中文标题:模型融合配方的迭代优化
英文标题:Evolutionary Optimization of Model Merging Recipes
发布平台:预印本
发布日期:2024-03-19
引用量(非实时):
DOI:
作者:Takuya Akiba, Makoto Shing, Yujin Tang, Qi Sun, David Ha
文章类型:preprint
品读时间:2024-03-28 11:11
1 文章萃取
1.1 核心观点
本文提出了一种利用进化算法来促进基础模型合并的通用方法,该方法能够导航参数空间(权重)和数据流空间(推理路径),自动发现不同开源模型的最佳组合。利用开源模型的集体智慧,在无需大规模训练和计算的情况下,跨领域构建具有用户指定功能的强大基础模型。
实验分析表明,基于本文方法得到的新基础模型性能表现出色,同时具备不俗的泛化能力;其中具备数学推理能力的 7B 日语 LLMs 在基准测试上,超越了之前的 70B 参数量的日语 LLMs;日语视觉语言模型(VLM)也在日语数据集上取得了最佳结果,并具备日本特定文化的处理能力

1.2 综合评价
- 提出了一种自动化的模型融合框架,最终的融合效果出色
- 在模型融合的方法上创新点较少,主要是对已有方法的融会贯通
- 仅考虑的日语环境下的评测,说明了模型的有效性但证据程度一般
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 算法细节
前置知识:模型融合 ModelMerge
本文的目标是提出一个统一框架:
- 从基础模型中自动融合模型,并使得融合后的模型性能超越单个基础模型
- 该框架主要考虑到两种融合的维度:参数空间(权重)和数据流空间(推理路径)
本文方法的示意图:
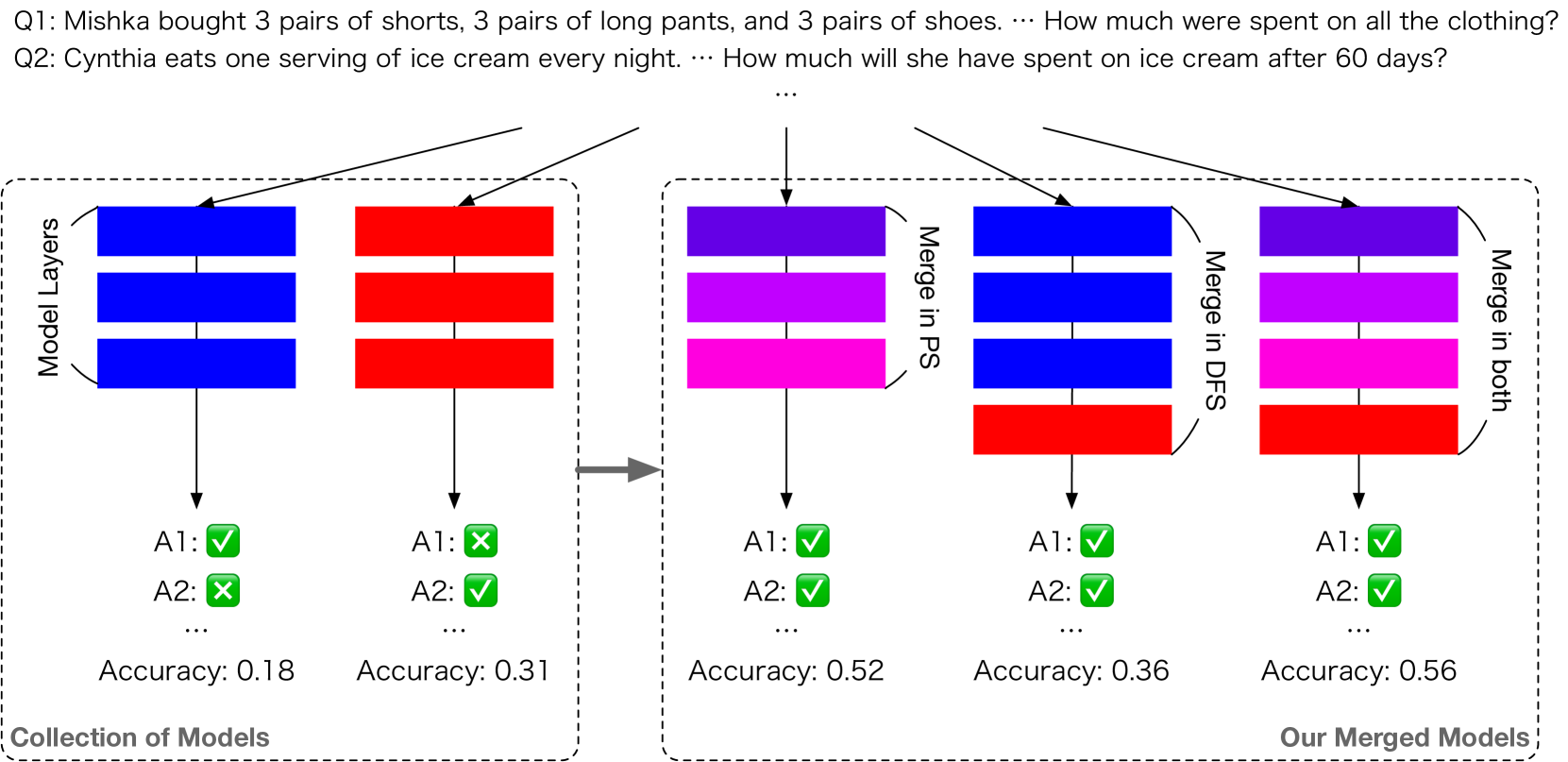
- 方法 1(Merge in PS):改进参数空间(PS)中每一层混合参数的权重
- 方法 2(Merge in DFS):在数据流空间(DFS)中不断演化层的不同排列
- 综合策略(Merge in both):结合 PS 和 DFS 中的两种合并方法
注意,本文提出的融合框架主要针对日语环境;为了方便阅读才将日语语料翻译成英文
方法 1(Merge in PS)细节:参数空间的合并
- 用 DARE 增强了 TIES-Merging,允许更细粒度、分层的合并
- 为每一层(输入/输出嵌入层/Transformer 块)的稀疏化和权重建立融合的配置参数
- 在关键任务特定指标的指导下,使用 1_study/MachineLearning/模型开发技巧/自动化调参#5.1 CMA-ES算法 等进化算法针对选定任务优化配置参数
方法 2(Merge in DFS)细节:数据流空间的合并
- DFS 的合并会完整保留每层的原始权重,主要调整 token 输入神经网络后的推理路径(例如,在模型 $A$ 中的第 $i$ 层之后,token 可以被定向到模型 $B$ 中的第 $j$ 层)
- 假设模型的总层数为 M,将模型的所有层按顺序排列(第 $i$ 个模型的所有层,后面跟着第 $i+1$ 个模型的所有层)并重复 $r$ 次,最终得到长度为 $T=M\times r$ 的序列
- 遍历序列,并通过进化搜索算法依次给出每一个层是保留还是遗弃;该过程对应的搜索空间为 $2^T$,最终得到的指示符(保留/遗弃)数组 $g$ 描述了融合后模型的推理路径
- 对每层输入进行自适应缩放能改善模型的融合表现,定义 $W\in R^{M \times M}$ 来描述任意两层间串接后需要进行的缩放权重;当 $M$ 较大时,可进化一个额外的前馈网络来预测缩放权重
本文对 DFS 的优化主要限制在串接方式和非自适应配置上,暂未涉及其他更灵活的融合
其他初步研究结论:
- 特征与知识在语言模型中是分布式存储,这为 DFS 融合提供了可能
- 模型层的重复或打乱可能导致模型性能的下降,越靠前的层影响越大
- 交换语言模型中的相邻层会导致其性能下降,对输入的适当缩放能缓解此问题
综合策略(Merge in both)细节:
- PS 和 DFS 中的模型融合方法是正交的,因而二者可以自由组合
- 一般先应用 PS 融合,然后将得到的新模型放回模型集合中在应用 DFS 融合
- 对于多目标的模型融合,可以先根据不同目标分别进行 PS 融合;然后借助多目标遗传算法(比如 1_study/MachineLearning/模型开发技巧/自动化调参#5.2 NSGA 算法)进行 DFS 融合,得到多目标优化后的融合模型
2.2 实验分析
一组原始模型:shisa-gamma-7b-v1(日语 LLM)、WizardMath-7B-V1.1 和 Abel-7B-002
以上原始模型均来自 Mistral-7B-v0.1 的微调
评测数据集:MGSM数据集 -日语子集(数学问题解答)
评估方式: zero-shot & 数值正确 & 日语书写(依赖 fasttext 模型)
模型表现对比:
| Id. | Model | Type | Size | MGSM-JA (acc ↑) | JP-LMEH (avg ↑) | |
|---|---|---|---|---|---|---|
| 1 | Shisa Gamma 7B v1 | JA general | 7B | 9.6 | 66.1 | |
| 2 | WizardMath 7B v1.1 | EN math | 7B | 18.4 | 60.1 | |
| 3 | Abel 7B 002 | EN math | 7B | 30.0 | 56.5 | |
| 4 | Ours (PS) | 1 + 2 + 3 | 7B | 52.0 | 70.5 | |
| 5 | Ours (DFS) | 3 + 1 | 10B | 36.4 | 53.2 | |
| 6 | Ours (PS+DFS) | 4 + 1 | 10B | 55.2 | 66.2 | |
| 7 | Llama 2 70B | EN general | 70B | 18.0 | 64.5 | |
| 8 | Japanese StableLM 70B | JA general | 70B | 17.2 | 68.3 | |
| 9 | Swallow 70B | JA general | 70B | 13.6 | 71.5 | |
| 10 | GPT-3.5 | commercial | - | 50.4 | - | |
| 11 | GPT-4 | commercial | - | 78.8 | - |
- 模型 1 具备日语理解能力,但不具备数学推理能力;模型 2/3 则相反
- 模型 4/5/6 为融合模型,展现了日语数学推理能力的显著改善(PS 融合更重要)
250 道测试题的得分分布:
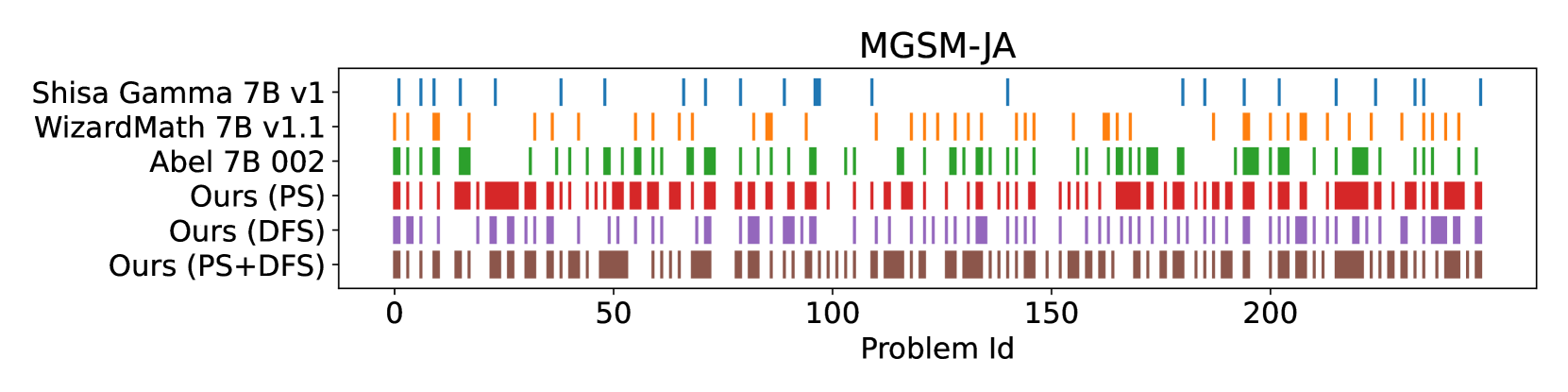
- 上图横轴表示了 250 道测试题,图中标色的部分表示模型答对的部分
- 融合模型保留了源模型中的基础知识,因此问题的得分模式是相似的(尤其是前 15 道)
- 通过有效地整合日语 LLM 和数学模型,本文成功地生成了理解日语并解决数学问题的模型
九项日语相关基础能力评测:
| Model | Size | JComQA | JNLI | MARC | JSQuAD | JAQKET | XLSum | XWino | MGSM | JCoLA | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Shisa Gamma 7b v1 | 7B | 91.2 | 72.1 | 94.6 | 73.9 | 68.0 | 25.9 | 80.5 | 29.6 | 58.7 | 66.1 |
| WizardMath 7B V1.1 | 7B | 74.7 | 42.7 | 90.4 | 84.6 | 68.5 | 22.3 | 69.8 | 38.8 | 48.9 | 60.1 |
| Abel 7B 002 | 7B | 70.3 | 51.8 | 62.3 | 83.8 | 69.0 | 22.5 | 68.2 | 28.0 | 52.7 | 56.5 |
| Ours (PS) | 7B | 89.1 | 65.7 | 95.4 | 89.5 | 77.7 | 25.5 | 81.2 | 50.0 | 60.5 | 70.5 |
| Ours (DFS) | 10B | 67.7 | 58.2 | 53.5 | 66.8 | 54.3 | 17.3 | 65.6 | 30.0 | 65.6 | 53.2 |
| Ours (PS+DFS) | 10B | 88.2 | 50.3 | 91.5 | 78.6 | 77.8 | 23.2 | 73.0 | 40.0 | 73.0 | 66.2 |
| Llama 2 70B | 70B | 80.2 | 53.4 | 94.4 | 91.6 | 80.1 | 21.8 | 73.6 | 30.4 | 54.6 | 64.5 |
| Japanese Stable LM 70B | 70B | 91.2 | 50.4 | 92.9 | 87.1 | 88.4 | 24.3 | 82.0 | 37.2 | 61.7 | 68.3 |
| Swallow 70B | 70B | 95.3 | 57.2 | 91.7 | 94.1 | 93.9 | 23.1 | 83.3 | 45.2 | 59.5 | 71.5 |
通过类似的思路,本文也融合了一个视觉大模型,其性能表现如下:
| Model | (ROUGE-L ↑) | (ROUGE-L ↑) |
|---|---|---|
| LLaVA 1.6 Mistral 7B | 14.3 | 41.1 |
| Japanese Stable VLM | - | 40.5 |
| Ours | 19.7 | 51.2 |
- 其中第一列评估了一般图像问答(VQA)能力
- 第二列评估了日本文化背景下的图像问答(VQA)能力
其他分析或总结:
- 可能是由于数据集有限,随着配置复杂性增加,没有看到相应的性能显着改进
- 三个原始模型均对最终的融合模型有重要影响,其中日语 LLM 的影响相对更强
- 缩放参数对模型性能起到了关键作用,消融该部分会导致 20%+的性能下降
- 局限性:融合模型可能产生缺乏逻辑连贯性或存在缺陷的回复
- 神经网络架构搜索(NAS)与模型融合有紧密联系,也具有较强的借鉴意义