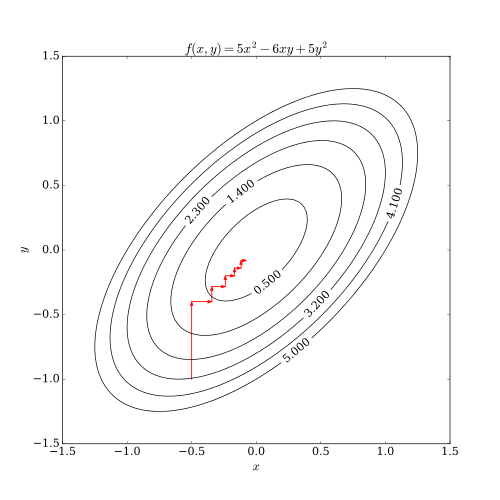
首先,理解梯度向量是指向函数值增长最快的方向的:MIT18.02笔记-梯度的定义与理解
定义函数$f(x)$,其在点$x$处沿着方向$d$的变化率可用方向导数表示,即梯度与方向的乘积: $$Df(x;d)=\nabla f(x)^Td$$ 当$d=-\frac{\nabla f(x) }{ ||\nabla f(x)|| }$时,函数$f$在点$x$处的下降速率最大,即负梯度方向为最速下降方向
最速下降算法:在迭代过程,每次都选择负梯度方向搜索(对于寻找最小值的最优化问题)
最速下降算法步骤:
- 初始化$x_1$,设定允许的最小误差$\epsilon$,迭代次数$k=1$
- 对于第$k$次迭