本文对谷歌年度盘点博客进行总结(在原文的基础上进行了一定拓展)
1 经典计算与量子计算
1.1 量子计算
前置知识:量子力学基础
量子评估基准 - 随机电路采样(241009 Nature)
- 随机电路采样(random circuit sampling,RCS)由谷歌在 2019 年首次提出,该方法通过模拟特定电路结构并计算所需的最低资源量,来评估设备的量子电路容量(值越大,量子计算机性能越强)
- 保真度(fidelity):RCS 评估基准的输出,一个介于 0~1 之间的数字;含噪声量子处理器的状态与实现相同电路的无噪声理想量子计算机的状态的接近程度,该指标也可用于经典超级计算机的估计
- 经典计算机的挑战在于信息的指数增长。随着量子电路的规模增大,描述其状态所需的信息量呈指数增长。而量子计算机则展示出了量子优势,在 RCS 评估中展现出远超越传统计算机的性能
随机电路采样(RCS),虽然对经典计算机来说极具挑战性,但尚未展现出实际的商业应用
量子错误识别 AlphaQubit(241120 Nature)
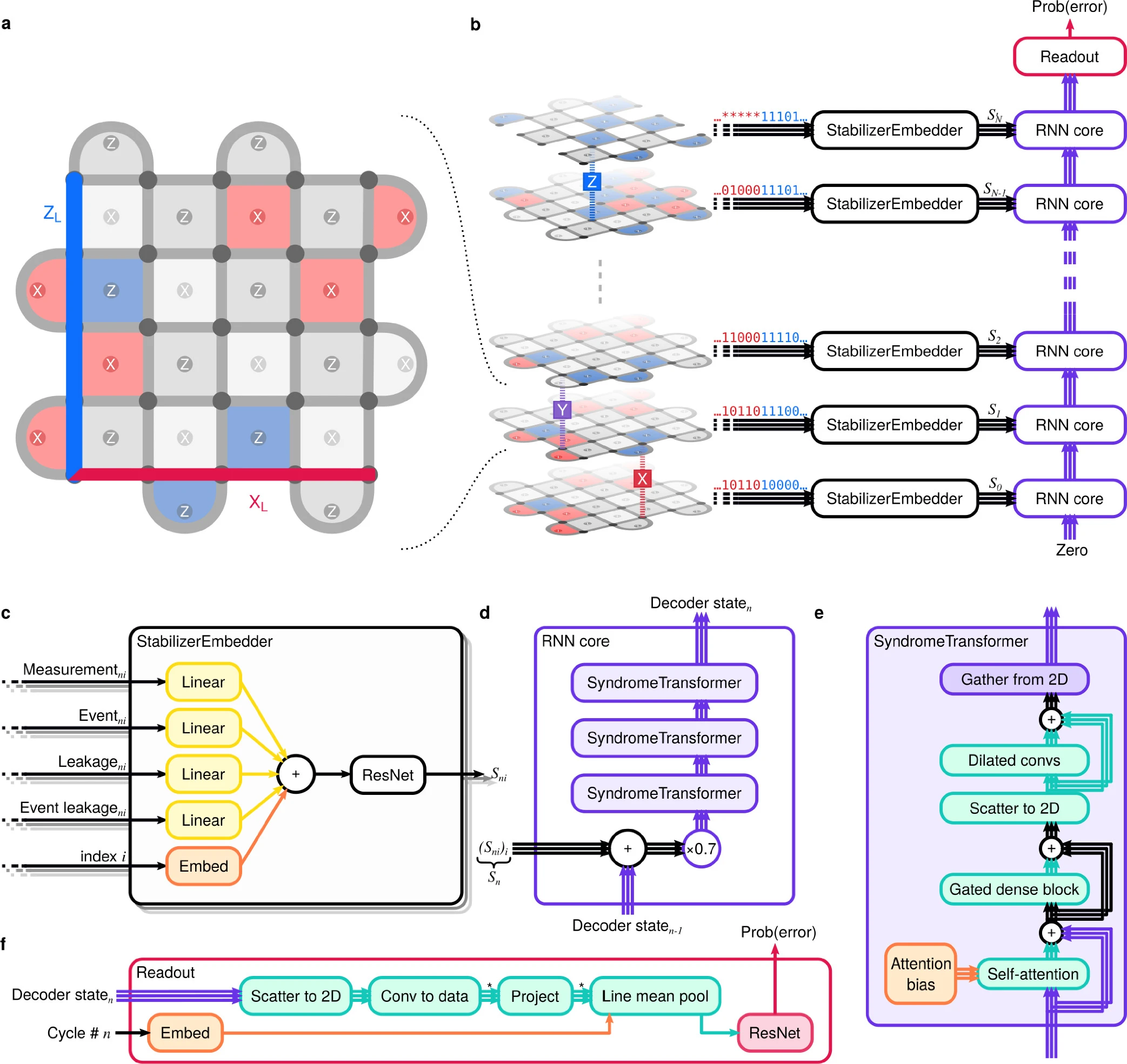
- 一种基于 RNN 和 Transformer 的神经网络解码器,能够以最先进的精度识别量子计算错误
- 预训练:用量子模拟器合成数据(20亿)训练,让模型能够学习量子错误的基本结构
- 微调:用 Sycamore 量子处理器真实数据(2w5)微调,使模型适应实际硬件中的特定噪声
- AlphaQubit 的输入包括 X 和 Z 稳定器持续软读出的测量结果和检测事件(串扰/泄露等)
- 该输入信息通过包含注意力和卷积的多个层更新模型的内部状态,并通过训练指导模型适应更复杂但未知的底层错误分布,并输出量子错误的解码(即预测量子错误的类型与具体位置)
- AlphaQubit 在实验结果中明显优于之前的矢量网络解码器(效率很低),并且减少了 6%的错误;相比传统的相关匹配方法(MWPM)解码器减少了 30%的错误
- 随规模的增加,AlphaQubit 的精度能保持不变;但训练难度增加,同时所需要更多的训练数据;如何在码距离超过 11 时仍保持高精度依然是未来工作中需要重点解决的
新型量子芯片 Willow(241209 Nature)
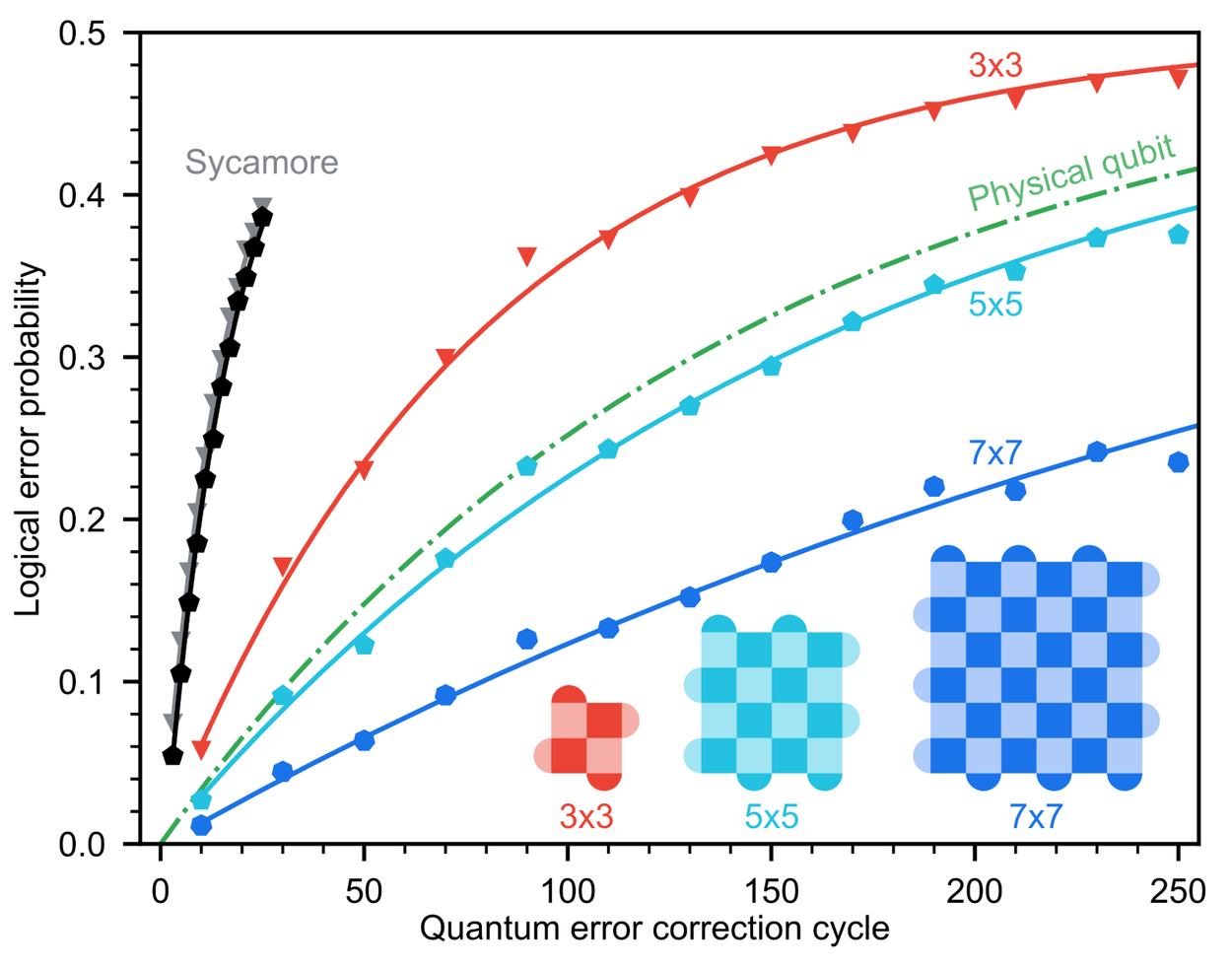
- 量子纠错改进:随着量子比特的规模扩展,Willow 可以指数级地减少错误(历史性创新)
- 当晶格尺寸从 3x3 增加到 5x5 再到 7x7 时,Willow 的编码错误率平均降低了 2.14 倍
- Willow 在五分钟内完成了一项标准的基准计算,远超最先进的超级计算机(100 万亿年)
- Willow 量子纠错所提供的改进呈指数级增长,让大规模、可容错量子计算机的实现成为可能
Willow 的核心创新点:
- 基于表面码的可规模化量子纠错架构和“物理错误率低于阈值”的纠错机制
- 基于 AlphaQubit 的量子错误解码和动态线路编译进行实时微秒级错误纠正
- 硬件革新与量子比特性能提升:量子态稳定性提高 5 倍,物理错误率下降
1个逻辑量子比特需49个物理比特(7×7网格),百万级物理比特才可构建实用量子计算机
1.2 模型推理优化
推测编码 speculative decoding(20221130 arxiv)

- 推测解码下,将小模型用于猜测机制;被接受的猜测以绿色显示,被拒绝的建议以红色显示
- 在翻译场景下,将 60M 的 T5-small 用于11B 参数的 T5-XXL 模型猜测,可获得 3 倍加速
- 推测解码已被证明是一种有效的优化技术范式,广泛应用于 LLMs 的推理加速/低成本化
推测编码的优势在于,将单 token 的顺序生成过程转化为多 token 的并行验证过程,实现模型推理的加速(由于现代计算机的并行能力,大模型处理一个token和处理 n 个token的用时是几乎一样的)
推测编码的改进 1:块草稿优化(NeurIPS 2024)
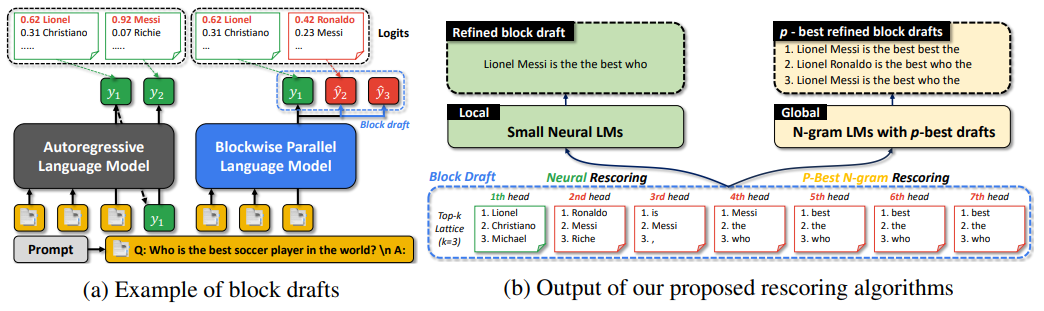
- 推测编码的小模型跨预测头得到多个未来的 token,组成了一个块草稿(block draft)
- 使用局部神经网络或全局 n-gram 进行评分,得到最有可能的 Top-k 种推测用于验证
- 本文创新:在不改变底层模型参数的情况下,提高块草稿的质量,从而实现推理加速
- 实验结果:经过评分/排序优化后的块草稿,平均验证通过率在不同任务中提高了 5~25%
推测编码的改进 2:块验证加速(20240315 arxiv)
- 标准的 token 验证算法需要独立验证每个 token,而本文提出的方法则通过联合验证整个块草稿;该方法可以在保持相同的生成分布的情况下增加可验证的 token 量(5%~8%)
Pause Tokens 延迟推理(20231003 arxiv):
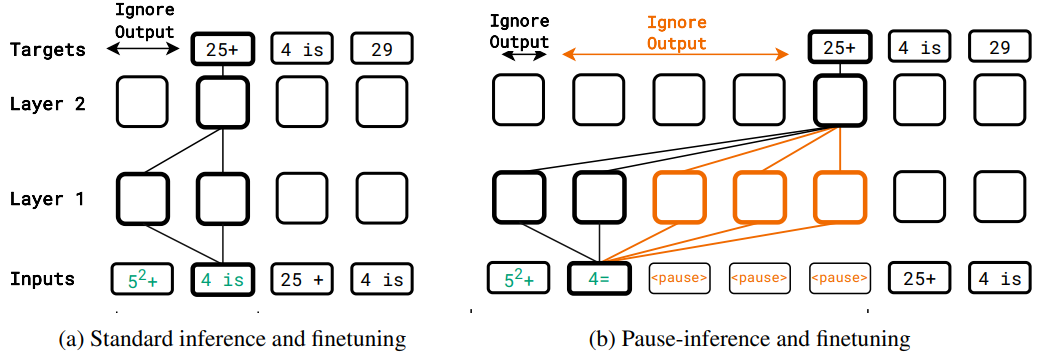
- 方法:通过引入
<pause>token 来延迟模型的推理,以改善模型表现(三思而后行) - 结论:当模型在预训练和微调阶段都使用延迟时,推理时的延迟可以提高任务性能
- 实验:1B 小模型在多数任务上表现出性能提升,尤其是SQuAD问答任务提高了18%
1.3 注意力机制改进
PolySketchFormer:基于多项式核的快速 Transformer(原始论文 231002)

- 论文首先证明高阶多项式注意力(p ≥ 4)可以有效替代 softmax 注意力,同时不牺牲模型质量
- 算法的主要创新点:(1)从数值线性代数领域引入了多项式草图技术,以线性时间复杂度实现多项式核的近似特征映射(2)通过近似特征映射的非负性约束,保持训练过程的稳定收敛(3)提出一种基于块的并行前缀和算法(将线性依赖的计算过程重构为二叉树状的并行计算)来计算下三角矩阵乘法,发挥 GPU 的并行优势(4)相邻的 token 计算精准多项式注意力,而不是近似多项式注意力(能改善模型的最终性能)
- 实验:与 Flash Attention 相比,PolySketchFormer 构建的模型在训练速度上实现了 2.5-4 倍的提升
草图技术(sketching ),一种将高维特征向量(精细的图像)进行随机低维投影(粗略的草图)的技术,由 JL 引理保证:随机投影的低维向量能高概率保留原始向量间的相似性特征(比如欧氏距离/内积) 值得一提的是,PolySketchFormer 采用的是一种启发式方法,针对每种类型的多项式核学习和训练单独的多层稠密神经网络,并替代了原本的“随机低维投影”(实验表明该方法对模型性能提升很大)
HyperAttention:线性复杂度的注意力近似计算(原始论文 231009)
- 思路:通过行列的最大范数来捕捉问题的复杂性,并借此分块实现注意力矩阵的近似计算

- 过程:(1)基于sortLSH(排序局部敏感哈希)筛选出注意力矩阵的主要条目/高值注意力,并输出掩码矩阵 $M^{H}$(2)针对下三角掩码矩阵 $M^C$ 进行分块,并利用递归思想继续分块(3)对于分块结果应用快速KDE求解器实现注意力矩阵的近似计算
- 优势:HyperAttention 展现出显著的加速效果,在序列长度为 n=131 k 时,其前向和反向传播速度提升了超过 50× 倍。在处理存在顺序依赖的因果掩码时,该方法仍能提供显著的 5× 加速效果
- 不足:HyperAttention 也会导致特定任务的性能下滑,在替换 50%的层后,模型在不同任务都会存在性能损失(在摘要和代码补全任务中表现更为稳健),但一般性能损失会少于 13%

sortLSH(排序局部敏感哈希):(1)将相似的输入映射到相同的哈希桶(2)对桶内的数据点进行排序(比如按照注意力值的高低)(3)从每个桶中选择最重要的数据点(4)根据重要的数据点生成稀疏掩码 快速KDE求解器:(1)KDE 求解器通过对分块中的数据点应用核函数(例如高斯核)来估计其密度,识别数据点的集中区域(即注意力值较高的区域)(2)快速KDE求解器则利用 sortLSH 的稀疏掩码结果+随机采样补充,加速了核密度的估计过程,进而加速近似注意力矩阵的计算
Selective Attention:忽略无关信息的注意力加速(原始论文 241003)
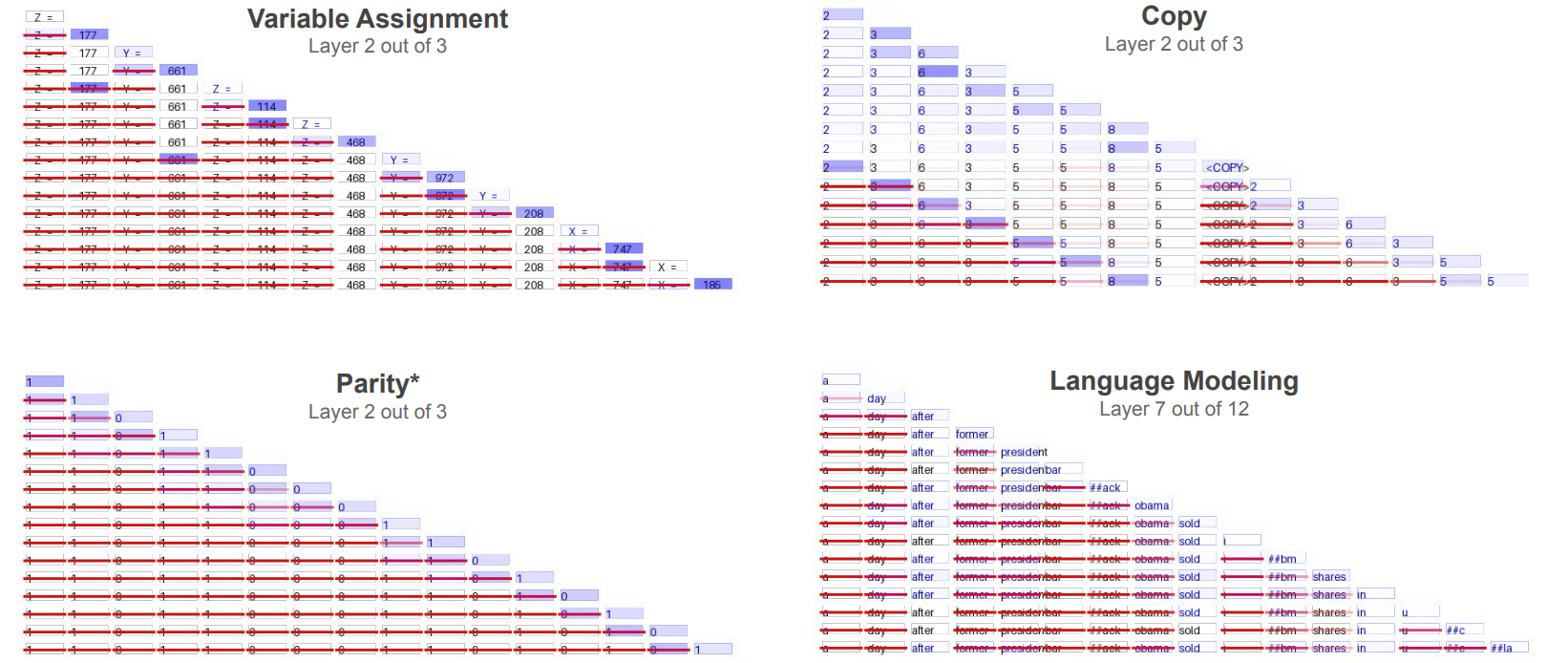
- 思路:现实中的上下文可能存在无效的信息干扰模型的推理,加重注意力的计算负担;比如"当 x=1 时,y=2,z=3 时,计算 y+z 的结果"中,"x=1"就属于存在干扰的无效信息
- 过程:(1)对于长度为 N 的上下文,定义 $N\times N$ 的遮蔽矩阵 $S$(2)$S_{i,j}$ 表示 $token_{i}$ 对 $token_{j}$ 的遮蔽程度(此处遮蔽程度的计算,论文是直接复用的注意力模型中一个头的结果)(3)后处理遮蔽矩阵 $S$ ,约束其因果性和非负性(3)在应用 softmax 注意力前,根据矩阵 $S$ 的累积信息屏蔽掉部分历史 $token$
- 实验:显著降低内存和计算需求;在 C4 数据集上训练的 Transformer,其上下文大小分别为 512、1,024 和 2,048 时,其注意力模块所需的内存分别减少了 16 倍、25 倍和 47 倍
1.4 机器学习框架
用于多任务的两阶段延迟学习框架(原始论文 241021)
- 延迟学习(Learning-to-Defer,L2D),预测模型与人类专家的决策者相结合;当基于训练模型的置信度低于专家时将决策延迟给专家;延迟机制增强了安全性,尤其是医疗诊断等高风险场景
- 特点:(1)多任务,模型由共享特征提取器 $w$、分类器 $h$ 和回归器 $f$ 组成,通过一个多头网络 $g$ 输出多任务预测(分类+回归)(2)两阶段,联合分类-回归模型的预训练+联合外部专家的延迟学习(2)延迟损失,拒绝器(小型 Transformer)根据延迟损失最小来决策是否进行决策延迟过程(3)延迟损失替代:利用交叉熵来近似替代多类 0-1 损失,该替代损失提供了真实损失的上界,并具备贝叶斯一致性
- 结果:实验显示本文方法有效地捕捉了分类和回归之间的内在相互依赖性,并在物体检测和电子病例分析两项涉及分类和回归的多任务问题(比如同时预测是否死亡和住院时长)中,均取得了 SOTA
多专家学习延迟框架的损失函数设计(原始论文 231023)
- 专家的定义:具备特定领域专业知识的真人,或性能强大但推理成本高的大模型
- 学习延迟:最早的学习延迟可追溯到基于置信度阈值的学习拒绝或放弃;
- 特点:(1)基于多专家的延迟学习场景进行框架设计,同时学习预测器和拒绝器(2)提出了一种新的延迟损失函数替代,该替代实现了 H-一致性界限(相比贝叶斯一致性具备更强的理论保证)
- 结果:随着专家数量的增加,系统的整体准确率能够实现持续而稳定的提高

简单理解:贝叶斯一致性和H-一致性界限 贝叶斯一致性关注全局最优,后验损失函数分布会随着样本的增加逼近真实损失 H-一致性界限关注“特定模型”下的渐进最优,模型参数会随着样本的增加逼近最优解
基于模仿学习的编译器内联决策优化(原始文章 241023)
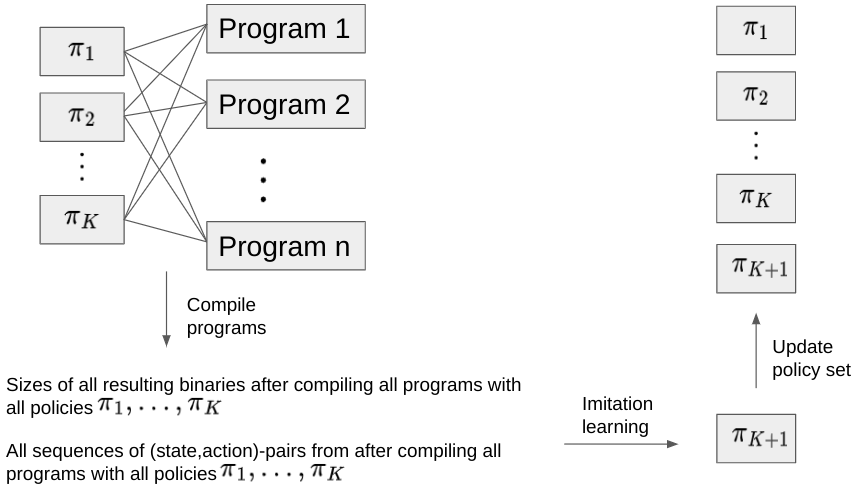
- 内联决策优化:用函数体替换程序中对函数的调用,通过移除冗余代码来最小化二进制文件
- BC-Max 迭代模仿学习的实现过程(1)将内联优化转化为是否需要进行内联决策的分类问题(2)构建编译程序语料库,包含每个程序每种状态下的最佳内联决策(3)训练迭代,每一次迭代都需要交替进行实际编译和语料库的学习,直到获得接近理论最优的策略,并纳入语料库
- 结果:针对一个 3w 个程序组成的二进制文件,只需要 7 次迭代就能超越传统的 RL 算法
基于条件语言政策框架的多目标微调(原始论文 240722)
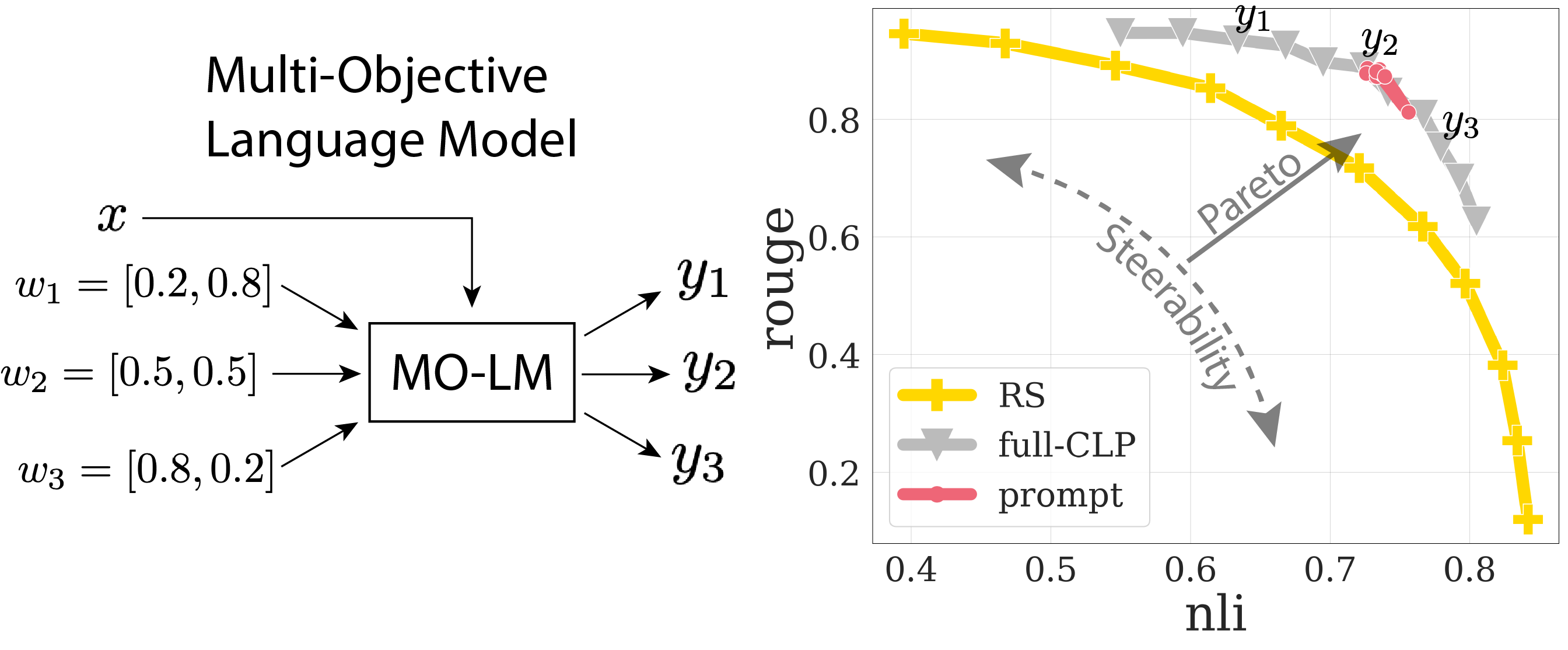
- 条件语言策略(CLP):LLMs 根据人类偏好的多样性和应用场景的不同,在微调阶段同时处理多个目标;模型追求加权奖励和(Reward Soup,RS)的最大化,通过覆盖广泛兴趣空间的结果,为用户提供个性化输出;同时要注意,不同目标之间可能存在冲突
- 上图(左)展示了一个多目标语言模型,该模型可以根据不同的奖励权重来进行输出;针对同一个输入提示文本 $x$ ,第 $i$ 个评测者的个性化奖励权重为 $w_{1}$ ,模型对应的个性化输出为 $y_{i}$
- 上图中,横轴 NLI 表示语义忠实度奖励,纵轴 Rouge 表示语义完整性奖励;基于 CLP 多目标微调有两个目的(1)推动帕累托前沿外移(提高语义的忠实度和完整性)(2)帕累托前沿拉伸(提高输出的多样性和可控性)
- 稀疏线性回归:输入为 token 组成向量,输出为与预测目标 y 最相关的输入向量索引;1-sparse 假设,即表示只有一个特征对目标变量有显著影响(只关注与 y 最相关的 token)
- 本文假设 Transformer 的 ICL 机制是因为模型能够直接根据数据学习,实现稀疏线性回归的推断,并以此进行样本复杂性分析;Transformer 推断的所需样本量与稀疏度、输入维度和误差容忍度有关
- 论文通过实验验证了理论分析的正确性:模型能够通过 1~5 个示例样本(独立同分布)直接学会正确的稀疏线性回归假设,并且其注意力权重的分布与理论分析一致
- 实验还发现, ICL 性能对分隔符(用于组成示例并构建提示,比如
\n,:等)的选择非常敏感
1.5 机器学习数据
Croissant:用于机器学习数据需求设计的元数据格式
- 核心组件:格式规范、示例数据、用于验证和消费数据的 Python 库和可视化工具
- 功能概述:分享、搜索与下载数据,简化分析与加载过程,兼容主流 ML 框架
- 资源说明:博文说明、官方地址、Python库、数据搜索与下载链接
敏感性抽样:抽取最优数据子集用于机器学习训练(原始论文 240227)
- 步骤(1)通过 k-means 聚类对数据嵌入向量进行分组(考虑中位数以规避异常值的影响)
- 步骤(2)计算每个数据点的代理损失 $\tilde{l}(e)$ 来近似真实损失 $l(e)$;代理损失 $\tilde{l}(e)$ 主要考虑聚类中心的损失 $l(c_{e})$ 和每个点到最近聚类中心的距离平方和 $|e-c_{e}|_{2}^{2}$ 来计算($c_{e}$ 表示距离类 $c$ 最近的数据点):
$$ \tilde{l}(e):=l(c_{e})+\lambda|e-c_{e}|_{2}^{2} $$
- 步骤(3)以概率 $\tilde{l}(e)$ 在每个聚类分组内部进行敏感性抽样,得到数据核心集(coreset)
- 本文证明了 coreset 的子集损失与完整数据集损失的误差存在一个可接受的上限
- 实验结果证明,该采样方法适用于 LLMs 微调(达到同样的性能只需原来 9%的数据量)、图像分类和线性回归等 ML 任务;同时该采样方法保持线性时间复杂度,计算效率也很高
除了损失函数,本文还考虑使用梯度值的 L2 范数用于采样策略,效果也不错
PCBS:并行图聚类的开源基准测试数据(原始论文 241115)
1.6 差分隐私
差分隐私随机梯度下降(DP-SGD)的改进(原始论文 240326)
- DP-SGD:在随机梯度法的学习过程中通过添加噪声来保护个人数据的隐私
- DP-SGD 的不足:基于洗牌(Shuffling)的 DP-SGD 可能导致比隐私损失的低估
- DP-SGD 的改进:本文提出考虑基于泊松子采样(Poisson subsampling)的DP-SGD 来进行隐私保护,并通过理论分析和数值实验,展示了该方法能提供更准确的隐私保护
- 基于 Map-Reduce 架构泊松子采样:(1)在第一个"Map"操作中,基于泊松分布对每一个样本进行独立的采样,得到可能的分组索引(2)在“Reduce”操作中,按照分组索引对样本进行实际分组(3)在第二个"Map"操作中,对分组结果进行截断或填充,规避泊松子采样数量不固定的问题

差分隐私中流式持续计数问题的优化(原始论文 240425)
- 流式持续计数问题:输入动态的数据流并在满足差分隐私的前提下输出这些增量的累积总和
- 创新点:一种空间效率高的流式矩阵乘法算法+二叉树机制的递归构造,实现更高的计算效率
DP-Auditorium:用于差分隐私审计的 Python 开源库
- 一种通过函数空间中的散度优化来测试差分隐私的新方法,优于传统的黑盒测试
- 能够有效地识别差分隐私保证的违规行为,以及不同测试场景下的特点错误检测
PriorBoost:自适应聚合响应学习算法(原始论文 240207)
- 聚合响应学习(Learning from Aggregate Responses, LAR)算法:将数据集按照同质性进行聚合分袋(bags),并针对聚合标签进行模型的训练,以确保数据满足隐私安全要求
- LAR 算法典型案例 - 预测化合物对特定关键靶点蛋白的活性抑制强度:考虑的实验成本和操作复杂度,一般会针对一组化合物进行生物活性测试,因此最终数据集只有聚合特征(不同的核心化学骨架结构)和聚合标签(该组混合物活性抑制强度的平均值和标准差),但实际推理是针对单个化合物的预测
- PriorBoost:(1)对数据集分片,并针对第一片数据进行随机分袋(2)根据分袋后聚合标签来训练预测器,用于个体标签的预测(3)根据预测器的输出,通过一维尺寸约束的 k 均值聚类,来优化第二片数据的分袋(4)重复以上过程,从而自适应地形成样本的最优打包,包内样本的真实标签具有同质性;(5)PriorBoost 还会向聚合标签添加拉普拉斯噪声,来确保标签的差分隐私(可选步骤)
- 论文实验表明了 PriorBoost 的先进性,不过仅限于线性回归和广义线性模型(存在理论约束)
标签比例学习(Learning from Label Proportions, LLP)
- LLP 算法,一种弱监督学习方法,可以看作是 LAR 算法的一种特例;其预测器的学习主要依赖分袋(bags)后袋内聚合标签(比如均值),而不是每个样本的真实标签
- LLP 算法典型案例 - 社区的匿名糖尿病筛查:出于隐私保护和成本的考虑,无法得到每个居民的糖尿病诊断结果,只能按照邮政编码获知该区域内的糖尿病居民比例(比如 A 区有 8.2%的居民确诊,而 B 区是 12.5%),但实际推理是针对个体层面的糖尿病诊断预测
- 关于 LLP 的更多理论分析与评估框架可参阅谷歌 24 年 6 月份的一篇论文
通过私有微调 LLMs 生成差分隐私数据 (原始文章 240516)
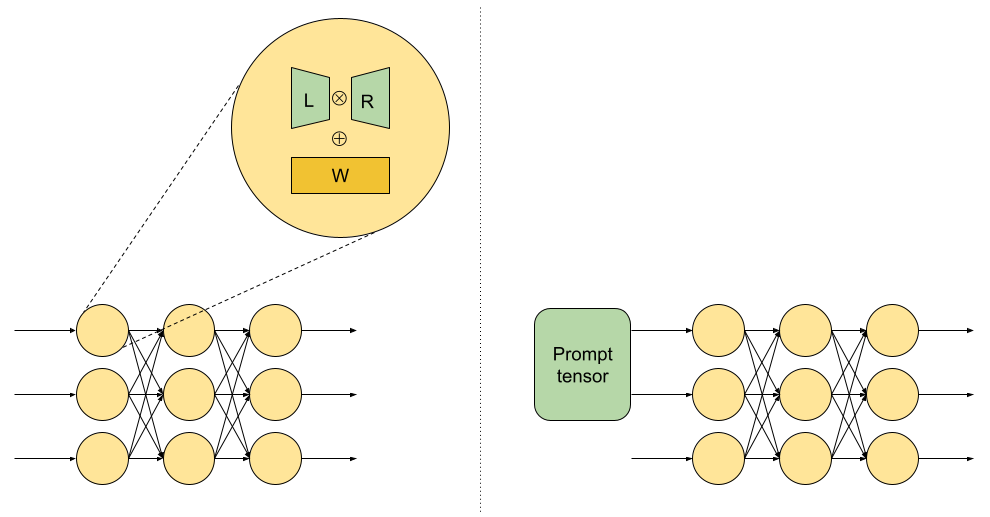
- Lora 微调:针对低秩矩阵 L 和R 进行高效微调;提示向量(prompt tensor)的微调,在网络输入层的开始位置插入一个提示向量,并进训练其权重,起到优化输入提示(prompt)的作用
- 对于在公共数据上训练的 LLM,使用敏感数据集进行提示向量的微调(因为相对于公共数据,敏感数据集的数据规模很少,难以支持全量参数的微调),在微调过程中通过差分隐私随机梯度下降(DP-SGD)来确保最终 LLM 生成的文本不会泄露敏感数据集中的隐私信息
- 其他方法:大规模差分隐私文本合成(240716)、联邦学习+ LLMs 差分隐私数据生成(240405)
1.7 计算优化
PDLP:大规模线性规划求解器(原始文章 240920)

- 上图中,x 轴是当前线性规划解,y 轴是当前对偶线性规划解;原始对偶混合梯度(Primal-Dual Hybrid Gradient, PDHG)是一种一阶优化算法,可用于求解 $\min_x f(x) + g(Ax)$ 形式的最优化问题;PDHG 的迭代计算主要涉及矩阵-向量的乘法,无需进行矩阵分解,能发挥 GPU 和分布式计算的效率优势;PDHG 特别适合处理大规模的计算问题,但收敛速度慢,不适合对精度要求高的场景
- 重启 PDHG 是 PDLP 的核心技巧,该方法通过双循环结构实现了更快的收敛速度,先运行普通 PDHG (蓝线)并计算均值 PDHG(红线),当 PDHG 触发重启条件时,算法从均值 PDHG 点重新开始(绿线)
- PDLP 的其他创新点:(1)通过重复行检测、界限紧缩等方式简化 LP 问题,减少问题复杂性(2)对变量和约束进行缩放,调整问题的数值条件来加速算法(3)利用 PDHG 的迭代来编码问题的可行性和有界性信息,判断问题是否存在可行解(4)自适应策略来重启 PDHG(5)自适应步长来加速收敛
- PDLP 的应用案例:(1)优化谷歌的数据中心网络的流量路由,节省大量机器资源(2)全球航运供应链的集装箱航运优化,有望减少 15% 的船舶运输和 13% 的集装箱量(3)解决了真实世界的1_study/math/NP-Hard 问题#2.1 旅行商问题,其实例规模巨大,约束矩阵中包含高达 120 亿个非零元素
- PDLP 的后续影响:(1)24 年数学规划国际研讨会上获得Beale—Orchard-Hays 奖(计算优化领域的最高荣誉之一)(2)已经集成到 Google 的 OR-Tools 开源项目和多个商业求解器(3)cuPDLP.jl 是一个用 Julia 编写的 PDLP 开源 GPU 实现
对偶线性规划解:原始线性规划(LP) 中的每个变量在对偶 LP 中变成一个约束;原始 LP 中的每个约束在对偶 LP 中变成一个变量;二者的目标方向相反(最大值->最小值) LP 可以解释为"资源分配"问题(给定资源,如何实现最合理的分配来实现生产收入最大化?),那么它的对偶 LP 可以解释为一个"资源评估"问题(给定预期生产收入目标,如何计算所需要的最少资源需求?)
TimesFM 时序预测模型(原始文章 240508)

- 模型参数量为 2 亿,主要包括残差模块、位置编码(PE)、因果注意力(SA)、前馈网络 (FFN) 等经典的神经网络模块;模型输入的时序长度为 32,输出的预测时序长度为 128(较长的输出时序长度,能减少错误的累积,有利于模型对于长时序问题的递归预测性能)
- 预训练的语料库包含 1000 亿个真实世界时间点的海量时间序列,主要来自谷歌趋势和维基百科页面浏览量;此外还有使用统计模型或物理模拟等方式人工合成的时间序列数据(也有真实意义)
- 实验结果表明:TimesFM 在不同领域和不同时间粒度的外部数据的零样本性能优于大部分统计方法(ARIMA、ETS),也接近或超过此前的最先进有监督学习方法(DeepAR、PatchTST 等)
- 相关代码和模型文件也已经分别在 Github 和 Huggingface 上开源
1.8 其他领域
GameNGen:神经模型驱动的游戏引擎(原始论文 240827)
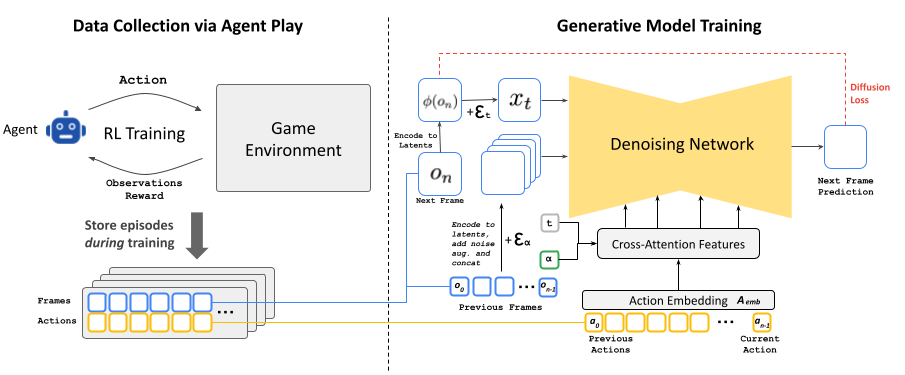
- 数据准备:基于 Agent+强化学习的方式玩游戏,生成并存储数据(动作与视频帧)用于模型训练
- 模型训练:利用动作与视频帧来训练生成扩散模型,模型输入包括历史的动作和视频帧,模型输出为视频下一帧的预测画面;训练期间会通过向历史帧的编码结果添加噪声,使得模型学会历史帧的纠正能力(该技巧能减少推理过程中的自回归漂移问题,有助于预测视频帧保持长时间的稳定性)
- 模型微调:由于扩散模型的编码器存在压缩,因此可能导致预测视频帧产生伪影,影响细节;因此为了提高图片质量,利用真实目标帧像素计算的最小均方误差(MSE)损失来微调扩散模型的解码器
- 最终效果:GameNGen 能在单个 TPU 上以超过 20 帧每秒的速度交互式地模拟经典游戏 DOOM
广告领域:
- 在搜索结果的 AI 概述中集成广告(原始文章 241003):谷歌搜索“如何去除牛仔裤上的草渍?”,搜索结果中的 AI 概述提供了多种有用的解决方案,包括常见家用产品和去污剂等专业产品。同时相关的购物广告会直接出现在 AI 概述中,让你能够快速轻松地找到完美的去污剂
- 基于大模型的广告拍卖与竞价(原始论文 240702):在 LLMs 保留单独的偏好空间用于生成灵活的文本输出,不同的广告商可以通过竞标并影响该空间的生成内容
- 自动化在线广告竞价策略的综述(原始论文 240814):涵盖了该领域的多个主题,包括竞价算法、常见拍卖格式的均衡分析和效率,以及最优拍卖设计
2 大模型优化
2.1 LLMs 内容改善
RLEF:基于强化学习增强 LLMs 的事实一致性(原始论文 230531)
- 奖励设计:通过预训练的自然语言推理(Natural Language Inference, NLI)模型来评估输入文档和摘要之间是否存在文本蕴含关系,即摘要是否能够根据输入文档推导出来
- 强化学习训练:使用策略梯度方法(比如 PPO)来更新模型参数来最大化累积奖励,同时引入 KL 散度作为正则项,防止模型在追求事实一致性时偏离原有的摘要生成能力
- 实验结果:RLEF 模型在事实一致性(NLI和Q2指标)上取得了最高的分数,表明强化学习方法在利用NLI信号方面是有效的;在其他基线测试和人类评估中也持平或略优于其他方法
G-RAG:基于图神经网络优化 LLMs 的 RAG 策略(原始论文 240528)

- AMR (Abstract Meaning Representation)图是一种描述文本语义信息的有向图,其中的节点表示基本的语义单元(比如实体或概念),边则表示它们之间的关系;可用于处理复杂的语义信息
- 从 AMR 到文档图(Document Graph):(1)对于每个问题-文档样本对,利用预训练 AMRBART 来解析文本并生成 AMR 图(2)基于 AMR 建立无向文档图,文档图中的节点表示一个文档,边即表示两文档之间存在语义关联(3)移除文档图中的孤立节点,并构建图神经网络用于预测文档与问题是否有关
- 用于重排序的图神经网络(GNN):(1)GNN 的输入主要包含文档文本和 AMR 信息(语义信息、语义结构)(2)GNN 利用这些信息来识别问题与文档上下文的相似性(3)GNN 利用 mean 函数来聚合节点及其邻接节点的信息(4)GNN 的损失函数为排序损失中常用的成对损失函数
- 实验结果:G-RAG 能识别到包含有价值信息的文档,其作为重排序器用于 RAG 具有一定优势(在 50%的场景下取得 SOTA),在零样本学习的重排序任务中有 7% 的显著改进
AMRBART(原始论文 220504): 基于经典的BART 模型(一种基于标准 Transformer 的 Encoder-Decoder 架构) 预处理阶段将 AMR 图转为线性序列,并引入特殊标记来区分文本和 AMR 图; 预训练阶段的目标是将被 5 种随机噪声函数损坏的文本进行修复和重建; 微调阶段的任务是输入完整文本并输出特定类型的序列(比如 AMR 序列); 推理阶段则支持两类基本的转换任务:文本转 AMR 图, AMR 图转文本。
Gemini 更新:
- 支持超过 40 种语言和 230 多个国家和地区
- Related sources:为事实查询提示显示相关内容链接,减少幻觉,辅助探索
- Double-check:通过 Google 搜索来验证回复,突出显示得到证实或反驳的内容
2.2 LLMs 基准测试
2.3 多模态 LLMs
Time-Aligned Captions 多场景视频生成框架(原始论文 2406507)

- TALC 通过修改现有的文本条件机制,实现视频场景和场景描述之间的时间对齐
- 通过去噪器网络中的时间模块(如注意力和卷积块)来确保生成视频的视觉一致性
- TALC 既适用于微调阶段,也可以作为现有模型的插件来增强其多场景视频生成能力
- 实验表明: TALC 微调的模型在整体评分上优于基线模型,实现了 29% 的相对增益
UniAR:通过预测人类反馈来改进图像生成(原始文章 241112)
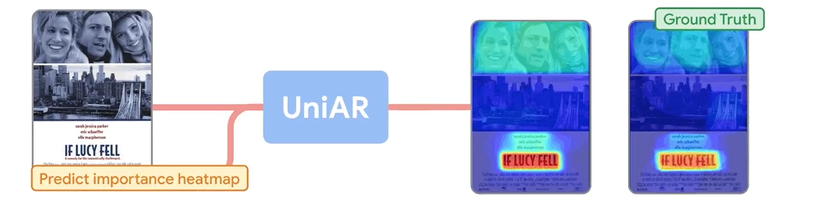
- UniAR 的组成(1)基于人类注意力和视觉重要性的热力图预测器(2)预测观看顺序的扫描路径预测器(3)用于图像或网页质量(美学)分数的评分预测器
- UniAR 作为一个统一的多模态模型,通过文本提示将特定的任务指令集成到模型中,能够预测人类对不同视觉内容的隐式和显式反应与反馈(注意力或视觉偏好)
- 实验结果:在 27 项基准测试中有 17 项取得了 SOTA,尤其擅长图形/界面设计
2.4 LLMs 的可靠性
Patchscopes:直观解释 LLMs 的内部机制(原始论文 240606)
- 本文主要提出了一种统一的框架,对现有的可解释技术进行了总结与扩展(已有工作:1. 基于线性分类器的探针 2. 基于模型词汇空间的表示投影 3. 在计算中识别或干预用于特定预测所依赖的表征)
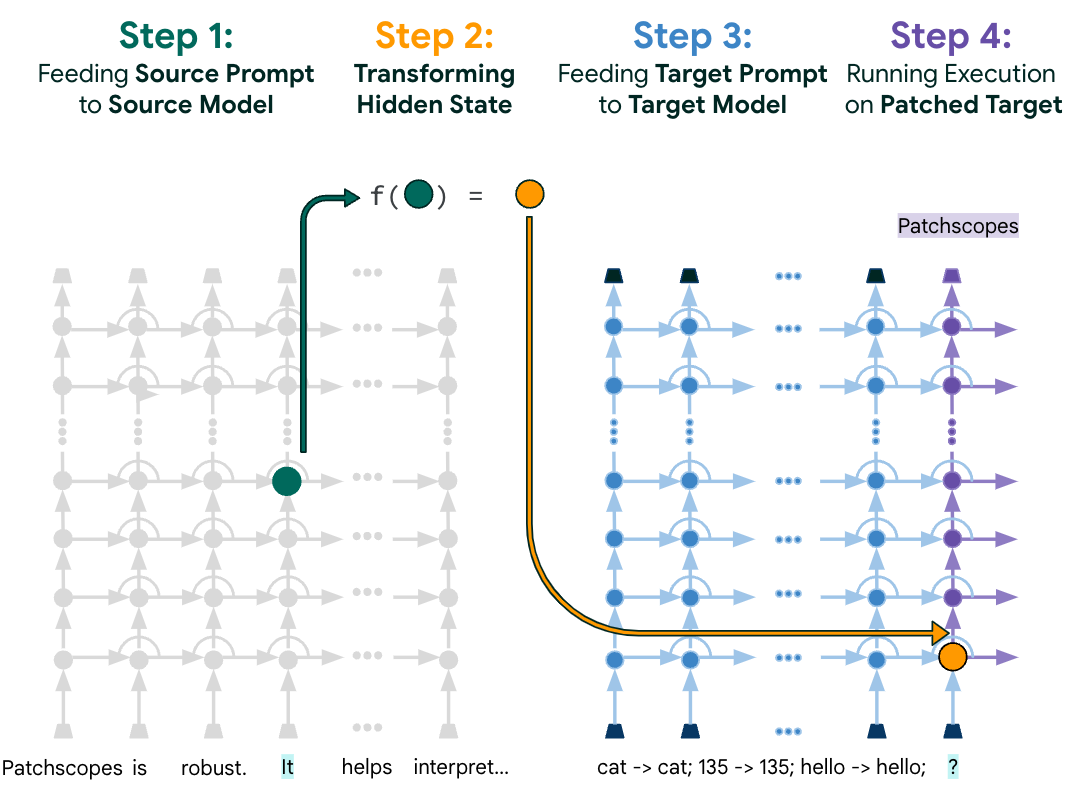
- 主要过程(如上图所示):先向模型展示一个标准提示,然后提供一个旨在提取特定隐藏信息的次要提示。在源提示上执行推断,将隐藏表示注入目标提示中,模型处理增强后的输入,揭示其对上下文的理解
- 应用方向: Next-token 预测、事实提取、实体解释、模型解释、错误推理修复
面向图任务的 LLMs 基准测试(原始文章 240312)
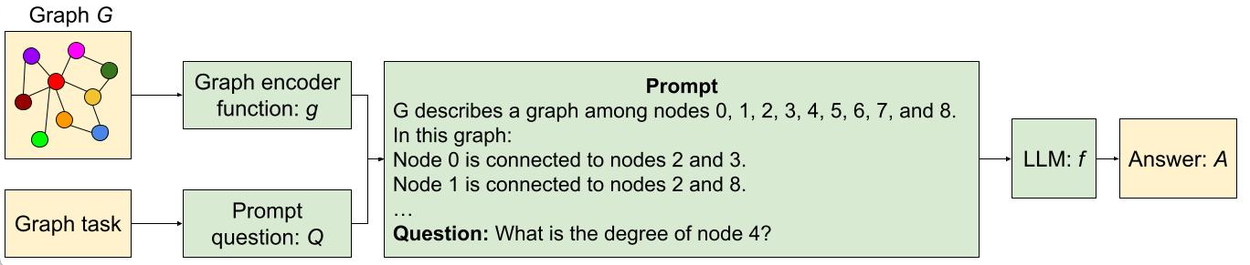
- 上图主要描述了将图问题转化为文本问题的过程,并提出了图推理的基准测试集 GraphQA
- 实验结论:不同的图结构和图编码方法对 LLMs 的图推理性能影响很大;在大部分图推理任务中,LLMs 的表现和其尺寸成正比,但模型尺寸对于“边存在”问题的影响很小;LLMs 在部分图任务(比如判断图中是否包含循环结构)中表现不佳
LLMs 的“忠实响应不确定性”(faithful response uncertainty)(原始论文 240527)
- 本文利用“法官”LLM(例如 Gemini Ultra)来评估 LLMs 回答问题的果断性和信心
- 实验分析表明,现代LLMs在忠实地传达其不确定性方面表现不佳,这阻碍了 LLMs的可信度
2.5 多文化 LLMs
涵盖不同的语言、文化和价值体系的数据集
- D3code:大规模跨文化平行标注数据集,用于检测侮辱性语言或攻击性预研,由超过 4k 名标注者完成;标注者性别和年龄分布均衡,来自 21 个国家,代表八个地缘文化区域
- SeeGULL:多语言和多文化的刻板印象数据集,包含刻板印象的人工标注(包含冒犯程度)
- CUBE:文本到图像(Text-to-Image, T2I)模型的文化能力,包括文化意识和文化多样性
基于联邦分析和差分隐私改进 Gboard 性能(原始文章 240419)
- Gboard 是谷歌推出的虚拟键盘,适用于 IOS 和安卓系统
- 虚拟键盘内置了一个与用户相关的词汇外词(out-of-vocabulary,OOV 词);OOV 词可能包含用户的个人习惯和隐私数据,对键盘的性能也有很大的影响;如何在确保隐私安全的情况下利用好 OOV 词是 Gboard 的优化重点
- 优化 1:谷歌与西班牙皇家学院(RAE)合作,创建精细的西班牙语词典,用于改善 Gboard 的词汇推荐
- 优化 2:Gboard 采用隐私安全的联邦分析,对用户的 OOV 词进行动态的发现与汇总;并通过本地噪声、用户参与度约束等方式,避免用户隐私信息的泄露;利用数据合成等方式改善小语种的准确率
3 个性化医疗和教育
3.1 个性化教育
LearnLM:专为学习和教育的微调模型(原始文章 240514)
- LearnLM-Tutor 是Gemini 1.0模型通过监督式微调(SFT)得到的教育领域文本生成模型;其微调数据主要包括辅导场景的对话数据、AI 角色扮演的合成数据、GSM8k 开源数据集(单词问题及其解决方案)、与教师合作编写的高质量对话(特定场景下的教学行为及其反馈)、教育安全数据集(违规行为标记)
- 最终的生成式 AI 助教,优于目前最强基线(包括助教外部提示加持下的大模型);同时本文还提出了一套包含七个教学基准的综合评估体系(涵盖定量与定性,并采用人工与自动评估方法),旨在从多个角度评估对话式 AI 助教的性能
- LearnLM 的应用(1)在谷歌搜索中,辅助主题理解或语言简化(2)在安卓设备上,直接辅助解决数学和物理问题(3)作为Gemini 的定制版本,用于学习指导与测验(4)在 Youtube 中,对学术内容进行解释或测验(5)帮助现实教育工作者简化并改进教案设计(6)集成到工具中辅助论文解读或主题探索
3.2 个性化医疗
Med-Gemini 多模态医疗领域的微调 Gemini(原始文章 240515)

- Med-Gemini 基于 Google 的 Gemini 模型,通过在去识别化的医疗数据上进行微调,同时继承了 Gemini 的原生推理、多模态和长上下文能力,该模型建立在医学调优大型语言模型 Med-PaLM 的初步研究基础上
- 实验结果:Med-Gemini 在 MedQA 美国医学执照考试(USMLE)基准中达到了 91.1%的准确率,超越了我们之前的最佳模型 Med-PaLM 2(高 4.6%);在 14 项医学基准测试中的 10 项上达到了最先进的性能
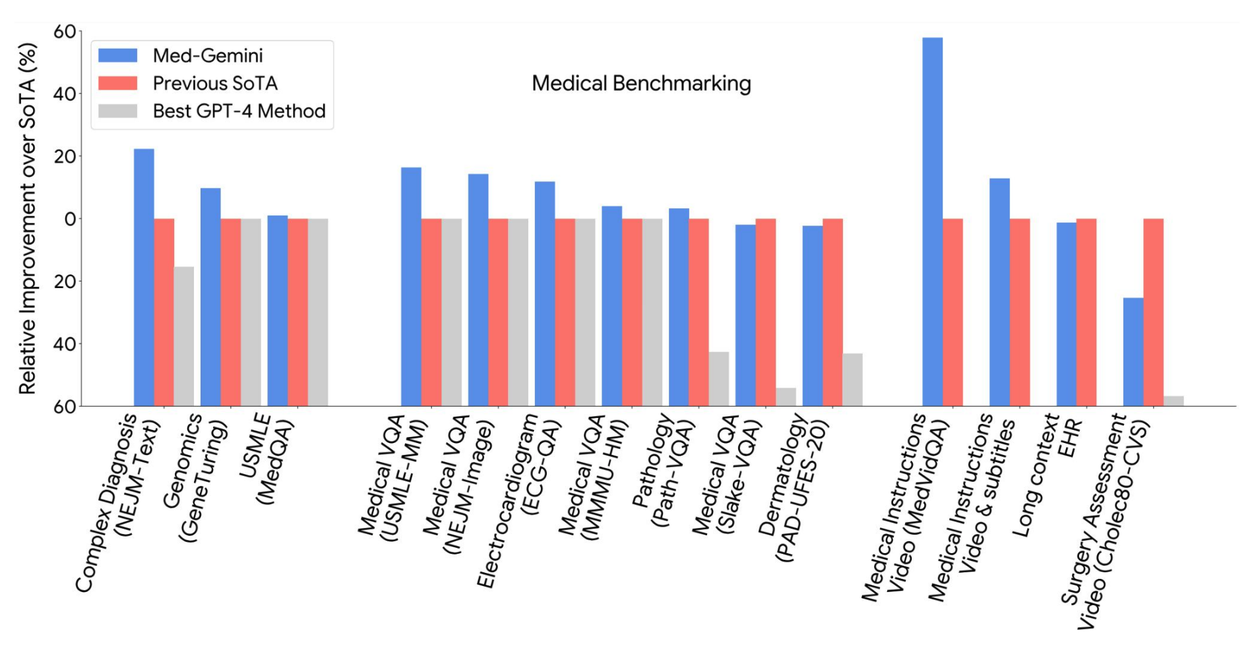
- 其他衍生模型:专注于医疗保健领域放射学、病理学、皮肤病学、眼科和基因组学应用的调优,提出了 Med-Gemini-2D(擅长胸部 X 光视觉问答)、Med-Gemini-3D(擅长头部 CT 成像与报告生成)和 Med-Gemini-Polygenic(擅长通过基因组数据预测疾病和健康结果)等模型
PH-LLM 个人健康大型语言模型(原始文章 240611)

- PH-LLM 是 Gemini 的微调版本,旨在生成关于睡眠和健身模式的个人健康行为改进见解和建议
- PH-LLM 通过使用多模态编码器对个人健康相关的文本理解和推理进行了优化,同时针对性增强了模型对可穿戴设备的心率变异性、呼吸率等原始时间序列传感器数据的理解
- 提出了三个基准数据集,涵盖了长文本指导性推荐任务、专家领域知识评估以及自我报告睡眠结果的预测;PH-LLM 在后两项测试中均超过了人类专家水平(79% vs 76%, 88% vs 71%)
AMIE 针对诊断推理和对话优化的实验性系统(原始论文 240111)

- AMIE 是一个针对诊断对话优化的对话式医疗人工智能。AMIE 通过结合真实世界和模拟的医疗对话,以及多样化的医疗推理、问答和摘要数据集进行指令微调
- AMIE 的"内部"自我博弈循环:利用上下文评论反馈来改进其在与患者 Agent 进行的模拟对话中的行为
- AMIE 的"外部"自我博弈循环:经过优化和精炼的模拟对话集会被纳入后续的微调迭代中
- AMIE 在线推理期优化:使用链式推理策略,根据当前的对话逐步完善其响应,并给出合理的回复
- 在一项双盲远程客观题临床考试 (OSCE) 中,AMIE 在大多数维度上优于初级保健医生 (PCP)
3.3 基因组学研究
REGLE 高维临床数据与遗传变异的关联发现(原始论文 240708)
- 高维临床数据(HDCD):例如肺功能图、光电容积脉搏波图(PPG)、心电图(ECG)、计算机断层扫描和磁共振成像等无法用单一的二元值或连续数值来概括的数据
- REGLE 是一种无监督深度学习模型,可用于遗传发现的低维嵌入表示学习,这些嵌入成为全基因组关联研究(GWAS,类似于统计学中的单因素/多因素分析)的输入,用于监督机器学习模型预测
- REGLE 的实现步骤:(1)利用变分自编码器 VAE 压缩和重建 HDCD,学习 HDCD 的非线性解耦嵌入(2)将嵌入编码坐标独立进行全基因组关联分析(GWAS)(3)训练一个小型线性模型来学习编码坐标与特定疾病特异性多基因风险评分(PRSs)之间的权重,并用于遗传发现和疾病预测
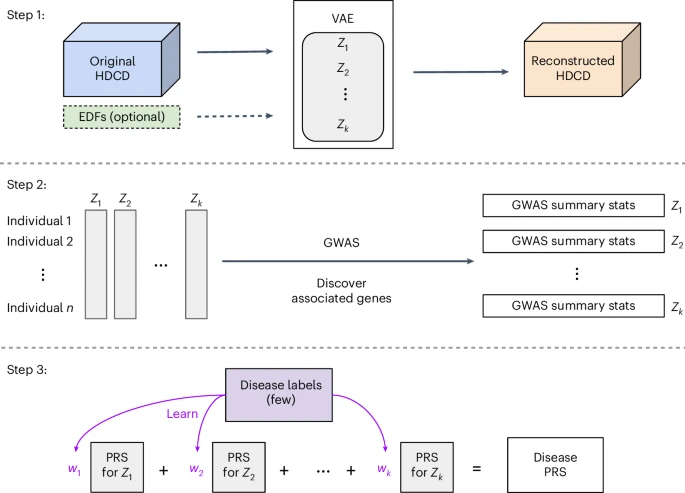
- 结论:REGLE 能在标记有限的数据集中创建准确的疾病特异性多基因风险评分(PRSs);REGLE 能够揭示现有专家定义特征未能捕捉到的特征,从而提高了遗传发现和疾病预测的准确性
DeepVariant:开源的个性化泛基因组分析工具(错误率降低 30%)
3.4 医疗公平性
HEAL 机器学习健康公平性评估框架(原始论文 2404):
- 用于定量评估基于机器学习的医疗工具是否公平地发挥作用,以指导模型开发和现实世界评估
- 其目标是帮助减少不同性别、民族和社会经济背景人群在健康结果方面的差距
4 科学和全球挑战
4.1 人类大脑
Google 与哈佛合作,实现了最大规模的、由人工智能辅助重建的人脑突触水平组织结构

- 该图像显示了兴奋性神经元的三维重建图像,其直径范围为 15-30 微米,并根据神经元细胞体(中心核心)的大小进行着色。该样本宽约 3 毫米
4.2 地球大气
利用数百万部安卓手机收集的聚合传感器测量数据来绘制电离层(原始论文 241113)

- 电离层中的地磁事件,如太阳风暴辐射,可能破坏关键基础设施,即卫星通信和导航系统
- 这项测绘工作将 GPS 定位精度提高数米,并为科学家提供监测站稀疏地区的电离层详细数据
NeuralGCM 大气模拟和气候预测(原始论文 240722):

- 通用环流模型(GCMs)基于物理的模拟器,将大尺度动力学的数值求解器与小尺度过程(如云形成)的调谐表示相结合,可用于求解地球大气的方程,是天气模拟和气候预测的基础
- NeuralGCM 则是将 GCM 与机器学习相结合的混合模型(1)学习编码器,将输入的大气状态、噪音和干扰进行编码(2)动力学模块,用于求解离散化的控制动力学方程,模拟在重力和科里奥利力影响下的大规模流体运动和热力学(3)物理学习模块,使用神经网络预测未解过程(如云形成、辐射传输、降水和亚网格尺度动力学)对模拟场的影响(4)利用隐式-显式常微分方程(ODE)求解器根据动力学和物理学趋势信息,求解下一刻的编码状态(5)学习解码器,将预测的编码状态进行解码,实现大气模型或气候预测
- NeuralGCM 比最先进的物理模型更快速而准确地模拟了地球大气。该模型由欧洲中期天气预报中心合作开发,结合了基于物理的传统建模和机器学习,目前代码已开源
SEEDS 用于气候预测的生成式 AI 模型(原始文章 240329):利用扩散模型加速和提高天气预报。SEEDS 能够显著降低生成集合预报的计算成本,并更好地表征罕见或极端天气事件
4.3 自然灾害
基于 AI 的河流洪水预测(原始论文 240320)
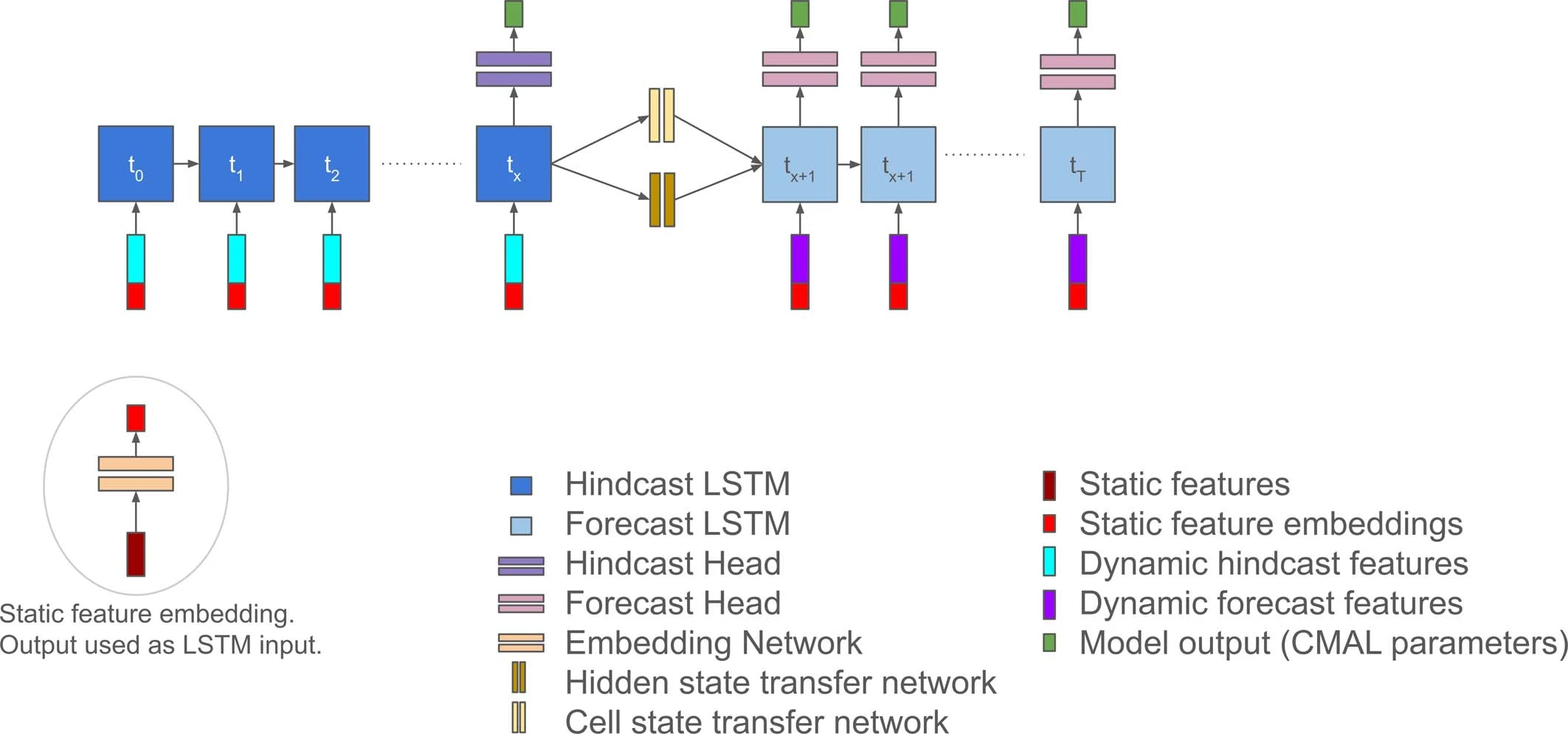
- 本文模型是一个基于 LSTM 网络的编码器-解码器架构,可以预测未来 7 天内的日径流
- 该模型能够在非洲等数据匮乏地区进行全球范围内的河流洪水预测;其改进版本目前为 100 个国家的超过 7 亿处于风险区域的人们提供覆盖,在洪水发生前提供 7 天的预警时间,超越了最先进的模型
野火边界追踪器
- 使用人工智能和卫星图像,并通过搜索、地图和基于位置的推送通知提供关键信息
- 相关的合成训练数据集已开源,数据为高分辨率卫星图像,覆盖了 22 个国家
- FireSat:利用卫星群实时监控野火,能够在二十分钟内检测全球范围内的野火
4.4 人口动态
PDFM 人口动态基础模型(原始文章 241114)
- 基于聚合数据保护隐私的新型地理空间基础模型,其核心为图神经网络(GNN)
- 图构建:一个覆盖美国大陆的图,以县和邮政编码作为节点。每个节点包含相应的人类中心数据、环境数据和地方特征作为特征;节点之间根据邻近节点类型或聚合搜索趋势构建边
- 图训练:使用自监督学习通过消息传递来学习这些位置之间的复杂关系,将每个节点的原始输入信号转换为具有丰富人口动态理解能力的嵌入,为下游任务提供支持
- 实验分析:在多种下游任务中体现较高的性能,体现了 PDFM 嵌入的通用性和灵活性
- 应用方向(1)公共卫生:预测疾病的流行和传播,公共卫生政策制定及资源配置决策(2)零售分析:在决策中考虑人口密度、消费者兴趣和竞争对手存在等因素(3)气候分析:监测森林砍伐、空气质量变化以及气候变化(4)宏观和社会经济指标:表征地区,以优化 GDP 或失业率等指标
5 合作与进步
- 在非洲与世界粮食计划署合作,在 Google.org 的资助下进行粮食安全领域的研究
- 与联合国和 GiveDirectly 合作,将洪水预测和灾害响应技术帮助到当地社区
- 与印度和泰国的伙伴合作开发了一种用于筛查糖尿病患者的 AI 工具,以帮助预防失明
- 跨大陆合作,评估 AI 助手对日本和美国临床工作流程中肺癌筛查的影响