GLUE(General Language Understanding Evaluation,通用语言理解评估)是一种常用的评估工具,用于评估 NLP 模型在一系列任务上的有效性。
GLUE 基准测试由纽约大学和谷歌的研究人员开发的。开发 GLUE 的动机是需要一个全面的 NLP 模型评估框架,该框架测试语言理解的不同方面并提供更完整的描述
官网为: https://gluebenchmark.com/
GLUE 共包含 3 个分类 9 个任务:
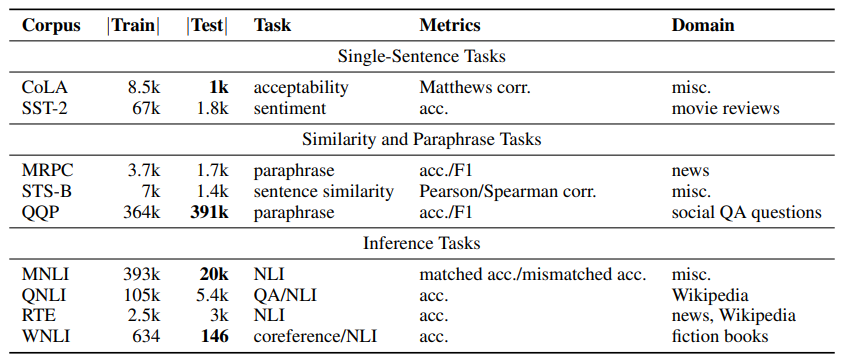
- 单句任务包括 CoLA、SST-2
- 相似性任务包括 MRPC、STS-B、QQP
- 语音理解任务包括 MNLI、QNLI、RTE、WNLI
具体的 9 种任务说明:
1.CoLA(语言可接受性语料库):CoLA 由来自23种语言学出版物的10657个句子组成,由其原作者对其可接受性(语法性)进行了专业注释。
2.SST-2(Stanford Sentiment Treebank):一个广泛用于情感分析任务的数据集,其中需要模型将句子的情感分类为正面或负面。给出的标签是二进制的。
3.MRPC(Microsoft Research Paraphrase Corpus):微软研究人员开发的一种文本蕴含任务,需要模型来确定两个句子在语义上是否等价。
4.STS-B(Semantic Textual Similarity Benchmark):衡量两个句子相似度的任务。与上面的标签是二进制的数据集不同。标签是一个从0到5的数字,0表示相似度最低,5表示相似度最高。
5.QQP(Quora Question Pairs):这个数据集由超过400,000个问题对组成,每个问题对都用二进制值注释,表明两个问题是否相互解释。
6.MNLI(多流派自然语言推理):这个语料库是433k句子对的众包集合,带有文本蕴含信息注释。该语料库以SNLI语料库为蓝本,但不同之处在于它涵盖了一系列口语和书面文本类型,并支持独特的跨类型泛化评估。
7.QNLI(Question Natural Language Inference):该数据集是从斯坦福问答数据集 v1.1(SQuAD)自动衍生的自然语言推理数据集。该任务需要模型来确定给定段落是否可以回答问题。
8.RTE(识别文本蕴含):该数据集来自一系列文本蕴含挑战。来自 RTE1、RTE2、RTE3和 RTE5的数据被合并。这是一个文本蕴含任务,需要模型来确定一个前提是否蕴含一个假设。
9.WNLI(Winograd Schema Challenge):用以理解一个含有代词的内容并判断出该代词指代的内容。