中文标题:Genie: 生成式交互环境
英文标题:Genie: Generative Interactive Environments
发布平台:预印本
发布日期:2024-02-23
引用量(非实时):
DOI:
作者:Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder Singh, Tim Rocktaschel
文章类型:preprint
品读时间:2024-03-05 14:35
1 文章萃取
1.1 核心观点
Genie 是第一个通过无标签的互联网视频以无监督方式训练的生成交互环境。该模型可以被提示生成无数种通过文本、合成图像、照片甚至草图描述的动作可控的虚拟世界。Genie 能通过无标注数据进行潜在动作的学习,使用户能够在生成的环境中实现逐帧操作
Genie 可以被视为包含 11B 参数的基础世界模型,由视频标记器、动力学模型和简单且可扩展的潜在动作模型组成。其中视频标记器将多帧图像信息转化为离散标记,而动力学模型则用于未来帧的信息预测,潜在动作模型则通过连续两帧间的信息变动,捕捉背后的潜在动作。
1.2 综合评价
- 本文提出了一种生成视频的新范式,可交互性在游戏和机器人领域大有可为
- 本文的数据集依赖 2D 游戏视频,但具备向手绘、真实视频、机器人泛化的能力
- 本文训练所涉及的潜在动作维度较少,生成视频的质量较差,存在继续完善的空间
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
前置知识:ST-transformer 架构
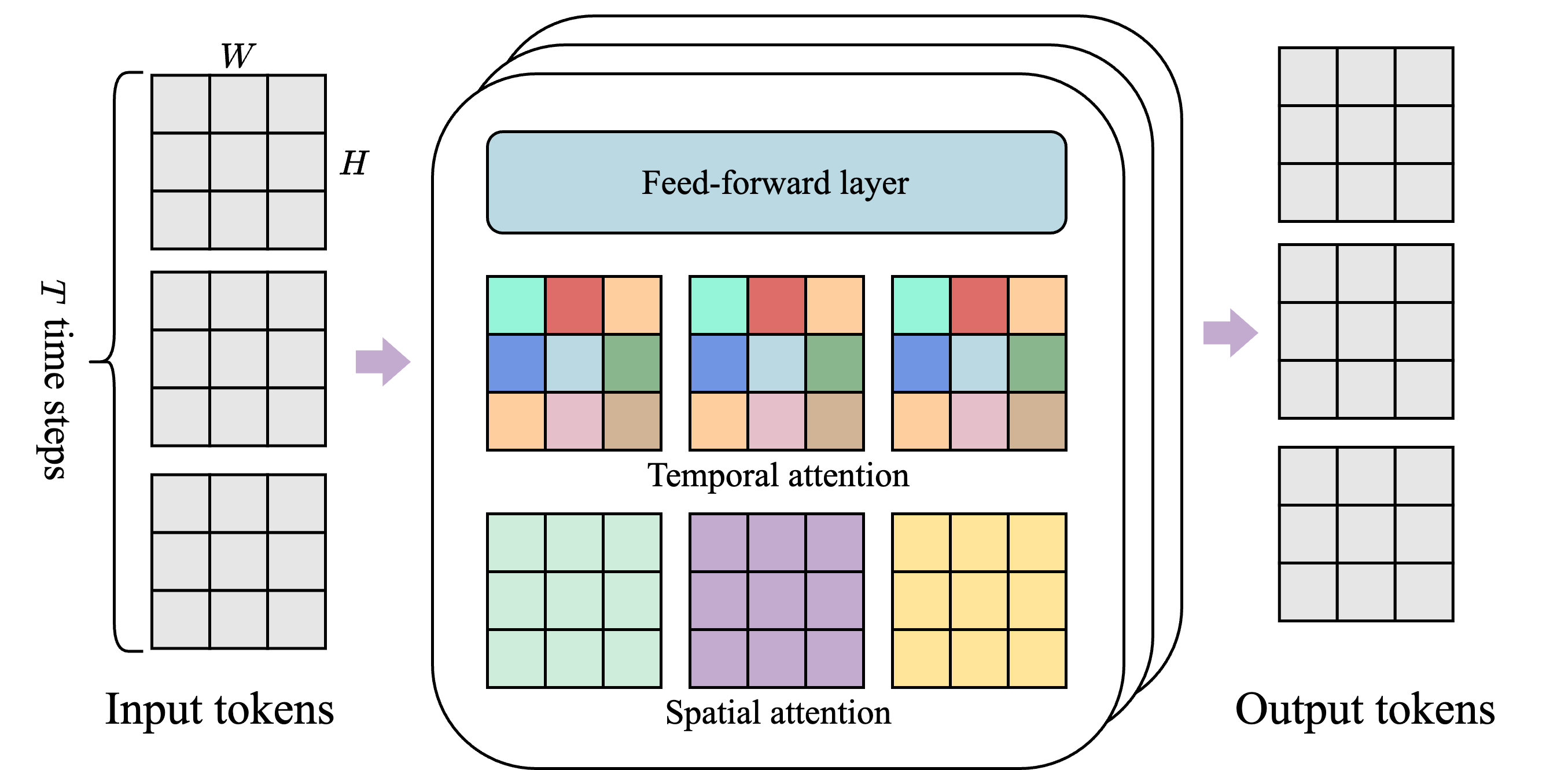
- 该架构由 $L$ 时空块组成,每个块包含空间层、时间层和前馈层
- 空间层(Spatial)关注单个时间步内的 $1\times H\times W$ 个标记
- 时间层(Temporal)关注 $T$ 个时间步内的 $T \times 1\times 1$ 个标记
- 每种颜色代表一个单独的自注意力图;
- 后续实验表明,前馈层(FFW)保持单层能显著改善结果
前置知识:VQ-VAE
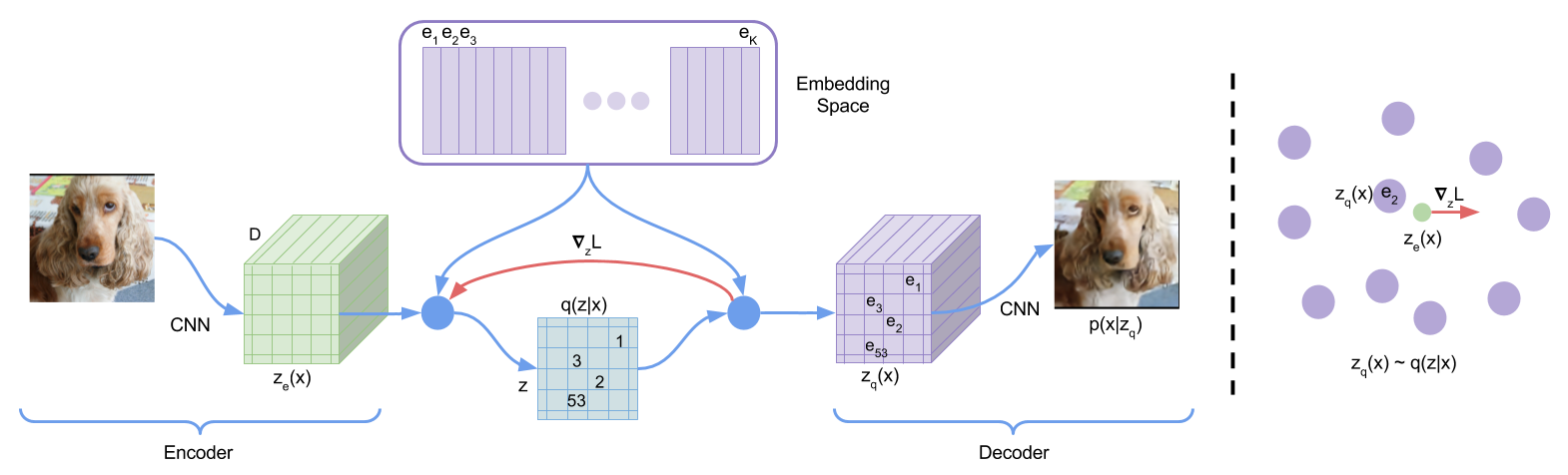
- 在1_study/DeepLearning/生成式神经网络#变分自编码器 VAE 的基础上,引入了编码表(CodeBook)
- 编码后的结果是离散的整数,而每个离散值都对应一个稠密向量
- 解码时,解码器先通过编码表进行最近邻搜索,然后根据离散编码实现原始信息重构
- VQ-VAE 还引入直通估计(Straight-Through Estimator)机制来忽略最近邻搜索的梯度
前置知识:MaskGIT

- 传统生成式 Transformer 将图像视为 token 序列,并按照光栅扫描顺序(即逐行)解码图像
- MaskGIT 则借助双向 Transformer 以非自回归解码的方式,逐步合成图像;每一次迭代中,模型都会并行预测所有的 token,但只保留最自信的 token 并遮蔽剩余部分用于下一次迭代的预测
- 在训练阶段,MaskGIT 通过关注各个方向的标记来学习预测随机屏蔽的标记
- 在推理阶段,模型首先同时生成图像的所有标记,然后以上一代为条件迭代地细化图像
2.2 算法细节
Genie 模型包含三个关键组件:
- 潜在动作模型,用于推断每对帧之间的潜在动作 𝒂
- 视频标记器,用于原始视频帧 $x$ 和离散标记 𝒛 之间的转换(编码/解码)
- 动力学模型,根据潜在动作和过去的帧标记,预测视频的下一帧
潜在动作模型(latent action model,LAM):
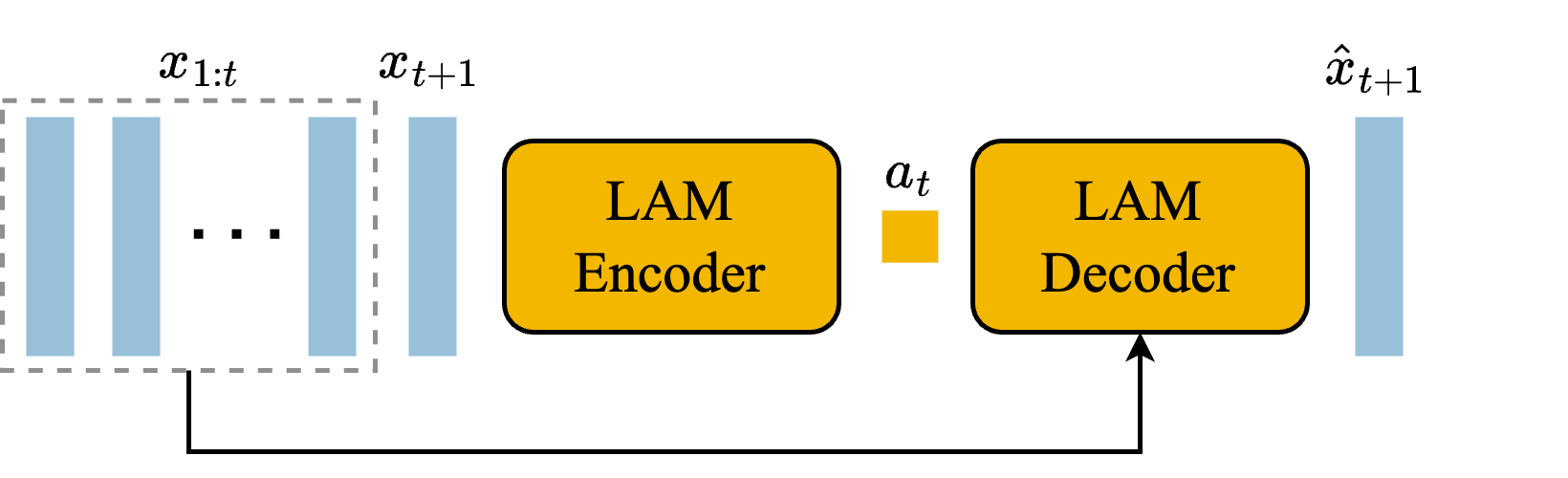
- 编码器将历史帧 $x_{1:t}$ 和下一帧 $x_{t+1}$ 作为输入,输出一组潜在动作 $(a_1,...,a_t)$
- 将潜在行为视为潜在行为和动力学模型的附加嵌入有助于提高各代的可控性解码器根据历史帧 $x_{1:t}$ 和潜在动作作为输入,尽量准确地预测下一帧 $\hat{x}_{t+1}$
- 在本文中,限定潜在动作的最大数量为 8(允许人类可玩性,增强可控性)
- 沿用标准 VQ-VAE 的损失函数,并通过 ST-transformer 确保模型对时空的理解
视频标记器(Video Tokenizer):

- 沿用标准 VQ-VAE 的损失函数,将视频的 $T$ 帧信息 $x$ 降维压缩为离散标记$z$
- 编码器和解码器中都使用 ST-transforme 来考虑时间的动态,提高视频生成质量
动力学模型(Dynamics Model):
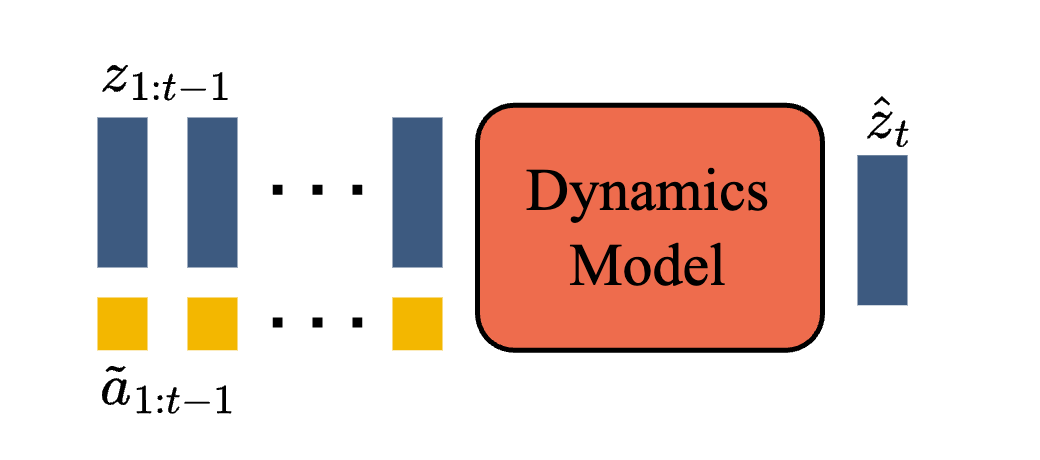
- 动力学模型是一个仅包含解码器的 MaskGIT Transformer;在每个时间步骤,模型都根据视频的离散标记 $z$ 和潜在动作 $a$ 并预测下一帧的离散标记 $\hat{z}$
- 动力学模型使用预测标记 $\hat{z}$ 和真实标记 $z$ 之间的交叉熵损失进行训练
- 将潜在行为作为动力学模型的附加嵌入有助于提高生成结果的可控性
Genie 模型的推理过程:
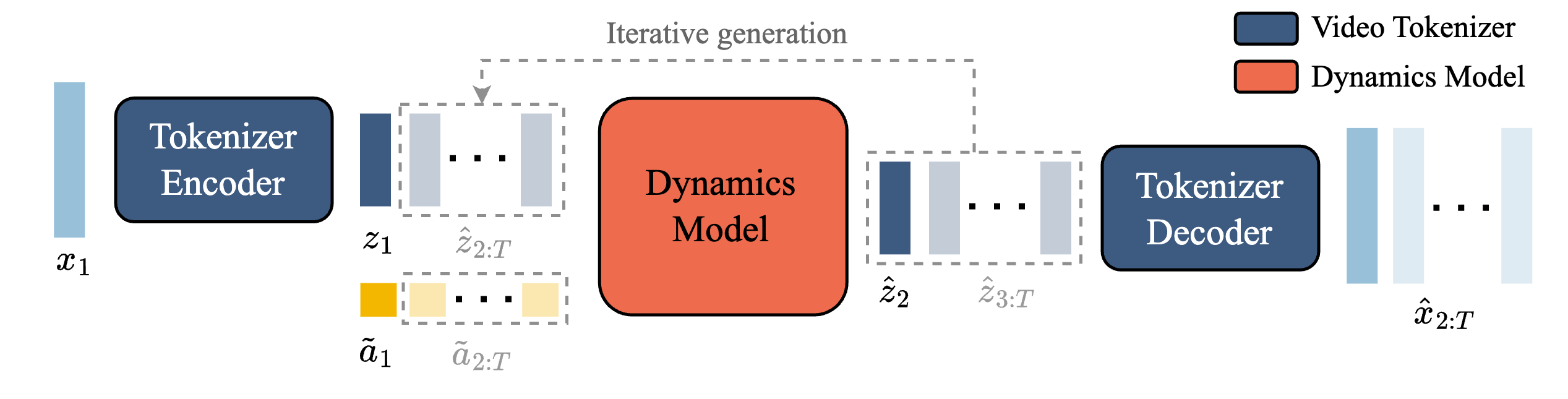
- 提示帧 $x$ 被视频标记器-编码器进行离散标记化 $z$,然后与用户的潜在动作 $a$ 相结合,并传递到动态模型进行迭代生成后续帧的预测标记,最后通过视频标记器-解码器将预测的帧标记解码回图像空间
- 通过干扰或更改动作,Genie 模型能推理生成指定动作发生后的视频 (可交互)
- 注:潜在动作向量 $\tilde{a}_{1}$ 是潜在动作 $a$ 通过 VQ 编码表得到的
2.3 结果分析
数据源:3 万小时的2D 游戏视频,剪辑为680 万个 16 秒视频
补充验证集:用于训练 RT1 Brohan 等人的机器人数据集
评估指标:
- 视频保真度(即视频生成的质量):FVD (Frechet Video Distance)
- 可控性(即潜在动作对视频生成的影响有多大): $\Delta_t PSNR$
FVD (Frechet Video Distance) 通过对深度学习模型生成的视频的时间一致性和每帧质量进行排序评估,与人工判别的一致性在 60% 到 80% 之间(原始论文)
$\Delta_t PSNR$ 是本文基于峰值信噪比 (PSNR) 构建的指标;$\Delta_t PSNR$ 越大,随机潜在动作生成的视频与真实情况的差异越大,这表明潜在动作的可控性水平越高(具体定义可参考原文,此处不再赘述)
不同尺寸或 batch_size 的模型横向对比:
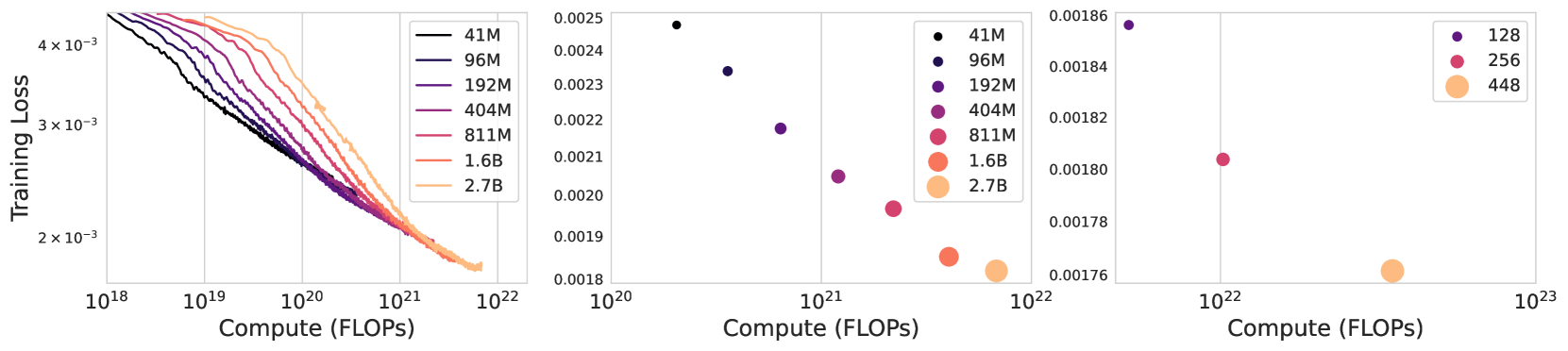
- 左:不同尺寸模型的训练曲线
- 中:不同尺寸模型的最终训练损失
- 右:不同 batch_size 的 2.3B 模型的最终训练损失
可控视频的生成效果:

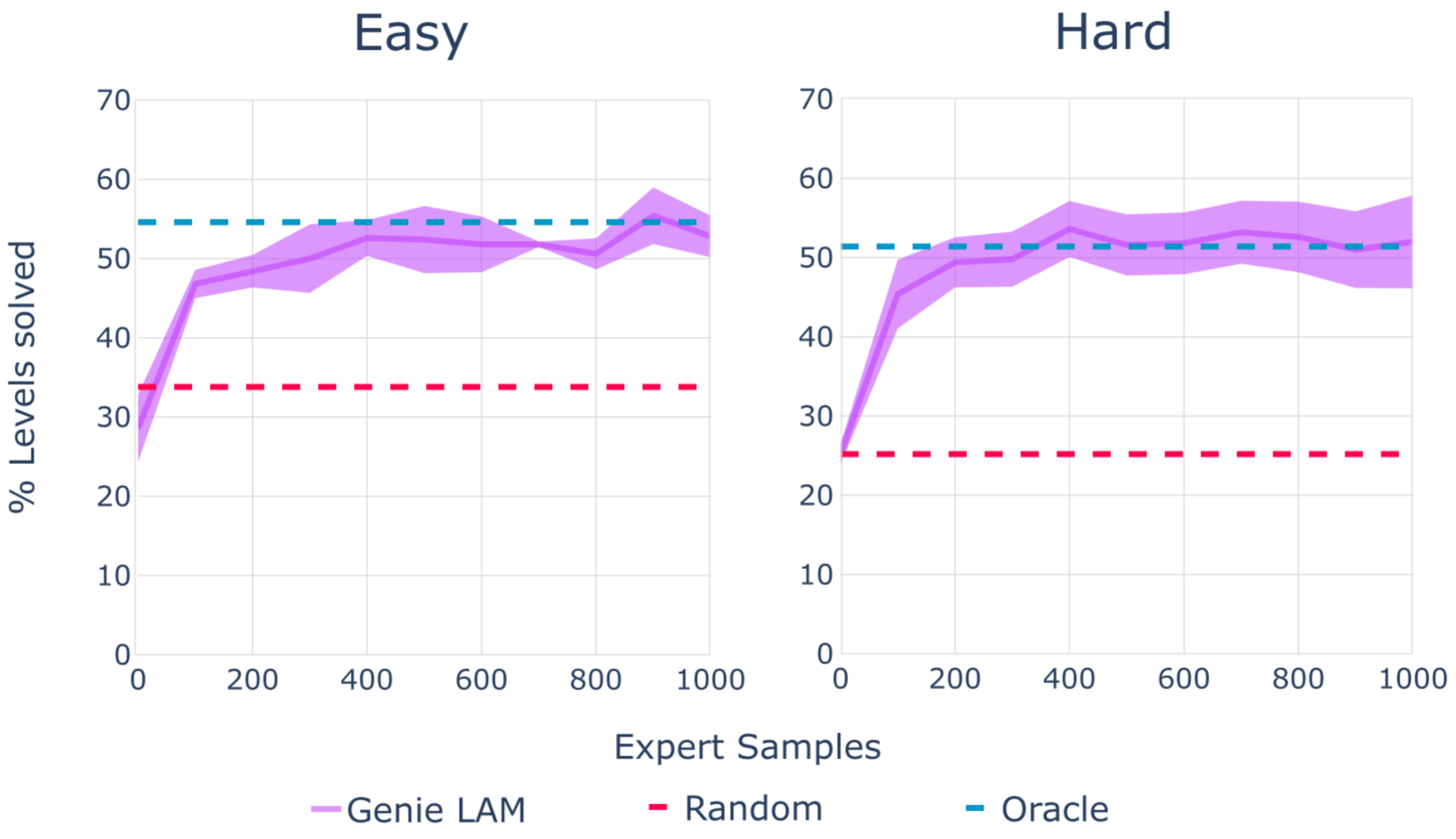
不同游戏环境的模拟得分:学习的潜在动作在迁移过程中是一致且有意义的
不同数据集和输入方式对比:
| 数据集 | 参数量 | FVD (↓) | Δ_t PSNR(↑) | |
|---|---|---|---|---|
| Token-input | Platformers | 2.3B | 38.8 | 1.33 |
| Pixel-input (Genie) | Platformers | 2.5B | 40.1 | 1.91 |
| Token-input | Robotics | 1B | 257.8 | 1.65 |
| Pixel-input (Genie) | Robotics | 1B | 136.4 | 2.07 |
- 相比于传统的 token 序列输入,Gennie 的像素输入在机器人领域更具有优势
消融实验:
| 参数量 | 内存消耗 | FVD (↓) | Δ_t PSNR(↑) | |
|---|---|---|---|---|
| ViT | 230M | 0.3GB | 114.5 | 1.39 |
| C-ViViT | 225M | 1.6GB | 272.7 | 1.37 |
| ST-ViViT (ours) | 205M | 0.9GB | 81.4 | 1.66 |
- ViT 模型未考虑时间因素,因此效果最差
- C-ViViT 使用了完整的时空注意力机制,内存消耗较大
其他定性分析:
- Genie 模型能学习物体的物理特性(模拟一袋薯片的变形)
- Genie 模型能理解 3 D 场景和模拟视差(前景的移动幅度大于近处和远处的中心)
- Genie 模型学会可控、一致的潜在动作(相同的动作在不同的提示帧中是一致的)
- Genie 模型不仅学习机械臂的控制,还学习各种物体的相互作用和变形
3 后记
对 Genie 的思考 + 网络讨论总结
- 基于大量游戏视频进行无监督学习,模型架构更接近本文的世界模型
- 核心点在于生成可交互虚拟世界,根据手柄操作自动精准生成未来帧
- 当前潜在动作空间较小(8 维),可能更适用于现实细分场景的精准控制
- 当前面对的虚拟游戏世界较为简单,并且生成视频的像素质量较差
- 随着视频类型和动作空间的丰富,或者 Gennie 能具备虚拟世界的潜力
- 更多模型细节与评价可参与知乎讨论
20241204:DeepMind 推出 Genie2
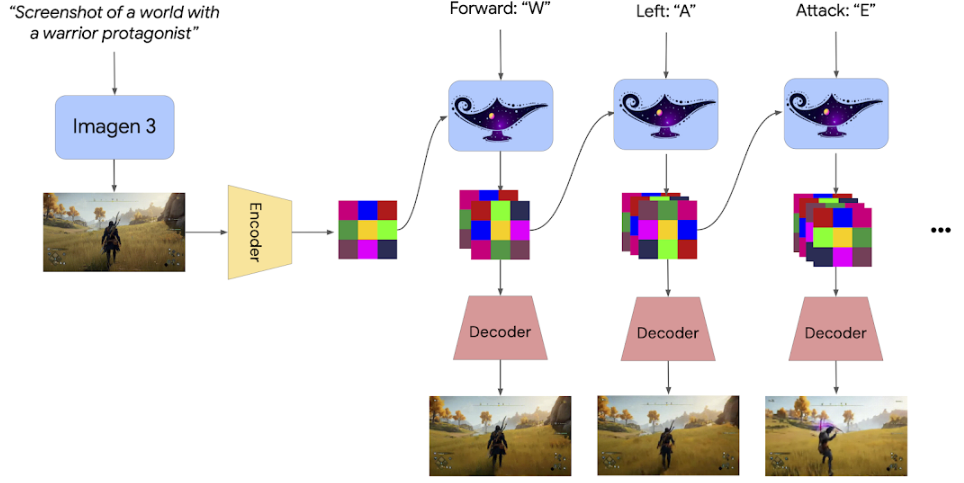
- 根据用户输入的文本描述和图像,实时生成交互式的三维场景
- 模拟虚拟世界,能模拟出采取任何行动(例如跳跃、游泳等)的后果
- 基于单个提示图像,人类或人工智能代理可以使用键盘和鼠标输入来操作
- 生成视频可以是不同视角的,并且最大持续时长为 1 分钟(大部分为 10~20s)
Genie2 应该是根据大量游戏视频+键盘操作学习到的可控式 3D 视频生成
20250805:DeepMind 推出 Genie3

- 给定一个文本提示,Genie 3 可以模拟可交互的动态世界,能够在实时 24 帧每秒的情况下进行 720p 分辨率画面生成;与 Genie 2 相比,在一致性(几分钟)和真实性方面也有所改进
- Genie 3 的主要能力:(1)模拟世界物理属性,包括水流、闪电等自然现象(2)模拟自然生态,从动物行为到错综复杂的植物生命(3)建模动画和小说,创造奇幻场景和富有表现力的动画角色(4)超越地理和时间的界限,探索不同的地方和过去的时代(5)可根据文本提示来改变世界的模拟,比如调整天气条件(6)可用于具身智能的训练,增强兼容性
- Genie 3 的局限性:(1)有限的动作空间,只能通过文本提示来提供广泛的环境干预(2)无法有效的模拟多个独立 Agent 在共享环境中的复杂交互(3)无法实现真实世界位置的地理精准表示(4)无法实时渲染文本,只能在世界初始化描述的时候生成文本(5)模拟时长有限,目前只支持几分钟的连续交互
Genie 3 的生成画面是基于世界描述和用户操作逐帧创建的,能够在几分钟内仍然保持高度一致性,视觉记忆可以追溯到一分钟之前;Genie 3 的连贯性是一种涌现能力
Project Genie:
- 26 年 1 月 30 日,谷歌(Google)正式向美国地区 18 岁以上的 AI Ultra 订阅用户开放 Project Genie 访问权限。该原型应用集成 Genie 3 世界模型、Nano Banana Pro 及 Gemini,支持用户通过文本或图片提示词实时生成并操控虚拟环境
相关资源
- 论文在线地址
- 本地文件地址:Bruce et al_2024_Genie.pdf
- 本地Zotero地址:Bruce et al_2024_Genie.pdf