$$z_{i}=f_{i}(z_{{\mathrm{PA}}(i)},\epsilon_{i})$$
- 其中 $PA(i)$ 表示因果图中节点 $i$ 的父节点集合,$\epsilon_{i}$ 是噪音变量
- $z_{i}$ 是一个从原因指向结果的有向边表示,也分配到因果图中的一个节点
- 给定一个 SCM 后,在因果图中采样一组节点 $Z_{X}$ ,其中的每个节点都会是合成数据集的一个特征;在因果图中采样一个节点 $Z_{y}$,作为合成数据集的一个预测目标;需要注意的是,目标 $Z_{y}$ 既可能是特征 $Z_{X}$ 的原因,也可能是结果;采样 $n$ 次后,得到完整的合成数据集
- 通过选择不同的 DAG、确定性函数和噪声分布,产生了大量的采样合成数据集,这些数据集构成了基于 SCM 的 TabPFN 先验;基于 BNN 的先验同理可得,只是采样策略是选择不同的网络架构(层数、激活函数)、权重分布(高斯分布)和其他超参数(Dropout 等)
- SCM 先验和 BNN 先验的混合方式很简单,就是在 TabPFN 训练期间,以相等概率的方式从其中一个先验中随机采样合成的数据集( TabPFN 自行融会贯通,兼备两家之长)
TabPFN 的其他细节补充:
- 一个 12 层的 Transformer,训练过程包括由 512 个合成数据集组成的 18,000 个批次;一台配备 8 个 RTX 2080 Ti 的 GPU 机器上训练,总共需要 20 个小时
- TabPFN 的先验主要返回标量标签,需要进一步的离散化处理,才能适用于分类任务
- TabPFN 的运行时间和内存占用与输入数据集的尺寸正相关 $O(n^2)$,不适用于样本量大于 1w 的情况
2 TabPFN 的实验分析
TabPFN 的测试评估
- 在开源 OpenML-CC18 数据集在筛选出 30 份数据集(样本量≤2000,特征≤100,类别≤10)
- 其中 18 份数据仅包含数值特征且不含缺失值,TabPFN 在此数据集上的整体准确性和训练速度均超越其他模型(包括 KNN、逻辑回归、XGBoost、LightGBM、CatBoost);而另外12 份数据包含类别型特征或缺失值,TabPFN 在此数据集上表现整体相对较差(与传统机器学习方法持平)
- TabPFN 在 OpenML-AutoML 外部小型数据集上的基准测试也表现出类似的结论
TabPFN 只是整体最优,在部分数据集和任务上依然可能不如传统机器学习的表现
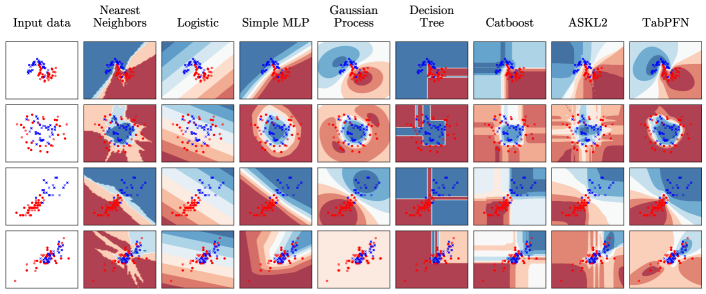
不同算法在 scikit-learn 1_study/Python/Module-sklearn-机器学习/skleran 内置数据集#1 玩具数据集上的决策边界:
模型的特征鲁棒性分析:
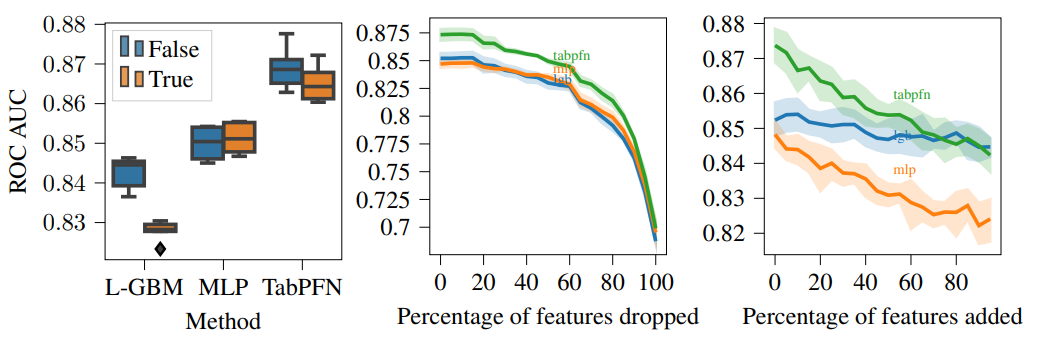
- 左:对特征空间随机旋转时,LightGBM 性能下降最明显,MLP 不受影响,其次是 TabPFN
- 中:按照特征重要性依次弃置,TabPFN 的前期表现最佳,其次是 MLP,后期模型表现趋于一致
- 右:随机添加无意义的特征,TabPFN 和 MLP 会受到影响,而 LightGBM 的性能则相对稳定
不同先验的消融实验对比(SCM 比 BNN 更有效):
| BNN | SCM | SCM + BNN | |
|---|---|---|---|
| Mean CE | 0.811±0.009 | 0.771±0.006 | 0.776±0.009 |
| Mean ROC AUC | 0.865±0.007 | 0.881±0.002 | 0.883±0.003 |
3 TabPFN 的后续发展
3.1 TabForest:TabPFN 融合决策树先验
TabForest 模型 - TabPFN 在森林数据集上的微调

- 构建森林数据集生成器:通过改变决策树的参数生成简单的决策树,再利用随机生成的特征和目标来过度拟合决策树,最后用拟合后的决策树创建高度复杂的合成数据集
- 数据预处理:保持与原始 TabPFN 类似的处理过程,使用分位数变换(
QuantileTransformer)在转换数据以服从正态分布的同时,增强模型对偏斜和异常值的鲁棒性 - 模型架构:模型输入特征固定为 100 维(少于 100 则进行零值填充),整体架构与原始 TabPFN 保持一致( 12 层、4 个注意力头、512 的隐藏维度),输出维度固定为 10
- 模型微调:用合成的森林数据集对 TabPFN 进行微调,划分验证集和测试集对微调模型进行严格监督,在验证损失增加立即停止微调(特别小的数据集很容易过拟合),避免损耗模型的零样本性能
TabForest 模型的表现(2024 年 5 月 22 日):
- TabForest 的零样本性能与 TabPFN 相比明显不足
- TabForest 在特定真实数据集上的微调性能超过了 TabPFN
- 经过微调后的 TabForest 模型能够创建出复杂的决策边界
3.2 TabPFNv2 :时隔两年的版本升级
主要升级点(2025 年 1 月 8 日发表在《nature》):
- 改进了分类能力,扩展以支持回归任务(性能也很好)
- 原生支持缺失值和异常值,对数据集的处理更高效准确
- 借助 flash attention,优化训练和推理时的内存和计算需求
- 适用于处理不超过1w 样本和 500 特征的中小规模数据集
基于 SCMs 的先验(数据集采样合成策略):
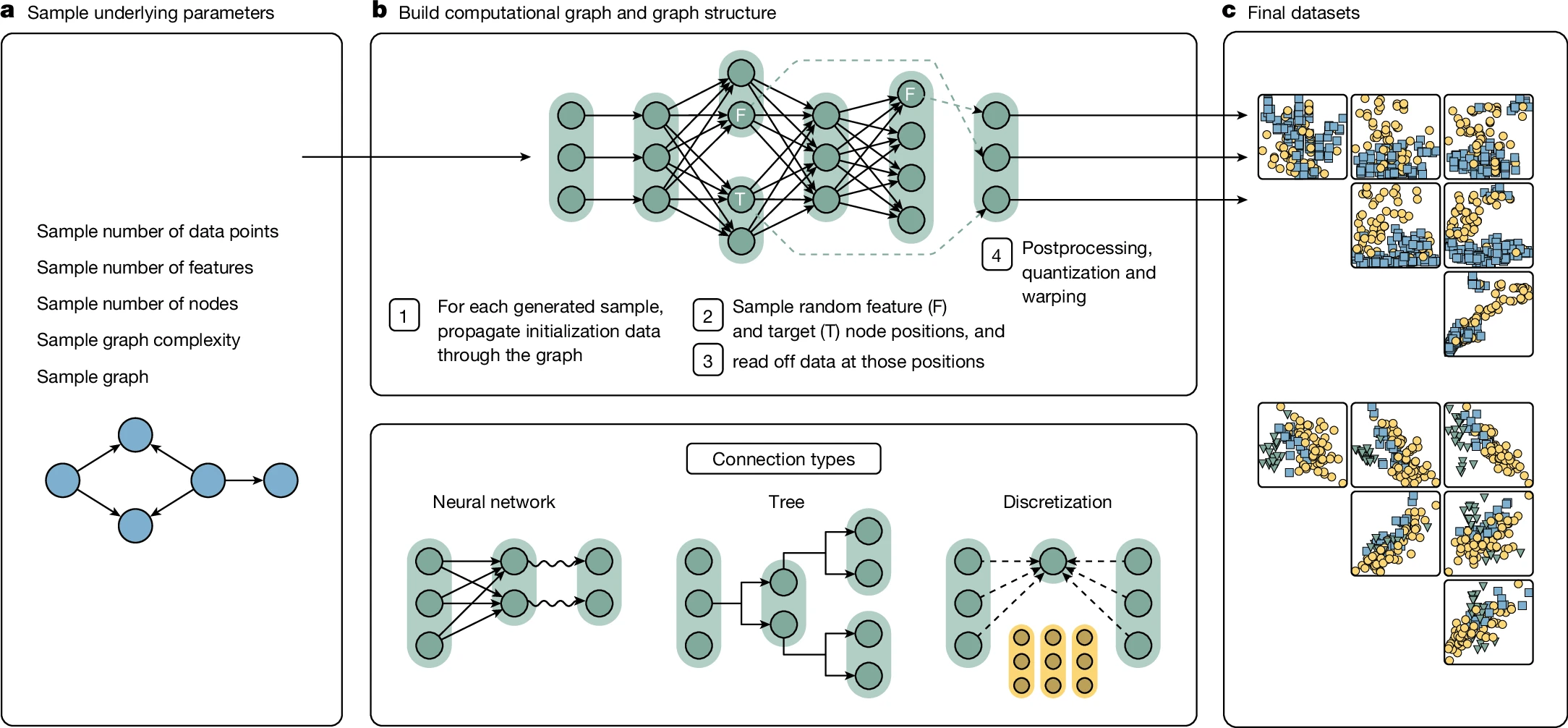
- (a)采样高级超参数,比如样本量、特征数、节点数、DAG 复杂度
- (b 上)构建结构因果模型 SCMs,主要分 4 步:(1)利用随机噪声初始化图的根节点的对应向量(2)随机采样节点,分别作为特征节点 F 和目标节点 T(3)根节点向量根据计算图传播到其他节点,计算出每个节点的数据表示(4)数据后处理,比如离散化或仿射变换
- (b 下)在 SCMs 中每个节点包含一个向量,每个边对应计算函数,每条边还会添加噪声来为数据合成引入不确定性;计算函数主要分 3 类:(1)具有不同激活(sigmoid、ReLU、取模、正弦)的小型神经网络,用于线性或非线性拟合(2)离散化处理,用于生成类别型特征(3)决策树,用于编码基于规则的局部依赖关系
- (c)对最终的采样合成数据集进行可视化,颜色表示不同的 label
TabPFNv2 放弃了历史版本中的 BNN 先验,只保留了更灵活有效的 SCM 先验
TabPFNv2 使用约 1.3 亿合成数据集,在 8 个 RTX2080TI GPU 上训练了 2 周
实验分析与评价 1:TabPFN 的性能表现
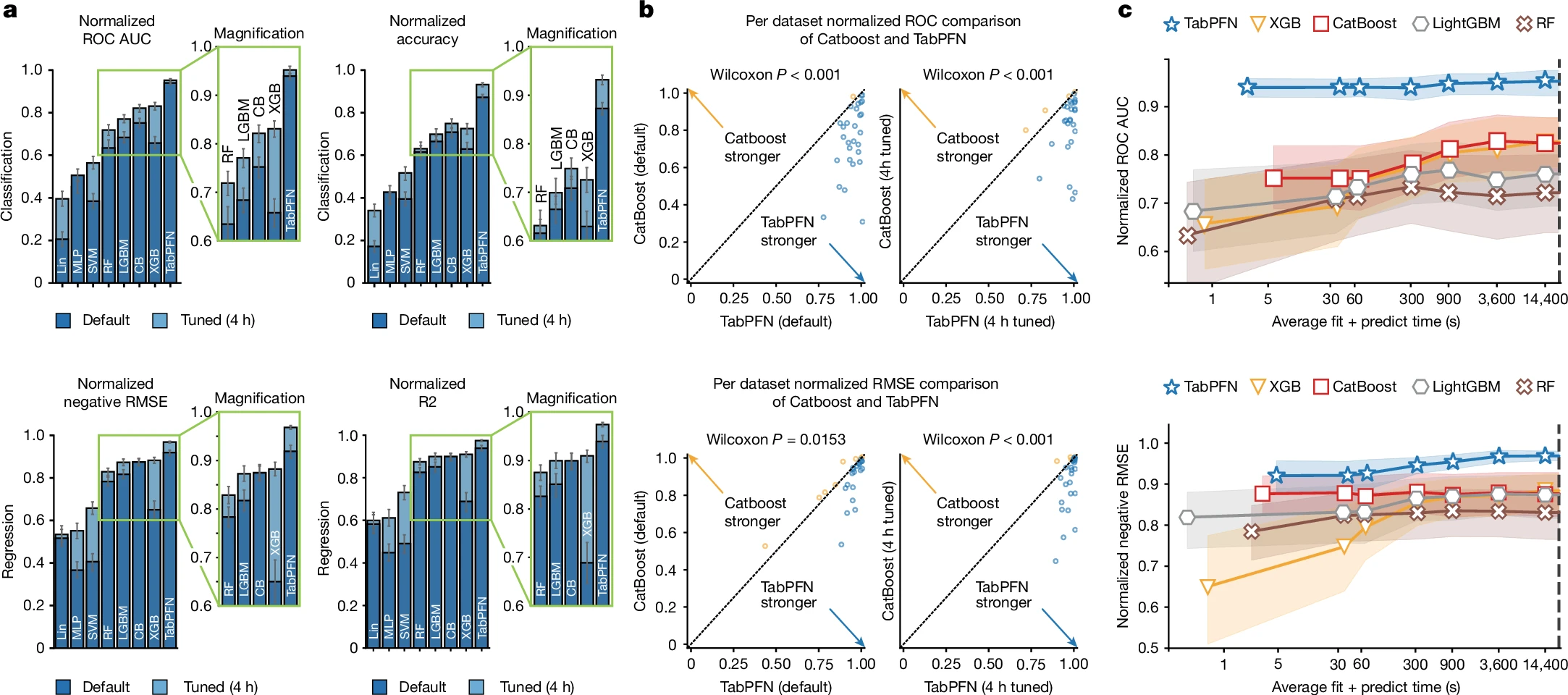
- (a)TabPFN 在分类和回归任务中,表现均显著优于传统的机器学习模型
- (b)在绝大部分的数据集中,TabPFN 均优于最强的基线模型 Catboost
- (c)随着超参调整导致的训练推理预测时间增长,TabPFN 依然性能表现最强
实验分析与评价 2:TabPFN 的可解释性与迁移性

- TabPFN 可以用于数据的密度估计(a)和新样本的合成(b)
- (c)TabPFN 所学到的嵌入表示具备更好的可区分度(在 PCA 可视化中)
- (d)使用不同类型的正弦数据集微调后,TabPFN 对正弦数据实现了更准确的预测
3.3 TabPFN-TS:TabPFN 时序预测变体
TabPFN-TS(2025 年 1 月 9 日) 是 TabPFN 的变体,可应用于时间序列预测
TabPFN-TS 模型中 GIFT-EVAL 时序模型基准测试 Top1(250227)
核心思想:将时间序列预测视为一种表格回归任务
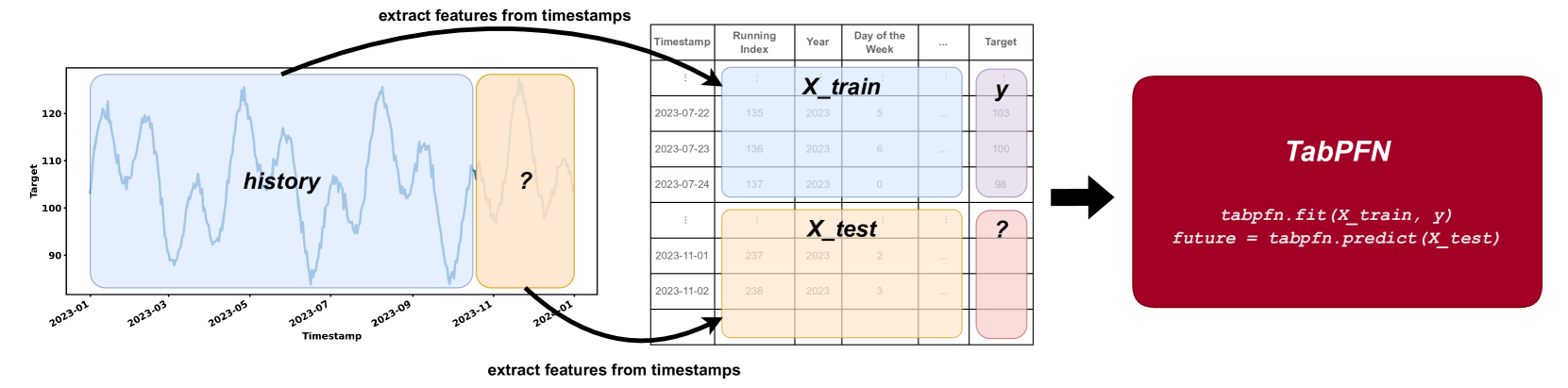
- 每个时间序列被视为一个独立的表格,根据时间戳划分训练集和测试集
- 表格回归任务则使用历史信息/训练数据来生成多步预测,即未来的目标值
- TabPFN-TS 还需要适当的特征工程(周期/日历/步长等)来捕获时间关系
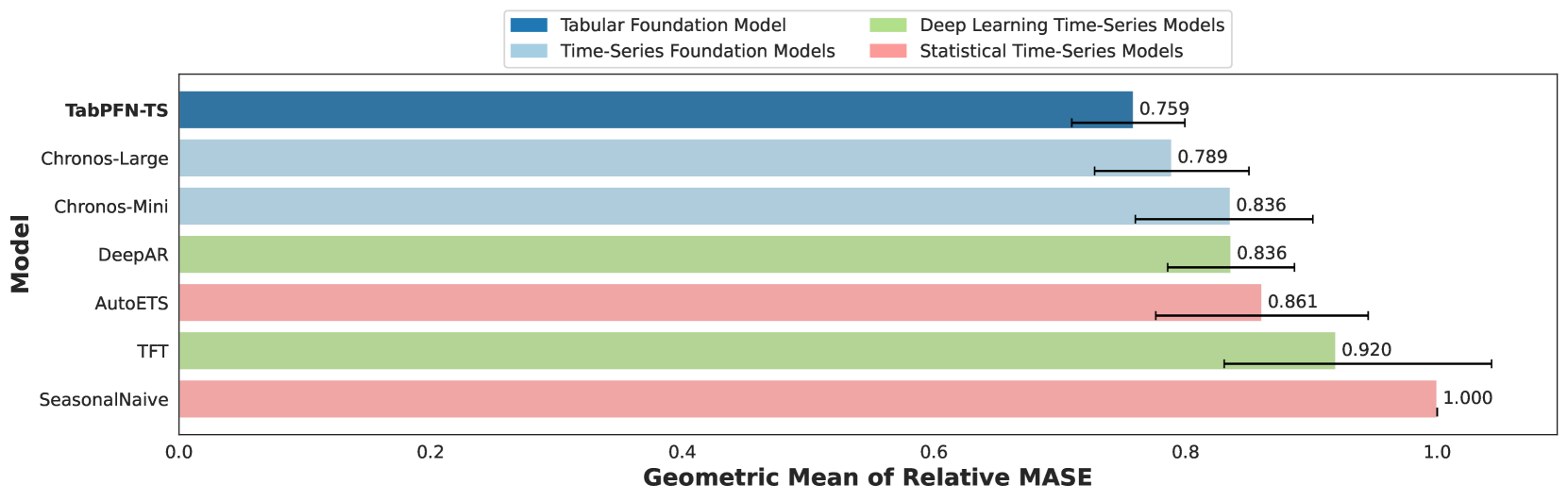
实验结果:TabPFN-TS 的模型表现远高于其他模型
4 补充资料与实践工具
参考文献:
TabPFN: 预训练表格基础模型
PFN: Transformers Can Do Bayesian Inference
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
TabForest: Fine-tuned In-Context Learning Transformers are Excellent Tabular Data Classifiers
TABPFNv2: Accurate predictions on small data with a tabular foundation model
TabPFN-TS: The Tabular Foundation Model TabPFN Outperforms Specialized Time Series Forecasting Models Based on Simple Features