上下文学习 ICL 是大模型 RAG 的前提基础
朴素 RAG
RAG(retrieval-augmented-generation):基于信息检索的提示词增强技术
RAG 的一般流程:

- 先对文档切分,再借助 Embedding 模型实现知识的向量化存储
- 通过余弦相似度等度量标准,检索与查询向量最相似的文档(召回)
- 重新排序检索到的文档,并只保留最相关的文档(提高 RAG 的质量)
RAG 的方法选型
- Embedding 模型推荐参考 MTEB 排行榜,结合个人需求选择合理的模型
- 检索方案(1)ANN 近似最近邻搜索(2)托管解决方案,比如 OpenSearch、ElasticSearch 或向量数据库(3)高级 RAG 方案,比如 LangChain 等
- RAG 的评估:文本相关性、命中率、召回率、BLEU 、ROUGE 和 MRR 等
RAG 的优点:
- 通过事实类知识的信息增强,减少LLM幻觉
- 数据更安全,提示内容对普通用户不可见
- 不需要微调,即可让模型及时掌握最新的信息
RAG 的缺点:
- RAG 的最终效果受到 Embedding 模型和知识检索结果的质量影响
- 受到 LLMs 本身的模型理解和逻辑能力限制,RAG 只是锦上添花
- 检索依赖的内容可能存在虚假、过时、非权威、术语混淆等问题
GraphRAG
GraphRAG(Graph Retrieval-Augmented Generation,图检索增强生成)
- 由微软团队在 2024 年提出的一种先进 RAG 技术
- GraphRAG 主要依赖 LLM 生成的知识图谱改善问答性能
- 结构化信息提升 LLM 生成内容的准确性、相关性和可解释性
- 该方法在处理复杂信息或专业文档时,相比朴素 RAG 优势明显
框架设计与算法细节:
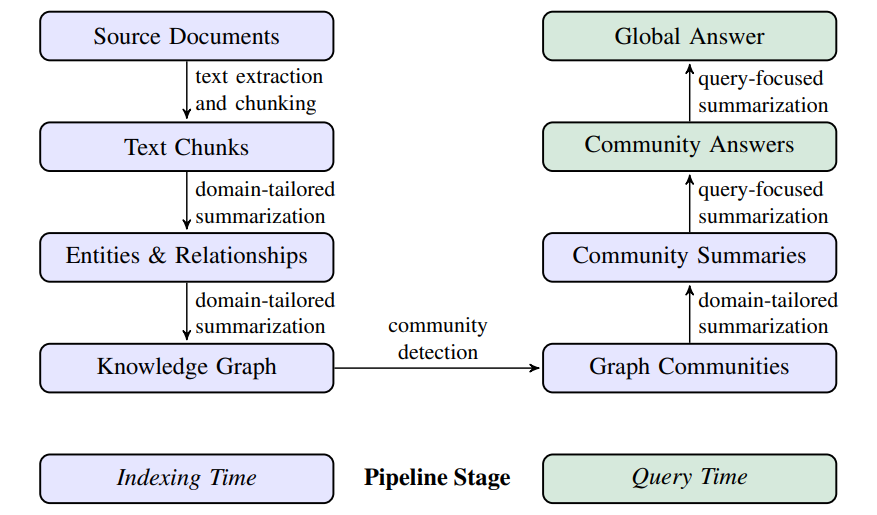
- 上图左侧为索引阶段(Indexing Time),利用 LLM 来自动化构建知识图谱,并提取出对应的节点/实体、边/实体关系和协变量(比如实体描述或时间约束等)
- 然后利用社区发现技术(community detection,比如 Leiden 算法)对完整知识图谱进行子图划分,并进行自下而上处理(关系梳理、生成子图摘要)
- 上图右侧为查询阶段(Query Time),该阶段通过社区摘要的 map-reduce 处理来回答查询(1)map,独立并行地查询根据子图摘要,产生部分答案(2)reduce,部分答案被组合并用于生成最终的全局答案
Deep Search
Deep Search 深度搜索
- 将 Agent 机制纳入 RAG 系统,实现更动态、灵活的检索与生成能力
- 直观表现为以最优结果为导向的反复搜索(比如切换关键词或数据源)
Deep Search 的典型能力
- 动态检索:依据中间结果与置信度阈值,决定是否二次检索;支持不同搜索工具的切换
- 任务分解:将复杂问题拆解为子任务,分别进行检索分析,然后进行证据对齐,进而得出结论
- 工具调用:支持调用外部工具获取实时信息,比如天气查询或者代码执行,再生成结论
- 反思与修正:对生成结果自我评估,发现内容缺失或矛盾时重新检索或调整生成策略
- 交互与偏好对齐:主动追问检索相关的范围、领域与输出格式等偏好,并将用户反馈动态注入检索与排序策略
- 证据可追溯:为关键结论提供来源锚点,标准可能失效、存疑与冲突的证据,降低幻觉风险
- 成本与时延:根据问题难度调节检索轮次、Top‑k 与并发批量,平衡质量与延迟
Deep Research
Deep Research 深度研究
- 引入推理模型,强化检索、查询、分析与研究能力
- 相比 Deep Search,Deep Research 的推理和思考能力更强,最终产出的内容质量更高,但是 token 消耗与用户等待时间也会更高
关键技术: 推理时计算(test-time compute)
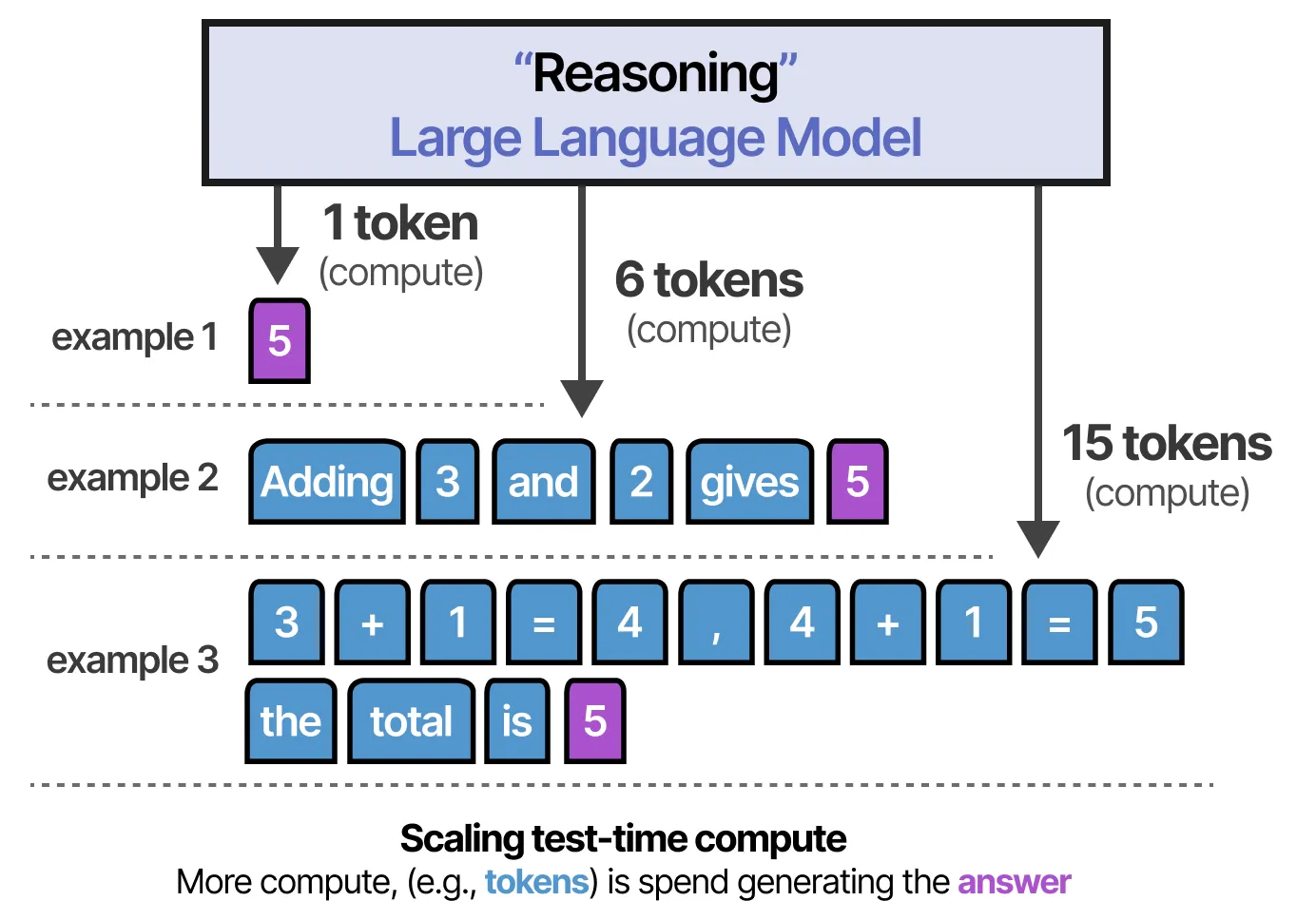
- 推理阶段投入更多的计算资源,例如评估多个潜在答案、进行更深入的规划、以及在给出最终答案前进行自我反思等
- 推理时计算会显著提高结果的质量和准确率,减少反复验证与修改的成本
更多 RAG 技术的进阶技巧,可参考高级 RAG 技术
参考: