随着 AI 模型的能力提升,人类需要一些更有趣的测试集来刁难他们~
GAIA:466个精心设计的问题和答案
SWE-BENCH:2294 个 GitHub 真实问题
SWE-bench 是一个在现实软件工程(GitHub)环境中评估 LMs 的基准
- 模型的任务是解决提交到流行 GitHub 项目的问题(通常是错误报告或功能请求)
- 每个任务的解决方案都会生成一个 PR,描述要应用于现有代码库的更改
- 最后,使用当前 GitHub 项目的测试框架评估修改后的代码
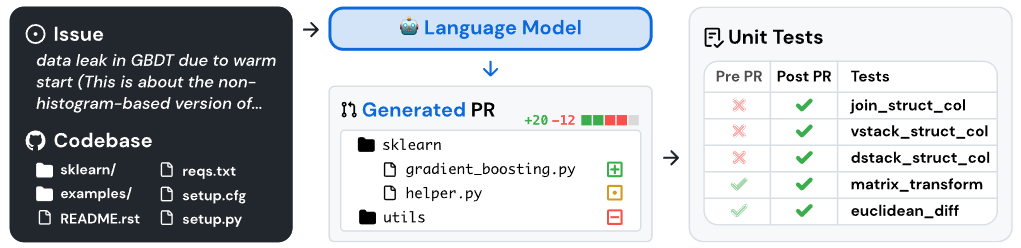 SWE-bench 通过将 GitHub 问题连接到解决相关测试的合并拉取请求解决方案,从现实世界的 Python 存储库中获取任务实例。提供问题文本和代码库快照后,模型会生成一个补丁,并根据实际测试进行评估。
SWE-bench 通过将 GitHub 问题连接到解决相关测试的合并拉取请求解决方案,从现实世界的 Python 存储库中获取任务实例。提供问题文本和代码库快照后,模型会生成一个补丁,并根据实际测试进行评估。
寻找高质量的任务实例(三个步骤):
- 从 GitHub 上 12 个流行的开源 Python 项目收集拉取请求(约 90,000 个 PR)
- 过滤筛选已合并(
merge)的 PR(确保PR解决了问题,并有相关的测试代码改动) - 根据实际的执行情况进行过滤(安装或运行错误/测试缺失、不通过或不一致)

不同模型的最终基准表现:
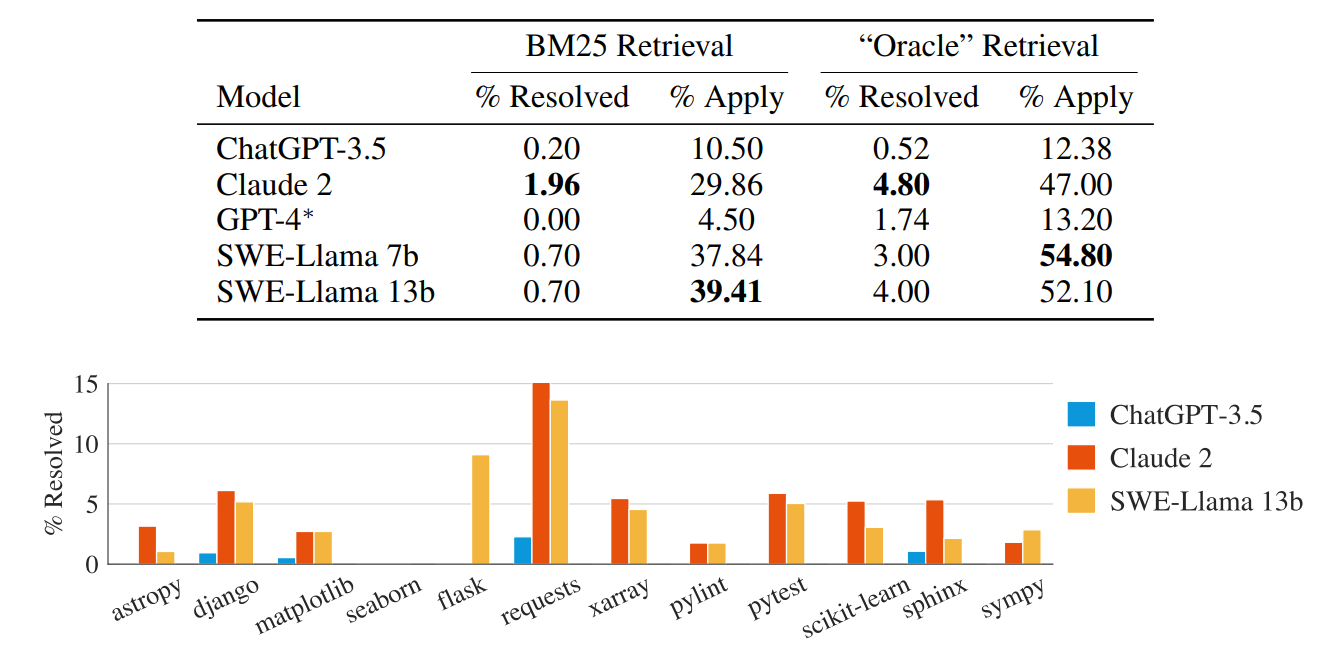
- GPT-4 解决随机 GitHub 问题的通过率是0%(有点奇怪,比 ChatGPT-3.5 还低)
- 即使是最佳模型 Claude 2,也只能解决其中 1.96% 的问题而已
- 不同的模型,在解决12个流行的 Python 库问题的性能,也有所差异
- 该基准测试表明,目前大模型具备的代码生成和问题解决能力还达不到取代程序员的地步