大语言模型(LLMs)的上下文学习:经过预训练的 LLMs 能根据文本提示或任务示例来直接对下游任务进行预测,而无需更新模型权重,这种能力也被称为上下文学习(in-context learning,ICL)或语境学习
简单来说,ICL 就是在不更新模型参数的前提下,通过输入经典示例作为提示来增强模型的能力
以情感分析为例,来说明 ICL 的一般流程(图源):
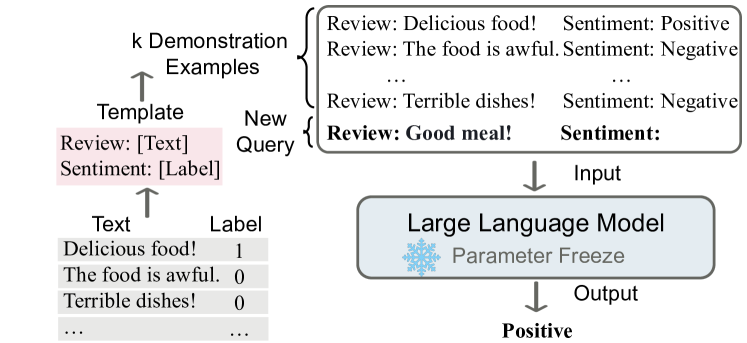
- ICL 需要一些示例来形成一个用于情景演示的上下文,作为提示输入来增强 LLMs
- ICL 示例一般用自然语言模板编写,并拼接真实的输入查询(Text)与结果(Label)
ICL 的分类:
- Few-shot learning,允许输入数条示例和一则任务说明;
- One-shot learning,只允许输入一条示例和一则任务说明;
- Zero-shot learning,不允许输入任何示例,只允许输入一则任务说明
ICL 的效果(以 URIAL 为例):
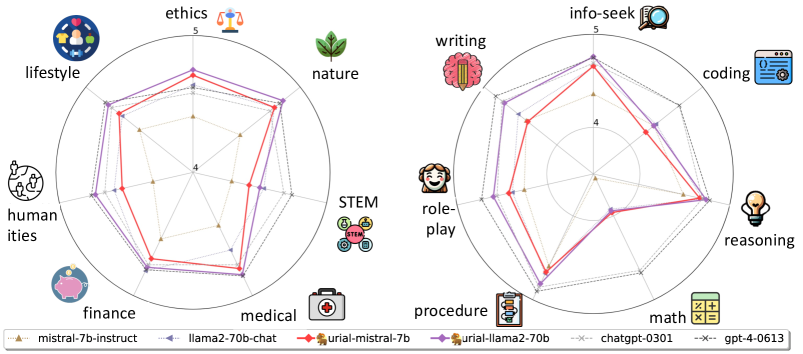
- URIAL:应用三条少量式的示例来进行上下文学习,同时提供系统指令,这些示例包括两个明确的正面示例和一个要求模型避免产生有害回应的敏感示例
- 由上图可以发现,URIAL 能显著改善 LLMs 的性能表现,尤其是在 STEM 和 math 领域
ICL 的理解(进阶阅读):
- LLMs 可以看作元优化器,而 ICL 则可以看作元优化过程,一个隐式的微调过程
- LLMs 可以根据上下文生成元梯度,然后将这些元梯度应用于原始 LLMs 以构建 ICL 模型
ICL 的优点:
- 以示例+提示的方式与 LLMs 进行交互,更贴近人类的学习方式(类比学习)
- 不需要训练或微调,适配新任务的成本低,也变相增强了 LLMs 的泛化性
- 形式灵活,修改方便,通过编辑不同的模板与示例可以适用于不同类型的任务
ICL 的缺点:
- 对上下文敏感,不合理的示例参杂到提示中可能影响模型的最终表现
- 性能提升有限,随着示例数量的增加,模型表现会存在性能饱和问题
- 受到模型的输入维度的上限约束,缺少 ICL 相关的深入理论和实验分析
ICL 的进阶:
- DAWN-ICL:利用蒙特卡洛树搜索 MCTS 来规划路径,寻找用于 ICL 的最佳示例
- 提示工程 Prompt 、1_study/DeepLearning/上下文工程/思维链 CoT 技术、检索增强 RAG 都是 ICL 的应用
扩展阅读:
- CS224W 图机器学习16 PART1:图上下文学习框架
- TabPFN 表格数据基础大模型:利用了 Transformer 的 ICL 能力
参考:
A Survey on In-context Learning
Is In-Context Learning Sufficient for Instruction Following in LLMs?