GLUE(General Language Understanding Evaluation,通用语言理解评估)是一种常用的评估工具,用于评估 NLP 模型在一系列任务上的有效性。
GLUE 基准测试由纽约大学和谷歌的研究人员开发的。开发 GLUE 的动机是需要一个全面的 NLP 模型评估框架,该框架测试语言理解的不同方面并提供更完整的描述
官网为: https://gluebenchmark.com/
GLUE 共包含 3 个分类 9 个任务:
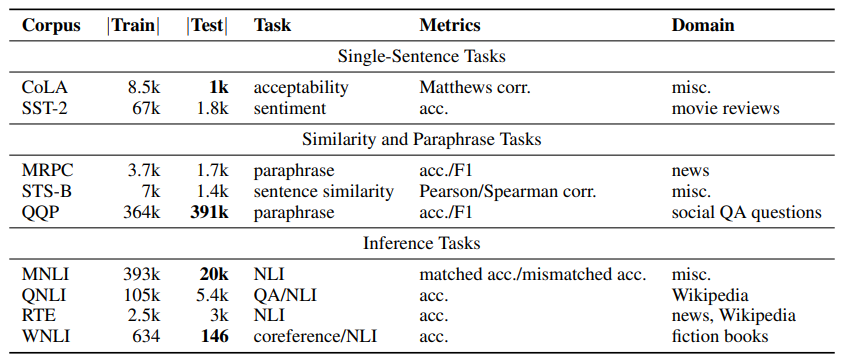
- 单句任务包括 CoLA、SST-2
- 相似性任务包括 MRPC、STS-B、QQP
- 语音理解任务包括 MNLI、QNLI、RTE、WNLI
 SWE-ben
SWE-ben