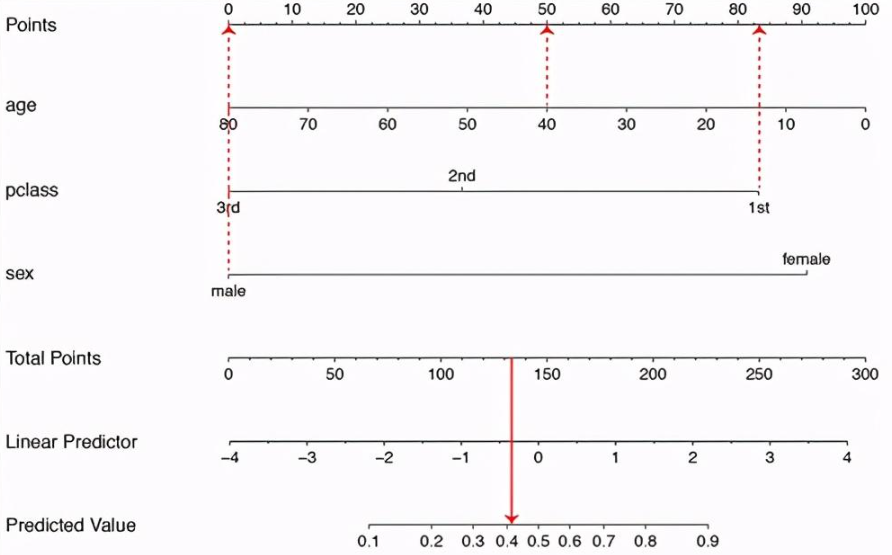
生存分析入门
生存分析(Survival analysis),也称失效分析
- 分析距离特定事件发生前的预期持续时间,例如生物体的死亡和机械系统的失效
- 起点/起始事件(initial event):反应生存时间起始特征的事件,如疾病确诊、治疗开始等。
- 结局/失效事件(failure event):研究规定的终点结局,比如患者死亡、治疗的结束等
- 生存时间,起点事件到结局事件之间所经历的时间(也可以是距离等度量方式)
- 中位生存期/半数生存期:50%个体存活的情况所对应的生存时间
起始事件和失效事件是相对应,并且可应用于不