常数初始化
将参数全部初始化为相同的常数(通常为 0,也称全零初始化)
- 常见于传统 ML(比如 SVM 或逻辑回归),一般不适用于神经网络的训练
- 神经网络需要一定的随机性来打破对称性(Symmetry breaking),否则同一层的所有神经元会以相同的初始值为起点,进行相同的梯度计算和更新,从而导致模型无法学习复杂特征
随机初始化
从均值为 $\mu$ (通常为 0)和方差为 $\sigma^2$ 的分布中随机采样
- 随机初始化一般考虑正态分布 $N(0,\sigma^2
分类目录归档:模型开发技巧
将参数全部初始化为相同的常数(通常为 0,也称全零初始化)
从均值为 $\mu$ (通常为 0)和方差为 $\sigma^2$ 的分布中随机采样
最常用的10个超参数(原生API,兼容Scikit-learn的API,常见取值范围):
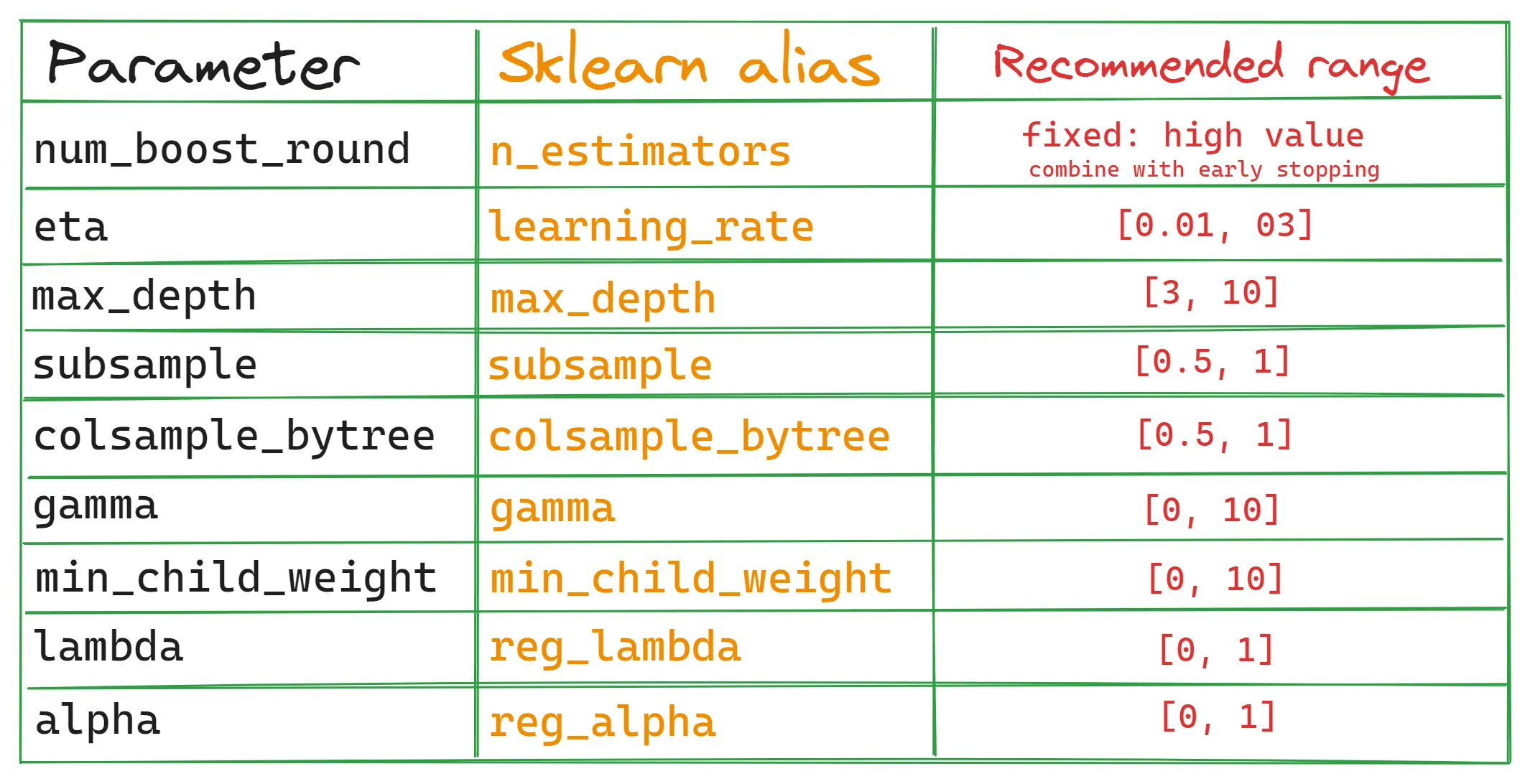
num_boost_round:训练期间所需要的基学习器数量,默认100;在应对较大数据集时,一般控制在5000~10000左右(影响训练时间的重要因素);一个常用技巧是先设定一个较高的数值,然后结合early-stop网格搜索(Grid Search)会遍历给定参数空间内的所有参数组合,并选择最优的一组,相对于暴力枚举法,有点浪费时间
随机选择(Randomized Search)参数空间内的参数组合,可能有的参数组合不会被选到,效率比网格搜索高
贝叶斯优化(Bayesian Optimization)是一种通用的黑盒优化