1 基本信息
1.1 书籍名称:《利用python进行数据分析》
1.2 撰写作者:Wes McKinney
1.3 出版日期:2022-10-19
1.4 品读时间:2023-03-24~2023-04-10
1.5 整体耗时:约15h
1.6 摘要
本
分类目录归档:数据分析
本
本章针对一些真实数据集进行处理和分析,以便复习并实践之前章节的内容
本章仅简略记录核心内容,不再展示具体代码,代码可参考本书配套Git项目-13章
短域名供应商Bitly提供的用户的网络访问信息(已脱敏数据,目前已该服务已关闭)
主要实践内容:
本章主要简单介绍了statsmodels 和 scikit-learn这两个Python建模的常用模块
先使用pandas进行数据加载和清理后,再进行建模是模型开发的一个常见工作流
一般建模工具都支持数组结构,所以经常用to_numpy方法将DataFrame转换为NumPy数组
代码示例:
data = pd.DataFrame({
'x0': [1, 2, 3, 4, 5],
'常见的三种时间格式:时间戳(timestamp),时期(period),时间间隔(interval)
pandas内置了很多处理时间序列的工具和算法
pandas也支持将时间间隔(interval)作为索引使用,只是本书未提及
除了pandas,本章还会用到datetime(用的最多)、time以及calendar这三个模块
代码示例:
from datetime import datetime
now按照指定的行列取值进行分组,并按组进行计算(求和、均值、标准差等)
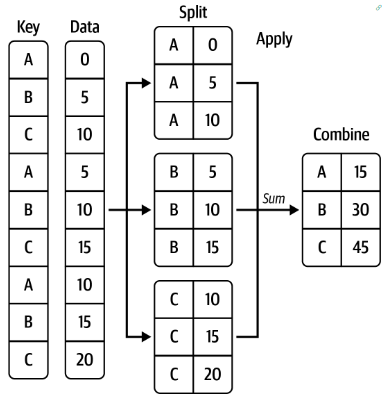
代码示例:
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'o本章主要围绕matplotlib和seaborn两个模块进行可视化的演示
matplotlib的图像都是基于Figure对象
plt.figure()可以创建一个空白的新Figureadd_subplot创建多子图,并可以依次进行绘制代码示例:
import matp常见读取函数:
| 函数名称 | 简单描述 |
| ---------------- | ------------------------------------------------------------- |
| read_csv | 从文件、URL、文件型对象中加载带分隔符的数据,默认分隔符为逗号 |
| read_fwf |
pandas是后续数据清理和分析的重要工具
pandas是基于numpy构建的,但支持异构的数据(不同于numpy,pandas中不同列的类型可以是多样化的,比如日期、数值、字符串等)。pandas的功能定位可以对标Excel,但相比于Excel会更加地灵活强大
pandas包含两个主要数据结构:Series和DataFrame
Series是一种类似于一维数组的对象,包含了列表、字典或一维numpy数组的很多特性;每个Series都是由一个名称(name)、一组index和一组values构