调查问卷分析的一般流程:
- 初步设计调查问卷并严格评估合理性,比如文献研究,对象访谈,Delphi 专家函询
- 针对少量人群(40~60 人)展开预调查,了解调查问卷设置条目的合理性,完整性和可理解性
- 确保预调查结果质量,包括调查内容审核录入与信效度分析(此步骤也适用于正式调研阶段)
- 估计样本量,确定调查人群,完成调查员培训,分配调查任务并展开具体的正式调查
- 对调查结果进行数据分析,包括分布描述,独立性检验,方差分析,相关性分析,多因素分析等
- 根据初步分析结果,进行整理和深入的分析,得到可验证的结果,最后撰写调查报告
Delphi 专家函询
通过迭代的问卷调查来收集和汇总专家意见的系统化方法
一般流程:
- 确定问题和目标:研究者需要明确问题的范围和研究的具体目标。
- 选择专家:选择一组具有相关领域知识和经验的专家。专家的选择对Delphi研究的质量至关重要。
- 设计问卷:根据研究目标设计初步问卷(开放式/闭合式),旨在收集专家对问题的看法和建议。
- 第一轮调查:将问卷发送给选定的专家,收集他们的意见和建议。
- 汇总和分析意见:对第一轮调查收集到的数据进行汇总和分析,提炼出共识点和分歧点。
- 设计第二轮问卷:根据反馈设计第二轮问卷。二轮问卷通常会更加具体,可能会要求专家对某些观点进行评级或排序。
- 第二轮调查:将第二轮问卷发送给专家,再次收集他们的意见。
- 再次汇总和分析:对第二轮调查的结果进行汇总和分析,进一步提炼出专家间的共识。
- 重复迭代:如果必要,可以进行更多轮的调查、反馈与调整,直到达到足够的共识或达到研究目标。
- 报告结果:最后整理和撰写研究报告,报告中应包括研究过程、专家意见的汇总、达成的共识以及任何显著的分歧
特点:
- 匿名性:减少群体压力,收集专家真实意见
- 多轮迭代:逐渐达成专家共识,提高决策的质量
专家评估结果的定量分析:
- 专家积极性系数,包括每轮调查的函询回收率(一般要求>70%)和提出意见的专家人数占比(示例如下)

- 专家权威系数 $Cr$,包括判断系数 $Ca$ 和熟悉系数 $Cs$,即:$Cr=(Ca+Cs)/2$
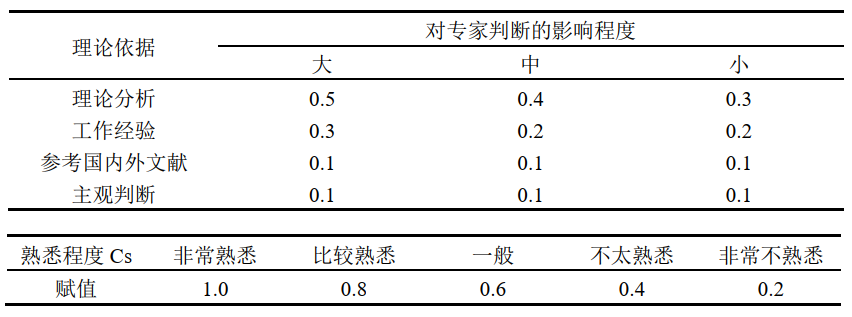
- 专家权威系数以专家自评的方式进行,包括专家对条目内容作出判断的依据,以及对咨询内容对熟悉程度
- 专家意见的协调程度,一般用肯德尔协调系数(Kendall's W)来评估(值域 0~1,越大越好)
- 专家意见的集中程度,一般用变异系数(CV=标准差/均值)来评估, CV≤0.25 表示专家的意见集中程度较高
专家函授的评价结果示例(部分):
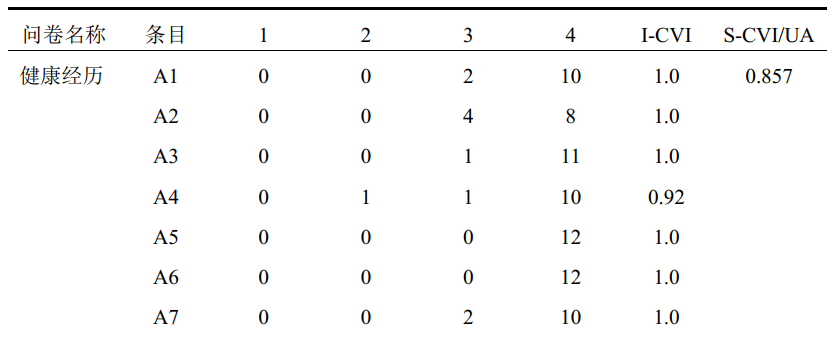
条目的内容效度分析 I-CVI:
- 描述了专家对每个条目的评定(评定条目与研究内容的关联性)
- I-CVI 的计算方式:评分为 3 或 4 的专家数除以专家总数
- I-CVI>0.78,则条目内容效度良好,予以保留; I-CVI<0.78,则条目需要修改或删
量表的内容效度分析 S-CVI/UA:
- 描述了专家对量表的评定(评定条目与研究内容的关联性)
- S-CVI/UA 的计算方式:所有专家评分 3 以上的条目占总条目的比例
- S-CVI/UA>0.8,则表示问卷总体内容效度良好
样本量估计
预调查的样本量:
- 经验方法,取条目组多的分问卷条目数的 5~10 倍
- 考虑到样本的遗失与无效问卷,再扩大 10%的样本量
正式调查的样本量 $N$ 则主要有两种常见方法
计算公式 1(基于总体率的估计,最常用): $$ N=(\frac{Z}{E})^2\cdot P \cdot (1-P) $$
- $Z$ 表示置信水平对应 Z 值(比如 95%置信水平下的 Z 值为 1.96),置信水平越高,所需样本量越大
- $E$ 表示误差范围,即调查问卷能接受的误差幅度,误差范围越小,样本量越大
误差范围一般有两种计算方式:(1)绝对误差一般使用显著性水平(比如 0.05)(2)相对误差则根据整体比例来确定,比如 $0.15\times P$,相对误差在实际调查问卷中更常用
- $P$ 表示整体比例,比如针对肠胃镜筛查的调查问卷,可使用普通人群的肠胃镜筛查率作为 $P$;在没有先验信息的情况下通常假设 $P=0.5$,但这通常会导致样本量高估(保守策略)
示例 1:假设对某地区肠易激综合征的患病率进行调查,根据文献资料,人群患病率为 15%, 若将容许误差控制在 3%,则 95%置信水平下的估计样本量 $N=\frac{1.96}{0.03}^2 \times 0.15 \times (1-0.15) \approx 545$
计算公式 2(基于总体均值的估计): $$ N= (\frac{Z\sigma}{E})^2 $$
- $\sigma$ 表示总体标准差,一般使用预调查的样本来计算;在多维度的问卷中,则一般选择不同维度下总体标准差的最大值,目的是确保样本量足够大,以应对最不稳定的测量
示例 2:某药厂生产的注射液,规定其有效成本含量为 2.25mg/支,标准差为 0.85,若希望以 95%的置信水平估计有效成本含量均值,并希望控制误差在 10% 以内: (1)若使用绝对误差,则 $E=10%$ ,检验需要的样本量 $N=(\frac{1.96 \times 0.85}{0.1})^2\approx 278$ (2)若使用相对误差,则 $E=10% \times 2.25=0.225$ ,检验需要的样本量 $N=(\frac{1.96 \times 0.85}{0.225})^2\approx 55$
调查问卷的评价
信度 Reliability 评估:测量工具或调查问卷在重复测量时的一致性或稳定性
效度 Validity 评估:测量工具或调查问卷是否能准确测量出需要测量或统计的概念
临界值法:
- 一种常见的问卷项目分析方法,用于评估问卷条目的区分度
- 目的:评估每个条目区分高分组和低分组受试者方面的能力
- 步骤:(1)按照问卷的总分对受试者排序(2)将受试者分为高分组和低分组,其中高分组一般为排名靠前的 30%的受试者,低分组一般为排名靠后的 30%的受试者(3)按照每个条目得分,针对分组结果进行独立性假设检验(比如 t 检验)(4)筛选出具备区分度(比如 p 值<0.05)的条目
- 作用:评估问卷条目的质量,辅助优化问卷结构,提高测量的准确性和可靠性
Kaiser-Meyer-Olkin (KMO) 统计量
- 评估数据适合进行因子分析的程度
- KMO 值介于 0 和 1 之间,值越接近 1,数据越适合进行因子分析
- 一般来说,KMO 值大于 0.6 被认为是适合的
Bartlett's 球形假设检验
- 检验数据的相关矩阵是否为单位矩阵(即对角线为 1,其他元素为 0)
- 作用:判断数据是否适合进行因子分析(p值<0.05 表示数据适合因子分析)
主成分分析与因子分析(结构效度评价)
- 根据Kaiser标准,只有特征值大于 1 的主成分才被认为是有意义的
- 通常希望这些主成分的累积解释方差达到 70% 以上
- 因子荷载表示每个变量在主成分上的贡献通常,在心理学和社会科学中,因子载荷大于 0.4 通常被认为是显著的(表示该变量对该主成分有较大的贡献)。
在某些探索性研究中,因子载荷大于 0.3 也可能被接受,
方差最大化正交旋转(Varimax rotation)是一种常用的因子载荷矩阵处理方法,它通过旋转因子轴来最大化每个因子上变量的方差,从而使得因子载荷矩阵更容易解释
Cronbach's Alpha 系数(信度评价) $$ Cronbach's Alpha = \frac{N}{N-1}(1-\frac{\Sigma 每个条目的方差}{总分方差}) $$
- 总分方差:先按照每个条目加和,得到条目总分,再计算得到的方差
- 一种用于评估问卷或测试内部一致性的方法(不适用于类别型条目)
- Cronbach's Alpha 值在 0 到 1 之间,通常认为 0.7 以上表示良好的内部一致性
重测信度系数(信度评估)
- 一种评估测量工具在不同时间点上稳定性的方法
- 计算方式:计算两次测量结果之间的皮尔逊相关系数来评估
- 相关系数的值在 -1 到 1 之间,接近 1 表明重测信度较高
对于分类数据,可考虑使用其他相关系数(如斯皮尔曼相关系数)
注意:重测信度的评估需要在合理的时间间隔内进行,以确保测量工具的稳定性
统计学分析
描述性分析:
- 对于类别型变量(比如性别),一般采用频数、占比进行描述性分析
- 对于数值型变量(比如年龄),一般采用均值±标准差进行描述性分析
- 所以描述性分析,一般覆盖到患者人群画像与问卷结果的基本信息和特征
图表可视化:
单因素分析:t 检验或卡方检验
多因素分析:逻辑回归建模分析,多元线性回归,结构方程,亚组分析
Y1: 逻辑回归(是否发生了肠胃镜筛查) Y2: 线性回归(知,信,行的调查得分)
X:基本信息