1 K-means算法概况
K均值算法(即,k-means clustering),是一种无监督聚类算法
K-means算法属于NP-hard问题,不过存在高效的启发式算法,能快速收敛到一个局部最优解
2 K-means算法细节
算法步骤
- 对于N个样本,随机选择其中K个,作为最初的质心
- 遍历所有样本,选择最新的质心进行归类,形成K个簇
- 根据每个簇的样本重新计算质心(比如求均值)
- 重复步骤2-3,直到每个簇质心基本不再变化或达到最大迭代次数
算法的收敛过程如下所示:
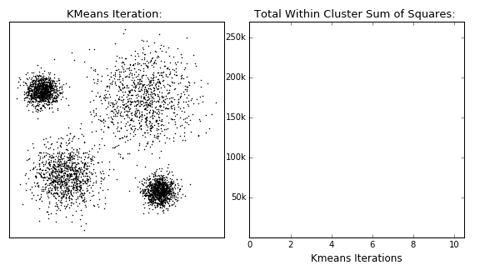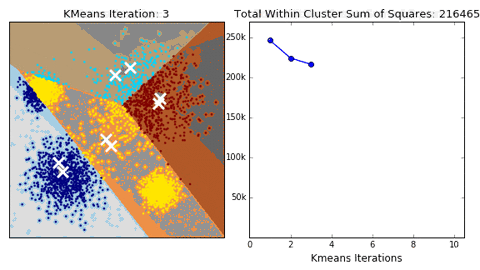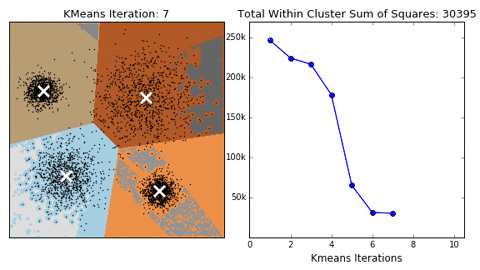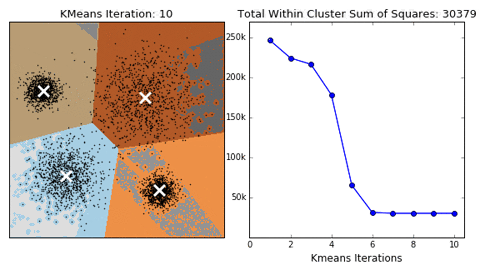 (图源来自https://giphy.com/)
(图源来自https://giphy.com/)
K值的选择:
- 先验知识:根据业务理解对 K 值或簇内最少样本数存在预期或约束,或者其他外部指标来评价
- 交叉验证:类似于有监督学习的评价,利用与分组误差/稳定性强关联的指标来评价聚类结果
- 肘部法则(Elbow):随着 K 增大,簇内平方和会单调下降;下降幅度明显变缓处的“肘部拐点”即候选 K
- 轮廓系数(Silhouette):综合簇内聚集程度和簇间分散程度来评价聚类效果的指标,值越大越好
3 K-means算法改进
问题1:质心初始化过于随机,最终结果不稳定
- 改进思路1:与前一个质心差异越大的样本越可能被选为下一个质心(K-means++)
- 改进思路2:借助其他聚类的结果初始化质心,比如层次聚类
问题2:样本量太大时候会导致过多的距离计算,性能存在优化空间
- 改进思路1:减少不必要的距离计算,比如elkan K-means(借助两边之和大于等于第三边,以及两边之差小于第三边的三角形性质,简化计算)
- 改进思路2:保持数据分布的前提下进行数据抽样,比如Mini Batch K-means
其他问题:局部最优、对异常值敏感、K值不好把握、会受到数据偏斜的影响
主要优点:原理简单、收敛较快、效果还行、调参不多、具有可解释性