变点检测的定义
变点检测(Change point detection, CPD)是指在时间序列中发现统计特性发生重大变化的点
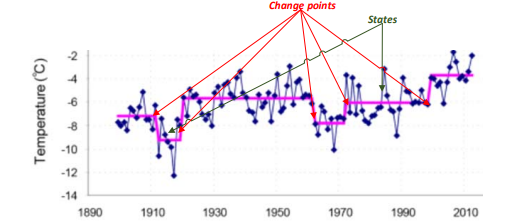
变点检测示例(斯匹次卑尔根岛的年均气温趋势):
变点检测的分类:
- 按照是否回顾整个历史数据集,分为离线检测和在线/实时检测
- 按照预测目标可以分为变点识别(分类)、变化度预测、变点时间预测
- 按照训练过程是否使用数据集标签,分为有监督方法和无监督方法
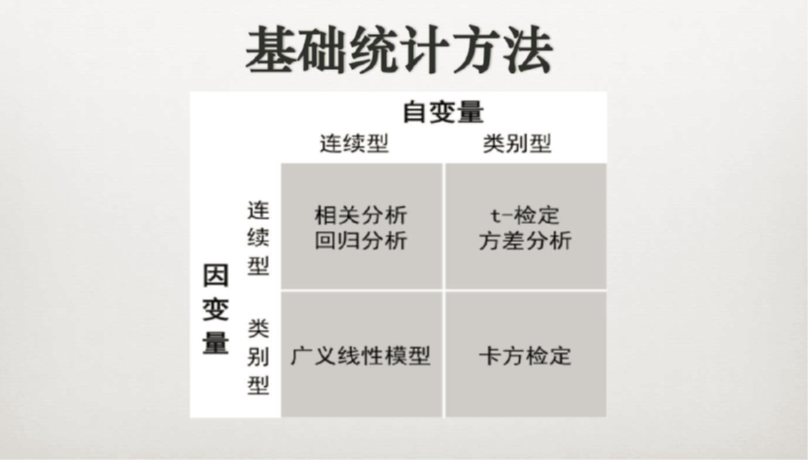
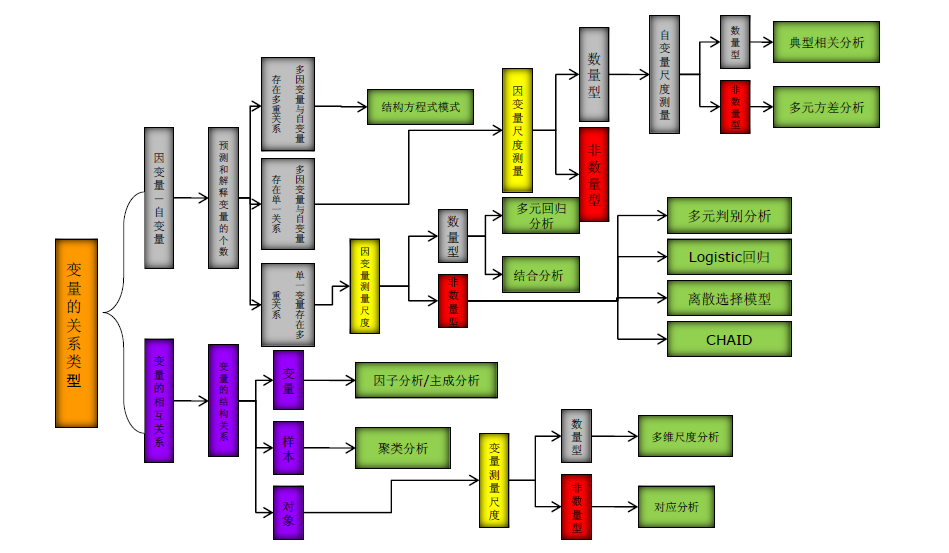
常见变点检测算法
变点检测的有监督方法:
- 常见分类器:决策树、朴素贝叶斯、贝叶斯网络、SVM、KNN、HMM、CRF 等
- 虚拟分类器:定义第一个窗口内的所有连