AlpacaEval:主流大语言模型评测
AlpacaEval是一种由斯坦福大小推出的LLM自动评估工具
- 其特点是快速、廉价且可靠
- AlpacaEval 与真实人类注释的一致性很高
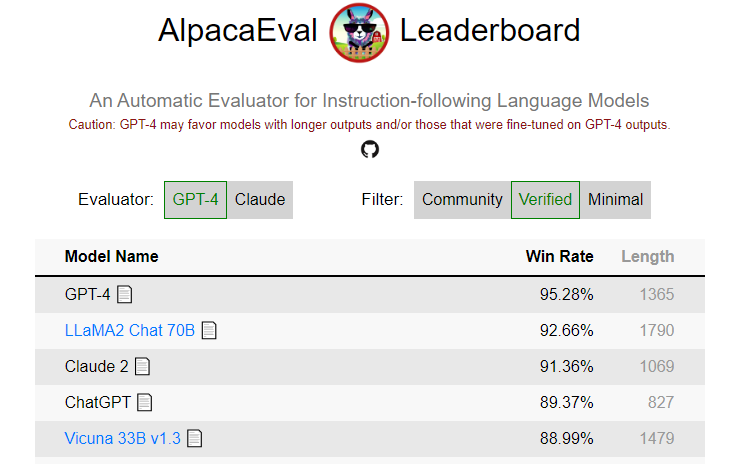
- 2023-09-20 Xwin-LM在 AlpacaEval 上基准测试中超越 GPT-4,排名 TOP-1
知识理解
MMLU:多语言知识理解
该数据集由 UC 伯克利的研究者开发发表在 ICLR 2021 会议,共计「包含了 57 个不同的任务,涉及基础数学、美国历史、计算机科学、法律等多个领域」。为了在这项测试中取得高分,模型必须具备广泛的世界知识和推理能力。除此之外,俄勒冈大学大学基于该数据集还开发了多语言的 MMLU 数据集,共计包含26种语言
知识推理
MGSM:多语言数学推理问答
一个用于评估和训练多语言数学问题解答能力的基准。该数据集由 Google 发布,包含250个来自 GSM8K(Grade School Math 8K)的问题,这些问题通过人工注释者翻译成了「10种不同的语言」
这个数据集适用于开发和测试多语言问答系统,尤其是在教育技术领域,可以帮助开发能够理解和解答不同语言数学问题的AI系统,以探索和改进多语言自然语言处理(NLP)模型在数学问题解答方面的表现
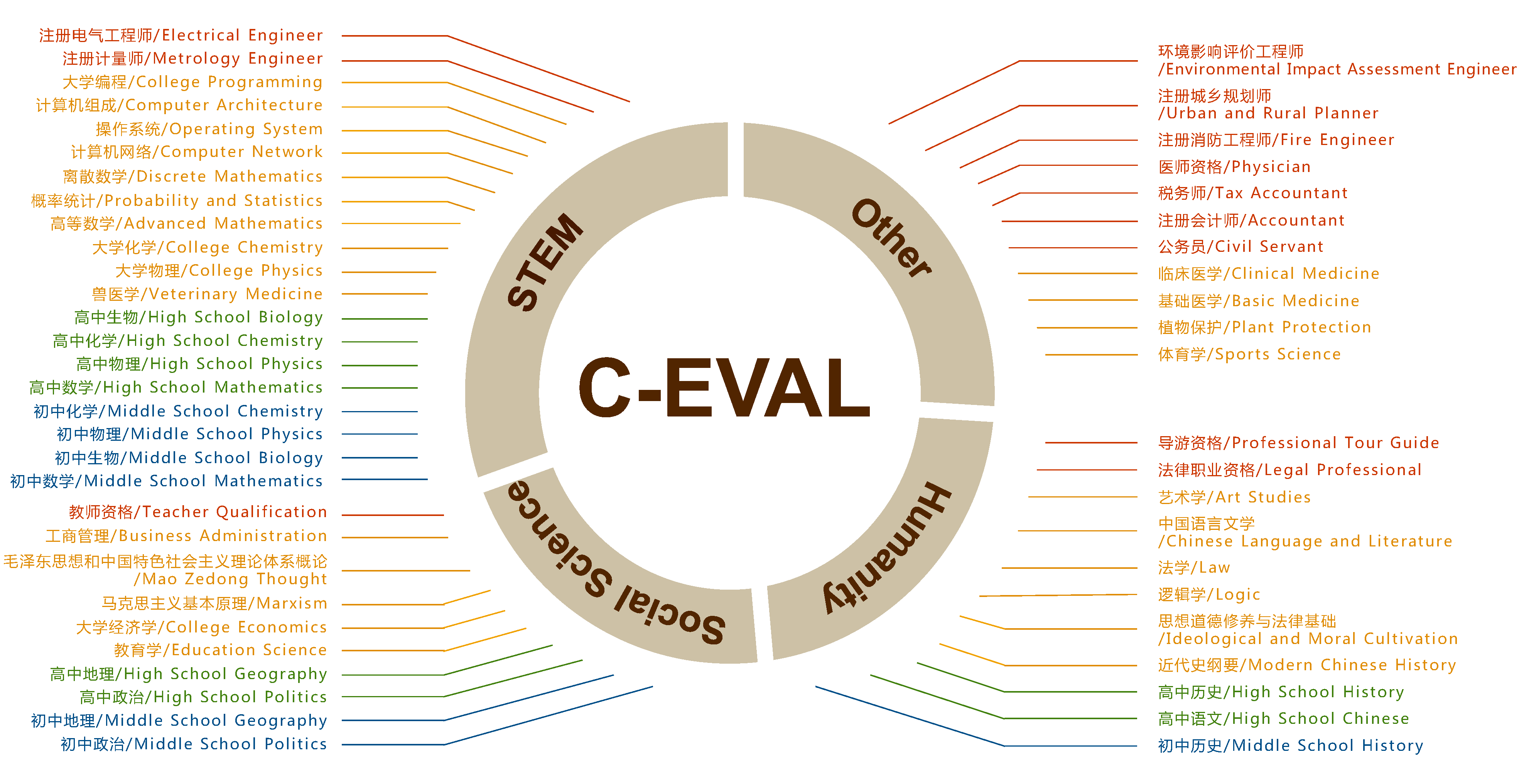
C-Eval:中文知识推理评测
C-Eval是全面的中文基础模型评估套件,涵盖了52学科的13948道多选题,分四个难度级别
常识推理
HellaSwag:常识自然语言推理
该数据集是由斯坦福大学研究人员提出的,用于「评估 NLP 模型在常识自然语言推理(NLI)任务上的性能」,旨在促进 NLP 领域在常识理解和推理方面的发展,特别是在开发能够模拟人类常识推理的 AI 系统方面。该数据集包含了约「10 万个问答对」,这些问题虽然对人类来说非常简单,但对现有的 NLP 模型来说却极具挑战性。
HellaSwag 支持的任务包括句子完成和文本生成,要求模型能够基于上下文生成合理的续写。数据集的结构详细记录了活动标签、上下文、候选续写以及多个可能的结尾,还包括源 ID、数据集分割和标签等信息。数据集遵循 MIT 许可证,允许研究者自由使用。
代码生成
HumanEval:164 个 Python 编程问题
该数据集是由 OpenAI、Anthropic 等开发的一个代码生成评测基准测试,它包含了 164 个人工编写的「Python 编程」问题。这个数据集旨在评估大型语言模型在代码生成方面的能力,特别是在解决实际编程任务方面的表现。每个编程问题都包括函数头、docstrings(文档字符串,用于描述函数的功能)、函数体和几个单元测试。这些问题覆盖了从基础的字符串操作到复杂的算法设计等多种编程任务。
在评测过程中,模型会针对每个单元测试问题生成多个(k 个)代码样本。如果有任何样本通过单元测试,则认为问题已解决,并报告问题解决的总比例,即 Pass@k 得分。这个指标可以帮助评估模型在生成正确代码方面的能力
真人打分
LMSYS 大模型斗兽场
LMSYS Chatbot Arena 是一个用于LLM 评估的众包开放平台。我们收集了超过 1,000,000 次人类成对比较,使用 Bradley-Terry 模型对 LLMs 进行排名,并以 Elo 尺度显示模型评级