中文标题:DeepSeek-OCR:上下文光学压缩
英文标题:DeepSeek-OCR: Contexts Optical Compression
发布平台:预印本
发布日期:2025-10-21
引用量(非实时):
DOI:10.48550/arXiv.2510.18234
作者:Haoran Wei, Yaofeng Sun, Yukun Li
关键字: #DeepSeek-OCR
文章类型:preprint
品读时间:2025-11-05 14:29
1 文章萃取
1.1 核心观点
本文借助 DeepSeek-OCR 的研究,对视觉 token 压缩文本的可行性进行了初步研究;DeepSeek-OCR 模型以 DeepEncoder 作为核心组件,实现了高分辨率输入下的低激活开销,确保视觉 token 的数量保持着合理范围;MoE 解码器将DeepEncoder 编码压缩后的信息进行原始文本表示的还原,验证了视觉 token 相对传统文本 token 的信息优势
最终实验表明,相对于文本 token,视觉 token 在保持 10 倍压缩比的情况下,依然能够实现 97%的解码(OCR)精度;而 DeepSeek-OCR 模型也展现出来较高的实用价值,在多样化文档解析的测试中取得了明显优势,在生产环境中单 GPU(A100-40G)能够每天实现 20w+页面的高质量解析
1.2 综合评价
- 论文针对视觉 token 的研究值得深入的思考与研究
- 模型的 OCR 性能出众,使用方式灵活,实用价值高
- 模型架构设计创新较少,主要沿用已验证成熟方案
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 前置知识
前置知识:SAM(2023)

- 由 Meta 提出的 Segment Anything Model,经典的图像分割模型
- SAM 主要包含一个基于 ViT 架构预训练的图像编码器(计算图像嵌入),一个多类型提示编码器(计算提示嵌入,支持点、框和文本等类型),一个带有动态掩码预测头的轻量级掩码解码器(实时预测每个位置的掩码概率)
- SAM 是一个具备里程碑意义的图像分割模型,其零样本泛化能力十分惊艳
前置知识:CLIP(2021)
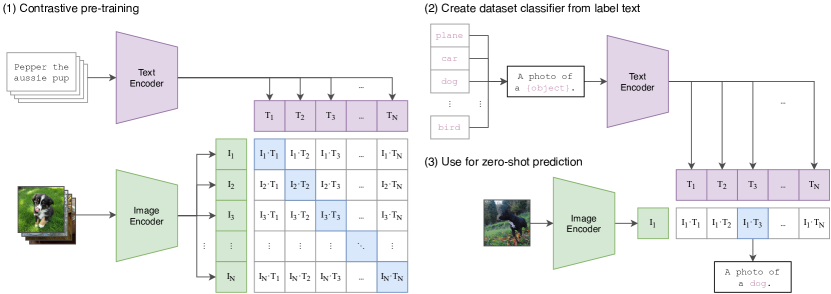
- 由 Open AI 团队提出的基于对比学习的文本-图像对预训练模型
- CLIP 基于海量图像文本(低质量)对进行弱监督训练,实现了较强的zero-shot性能,可以作为预训练模型迁移到图像生成领域
已有的经典视觉编码方案:
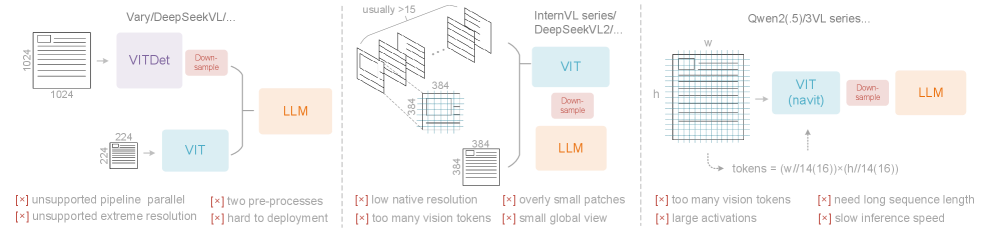
- 以 Vary (左图)为代表的双塔架构:利用并行 SAM(Segment Anything Model) 编码器来增加视觉词汇参数,用于高分辨率图像处理;缺点是需要双图像预处理,部署复杂,并行训练困难
- 以 InternVL2.0 (中间)为代表的图块方法,通过将图像分成小图块进行并行计算来处理图像,从而减少高分辨率下的激活内存;缺点是原始编码器分辨率过低(< 512 × 512),并且过度碎片化的图像导致大量的视觉 token
- 以 Qwen2-VL (右图)为代表的自适应分辨率编码,它采用 NaViT 范式,基于补丁(patch)的分割直接处理全图像,无需碎片并行化,灵活支持不同的分辨率;缺点是激活内存消耗大,容易导致显存移除,同时不适用于图像较大的情况
端到端 OCR 方案
- 伴随着 VLM 的发展,端到端 OCR 成为目前 OCR 系统的主流方案
- Nougat(2023) 首先在 arXiv 学术论文中采用端到端 OCR 框架,展现了模型在专业文档方面的的 OCR 性能潜力(尤其是针对数学公式)
- GOT-OCR2.0(2024)是一款综合功能丰富的端到端 OCR 模型,能够处理文本、图表和乐谱等多种类型的输入,并进行丰富格式的输出,模型中各项 OCR 任务中表现出色
- Qwen-VL、InternVL 等通用视觉模型也在不断增强文档 OCR 能力,探索视觉感知的边界
2.2 算法架构
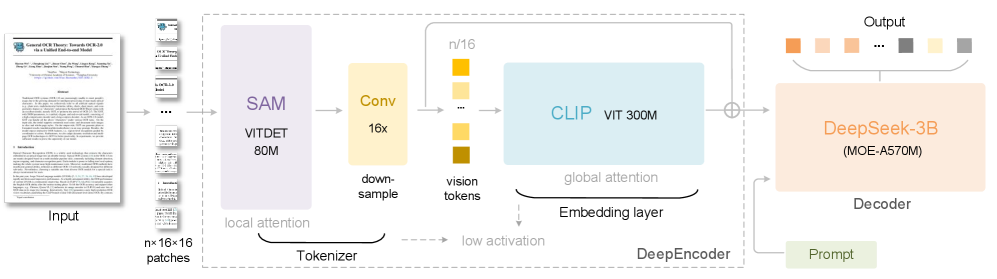
- DeepSeek-OCR 由一个 DeepEncoder 和一个 DeepSeek-3B-MoE 解码器组成
DeepEncoder 是 DeepSeek-OCR 的核心,包含主要三个组件:
- SAM-base 架构,用于以窗口注意力为主的视觉感知特征提取
- CLIP-large 架构,用于具有密集全局注意力的视觉知识特征提取;由于输入不再是图像,而是来自压缩管道的输出 token,因此需要剔除原始的嵌入层
- 一个 16 倍 token 压缩器,用于在 SAM 和 CLIP 之间架起桥梁;主要借鉴了 Vary,采用 2 层卷积模型对输入 token 进行 16 次下采样
DeepEncoder 通过位置编码的动态插值来实现多分辨率模型的同步训练,并确保最终DeepSeek-OCR 模型的多分辨率支持
MoE 解码器
- 解码器主要使用 DeepSeek-3B-MoE,其包含 64 个路由专家
- 模型推理时会激活 6 个路由专家和 2 个共享专家(约 570M 参数)
- 解码器通过 OCR 式的训练有效学习到一种非线性映射,从而根据 DeepEncoder 输出的压缩潜在(视觉) token,重建原始的文本表示
2.3 训练说明
训练数据说明:
- 文档数据:(a)从互联网上收集了 30M 页的多样化 PDF 数据,涵盖约 100 种语言,其中中文和英文约占 25M,其他语言约占 5M;对其中部分中英文档进行精细标注(高级模型交错验证),对其余文档进行粗略标注(普通模型快速标注)(b)收集 3M 的字体数据,直接提取内容来构建高质量的图像-文本对(c)除此之外,还额外补充了一些开源数据
- 自然场景数据:中英文各搜集了 10M,并用PaddleOCR 标注
- 专业类图像数据:使用 pyecharts 和 matplotlib 渲染 10M 图像数据;化学式图像数据 5M,依赖开源数据+渲染工具;平面几何图像 1M,依赖第三方几何图像感知模型生成(Slow Perception)
- 普通图像数据:字幕生成、物体识别和定位等数据,约占总数据的 20%
- 纯文本数据:DeepSeek 内部纯文本预训练数据,约占总数据的 10%
两阶段训练+多节点+数据管道并行:
- 先使用传统 next-token 预测任务独立训练 DeepEncoder
- 再划分 4 个 训练 pipeline 并行训练完整的 DeepSeek-OCR(1)PP0:冻结 SAM 和压缩器,仅作为视觉 token 生成器(2)PP1:训练 CLIP 模型,输出最终的编码 token 给 MoE 解码器(3)PP2 & PP3:共同承担 12 层 MoE 解码器的训练,,每部分各放6层
- 20 个节点训练并行,每个节点有 8 个 A100-40G GPU
- 40 个数据管道并行,保持 40 个相同的模型副本同时训练
2.4 实验评价
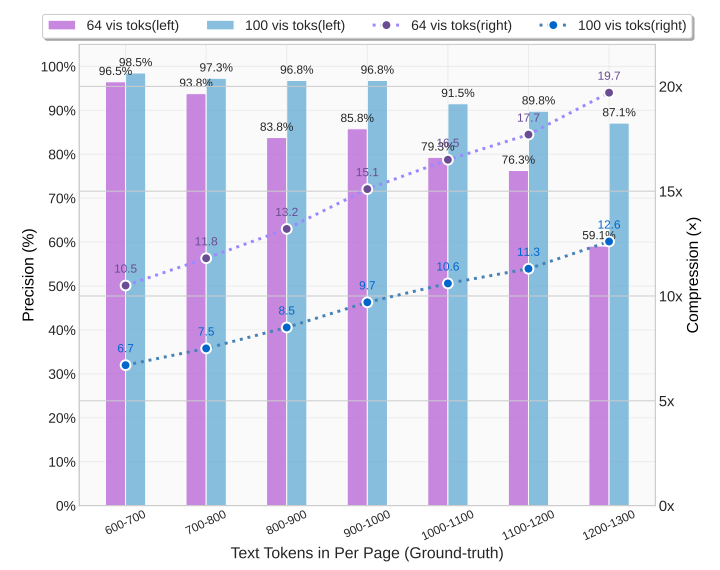
评估视觉 token 相对于文本 token 的压缩率和还原精度
本篇论文的核心思想点:a picture is worth a thousand words(一图胜千言)
不同尺寸 DeepSeek-OCR 的 OCR 性能均实现 SOTA
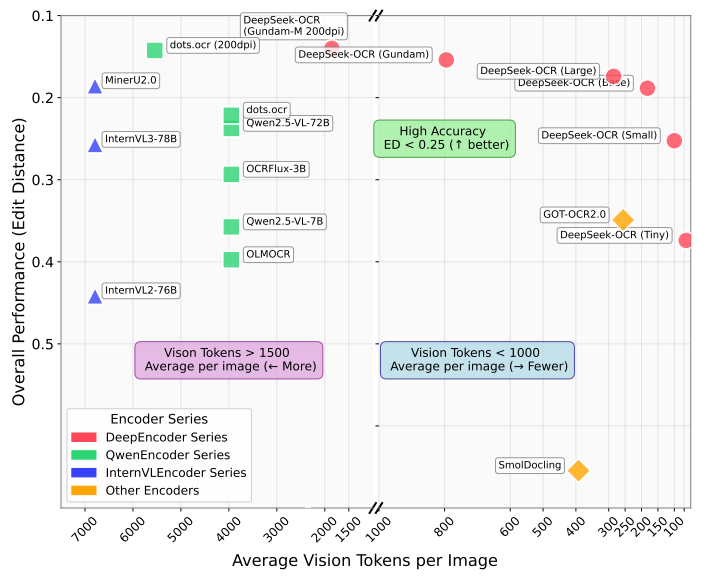
OmniDocBench:评估现实场景中多样化文档解析性能的基准测试
其他总结:
- 视觉 token 的高压缩率和高还原精度,表明该方向非常值得继续研究
- 当压缩率超过 10 倍后,视觉 token 的还原精度明显下降,存在改善空间
- 即使压缩率达到了 20 倍,视觉 token 还原精度依然能保持着 60%左右
- 特定类型的文档,只需要 64 或 100 个视觉 tokne 就能实现较好的 OCR
- 模型支持灵活的提示方式,对特定专业领域的格式也具备深度解析能力
- 模型可以处理近 100 种语言,并具备了一定程度的通用图像理解能力
上下文视觉压缩与人类记忆的衰退过程存在相似之处(1)近期记忆:就像近处的物体,是清晰的高分辨率图像,需要较多的视觉 token(2)远期记忆:就像远处的问题,是逐渐模糊缩小的图像,需要更少的视觉 token(3)从近期记忆到远期记忆,视觉 token 能实现信息的自然遗忘和压缩
后记
网络评论摘录:
- 视觉压缩不仅使上下文更便宜,还使 AI 记忆架构变得可行——Ray Fernando
- 这种统一视觉与语言的方法,或许是通往AGI的大门之一——叶慧雯
- 我相当喜欢新的DeepSeek-OCR论文,它是一个很好的OCR模型。对我来说更有趣的部分是像素是否比文本更适合作为LLM的输入——Andrej Karpathy
相关资源
- 论文在线地址
- 代码开源地址
- 本地文件地址:Preprint PDF
- 本地Zotero地址:Preprint PDF