BNN 的定义
贝叶斯神经网络(Bayesian neural networks, BNNs):
- 神经网络中的可训练参数,即权重(weight)和偏置(bias)都表示为一个分布
- 一种最简单的 BNN 就是将模型参数看作服从均值为 $\mu$,方差为 $\delta$ 的高斯分布;考虑到中心极限定理的存在,一般认为模型参数符合高斯分布是一种合理的假设
- 在预测时,BNN 会从每个高斯分布采样,得到一个确定的神经网络,然后用于预测;也可以对参数多次采样后分别进行预测,然后将多次预测结果进行汇总(类似于集成算法);还可以直接计算出预测结果分布的均值和方差,并进行采样(局部重参数化,local reparameterization)
- 在训练时,为了确保方差 $\delta$ 大于 0,一般用 $\rho$ 进行替代:$\delta_{i}=\log(1+e^{\rho_{i}})$
- 一般认为,BNN 需要信息丰富的先验才能处理不确定性,即要求数据集的样本量至少与模型参数量保持相同的量级,BNN 模型才能有较好的效果
注意区分贝叶斯神经网络和贝叶斯网络,贝叶斯网络是一种概率图模型,又称信念网络(belief network)或是有向无环图模型
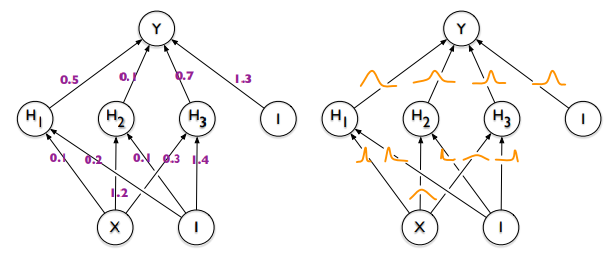
普通神经网络 VS 贝叶斯神经网络(图源):
BNN 的变分学习
前置知识:
- 变分(variational)问题:给定一个泛函 $J[y]$,变分问题的目标是找到一个函数 $y(x)$,使得 $J[y]$ 最小化或最大化,即从可能的函数集合中寻找一个满足条件的最佳函数
- 变分推断(Variational Inference):在贝叶斯推断中,由于计算后验分布往往是困难的,因此常需要通过一些近似概率分布的技术将后验分近似为一个更简单的分布
给定一个训练集 $D= {({x}_1, y_1), ({x}_2, y_2),..., ({x}_m, y_m)}$,用于训练一个贝叶斯神经网络,则贝叶斯公式可以写为如下形式: $$ p(w|{x}, y) = \frac{p(y|{x}, w)p(w)}{\int p(y|{x}, w)p(w) dw} $$
- 先验概率 $p(w)$ 是已知的,即模型参数预设所服从的分布
- 确定模型参数 $w$ 的取值后,似然估计值 $p(y|x,w)$ 也很容易计算
- 难点在于分母需要遍历参数 $w$ 的所有可能取值,并计算后验概率
BNN 模型的常见训练方法
- MCMC(Markov Chains Monte Carlo) :基于随机游走的蒙特卡洛采样方法,实现对公式分母中积分的近似,
- 黑箱变分推断 BBVI:用一个参数化的简化分布 $q(\lambda)$ 去近似后验概率分布 $p$,模型的训练目标是最小化两个分布之间的差异(比如 KL 散度),其中的"黑箱"部分在于使用蒙特卡洛方法来估计 $\lambda$ 的梯度,而不依赖具体的模型形式
- MC dropout 利用随机的 Dropout 对同一输入进行多次前向传播,之后基于这些采样结果实现对后验分布的近似;需要注意的是,MC Dropout 在推理阶段也需要进行
BBVI 训练时,会使用 ELBO(Evidence Lower Bound)作为目标函数指导超参数 $\lambda$ 的优化,最大化 ELBO 相当于最小化 KL 散度:$KL=logp-ELBO$
BNN 的分析总结
优点:
- 支持不确定性估计,能给出预测目标的预估概率分布/置信区间
- 不容易过拟合,权重取值的随机性起到了类似 Dropout 的作用
- 鲁棒性强,权重取值的轻微扰动不会造成模型输出的较大变化
缺点:
- 较高的计算成本和训练时长
- 训练和推理的内存需求更大,需要存储权重的分布(而不是单个值)
- 可解释性差,内部的网络结构和决策过程依然是黑盒模型
参考:
贝叶斯深度学习(bayesian deep learning)
贝叶斯神经网络 BNN (推导+代码实现)
Bayesian Neural Networks:贝叶斯神经网络