本文对谷歌年度盘点系列博客进行总结(在原文的基础上进行了一定拓展)
本次盘点由于内容较多,因此拆分为了三部分: Google Research 2022年度盘点 PART Ⅰ Google Research 2022年度盘点 PART Ⅱ Google Research 2022年度盘点 PART Ⅲ
博客主题与原地址:语言模型、计算机视觉、多模式模型、生成模型、负责任的人工智能、机器学习与计算机系统、高效深度学习、算法进步、机器人学、自然科学、健康、社区参与
1 语言模型
1.1 大块头有大智慧
过去几年里语言模型最重要的两个基础方法:seq2seq学习,Transformer架构
当大模型在充分文本语料上进行训练时,模型可以生成联系上下文的连贯自然响应,并用于广泛的任务(内容生成、语言翻译、辅助编码、高效问答),谷歌提出的LaMDA模型便致力于追求安全、可靠和高质量的多轮对话
- 高质量:LaMDA从敏感度(应该符合常识,不与之前的响应相矛盾)、特异性(特定于上下文,而不是万金油答案)和兴趣度 (SSI,具备洞察力或创造力,令人感到出乎意料)三个维度进行人工评估
- 安全:由一组说明下的安全目标组成,目标捕获对话中的行为并限制模型的输出(避免暴力或血腥内容输出、避免对人群的诽谤、仇恨、亵渎或刻板印象)。这些安全目标输出早期的工作成果,有较大进步空间
- 可靠:主流模型存在相应结果与客观事实相矛盾的现象,借助外部知识库,LaMDA定义了一个可信度指标 groundedness,描述了模型响应内容中得到外部知识认可的占比。但这并不能完全保证LaMDA响应结果的真实性
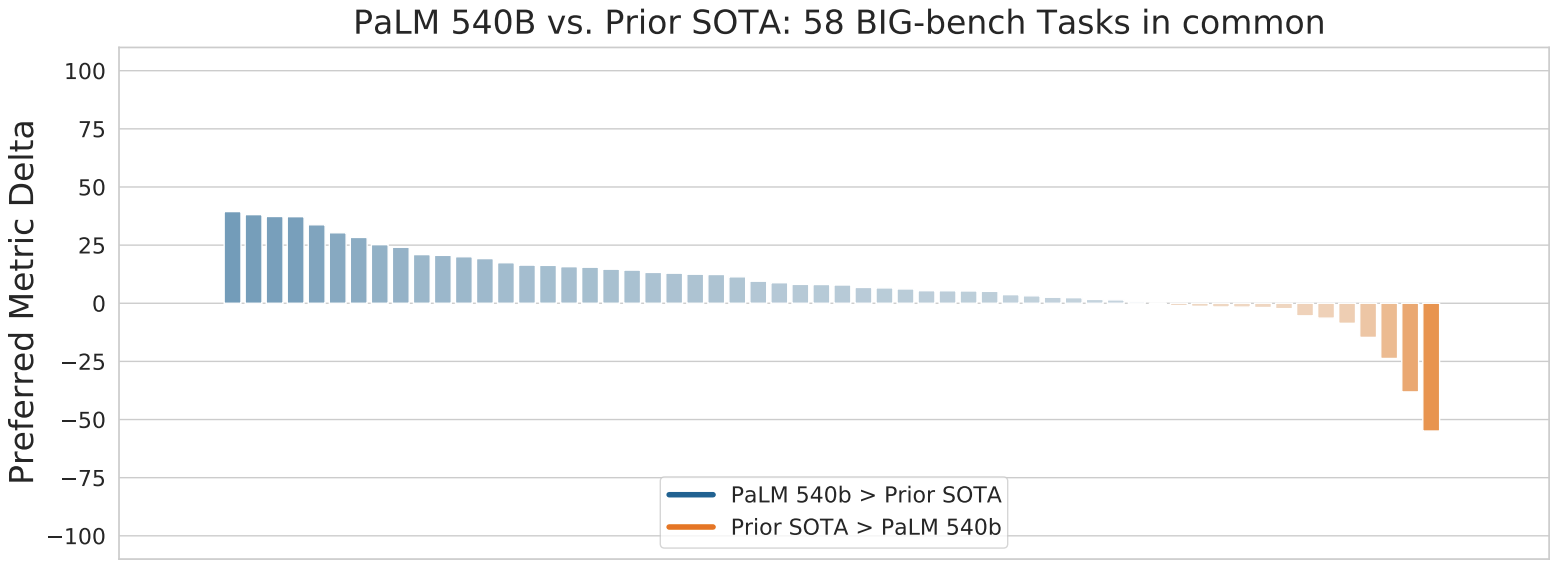
 谷歌在2022年4月提出了一个拥有5400亿参数的大语言模型PaLM,该模型借助Pathways 架构设计在多个TPU v4 Pod上进行训练,最终凭借大模型与大数据优势在58项任务中打破了大部分任务的最优SOTA
谷歌在2022年4月提出了一个拥有5400亿参数的大语言模型PaLM,该模型借助Pathways 架构设计在多个TPU v4 Pod上进行训练,最终凭借大模型与大数据优势在58项任务中打破了大部分任务的最优SOTA
简单扩展:Pathways
- Pathways被作为谷歌的下一代AI架构提出,目前的模型训练架构针对一类问题进行单独训练(SPMD),并且每个模型都是高密度但低效率的,而Pathways的提出就在于同时调用多种感官数据进行多任务的训练(MPMD),通过低密度稀疏的大型神经网络+动态激活,实现更低成本的任务拓展学习(few-shot)和更通用的AI
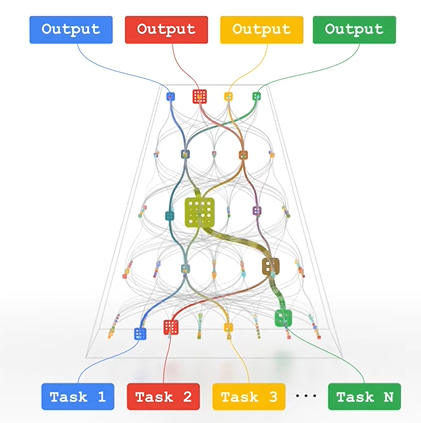
- Pathways架构特点是实现了不同任务与感官间的资源复用和灵活状态共享,Pathway架构追求的是一个稀疏、规模庞大、具备通用性的神经网络,能够根据不同的任务与数据进行泛化,并且保持着极高的训练效率
- PaLM作为Pathways架构给出的第一份答卷,初步实现了异步分布式的高性能运算,但与理想中的Pathways架构仍存在较大差异,缺少多模态与稀疏激活等核心功能,并且仍属于SPMD的范畴
谷歌在内部为开发者提供5 亿参数(平衡精度、低延迟和计算成本)的语言模型ML-Enhanced用于为IDE集成代码补齐功能,通过内部1W+员工的实验对比显示,该功能减少了6%的开发时间,最终代码有2.6%来自补齐功能,接受率为25%
其他常见的代码补齐-VSCode插件:
- Copilot是由Github和OpenAI合作推出的一个人工智能代码辅助工具,提供实时的代码提示和生成功能。自动补齐代码/注释,生态成熟,最新版的Copilot X 直接集成了GPT-4。对认证师生或高质量开源贡献者免费开放,10刀一个月
- CodeGeex 后起之秀,完全开源免费,可作为Copilot平替
- Cursor 借助Chatgpt接口(目前仅支持3.5)的AI编程工具,目前免费
1.2 推理优化
相关内容已整理至:思维链提示 CoT、自洽性 self-consistency
1.3 软提示学习
以GPT和BERT为基准的模型,一般通过微调(fine-tuning)的方式适应下游任务。但这类方法会调整网络中的每个权重,即使相似的任务也需要调整最后几层的权重,这对于大模型来说具有较高的训练成本
GPT3的强大泛化能力提供了基于”提示“的另一种模型泛化思路,即冻结所有网络的权重,通过控制在输入端的”上下文“来执行不同的任务。这种方法减少了计算成本,但性能表现会低于微调模型,并且提示文本需要手动设计。
175B参数量的GPT3经过提示优化后,其在SuperGLUE基准测试的表现低于0.22B参数量的T5微调结果。但从GPT3.5和GPT4的表现来看,这种差异似乎在随着模型规模的增加而逐步缩小
谷歌团队则提出了软提示(soft prompts)学习方法来解决这一问题:
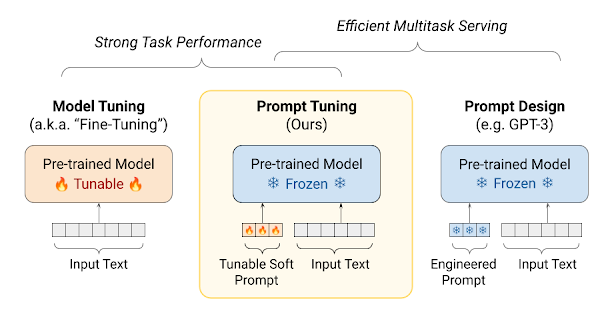
- 上图中左侧表示模型微调,右侧表示提示学习,中间则是谷歌提出的”软提示学习“
- 软提示学习核心思路:冻结模型的核心参数,仅开放提示文本的”提示向量“学习
- 在反向传播过程中,梯度仅用于更新提示文本对应的第一层参数(参数量很小,一般只有几百个)
- 考虑到模型输入长度的限制,一般控制提示文本在 50 个字符以内
通过软提示学习,模型能更深入地理解提示文本,更灵活地处理混合任务:
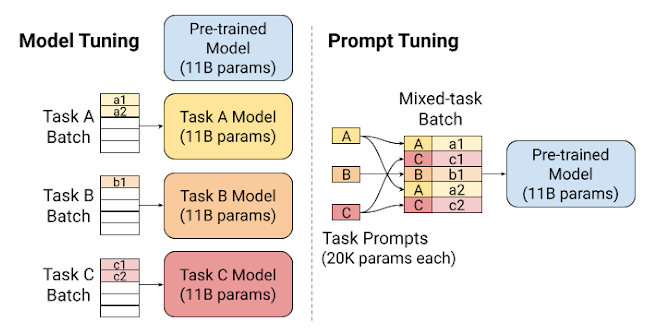
- 左图为传统微调模型,其输入包含任务标识,每类任务都是单独的模型
- 右图为软提示优化模型,其输入为提示文本,不同任务共享同一个大模型
- 软提示优化模型会根据提示文本自动激活不同的模型部位,实现更融洽的参数共享
以T5模型为例,在SuperGLUE基准上进行方法的对比:
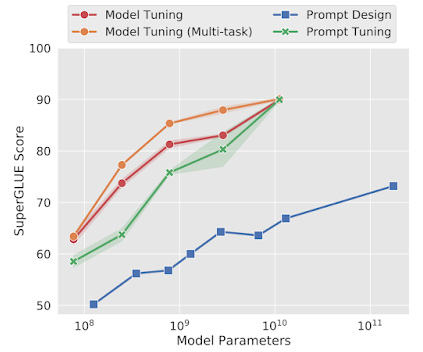
- 随着模型参数量的增加,软提示学习效果快速地追赶上了微调模型的效果
- 但实现同样的性能表现,微调模型所需调整的参数量比软提示学习比要多25,000 倍
- 受限于泛化任务时的样本量,模型微调很容易过拟合,而软提示学习不会遇到这一问题
谷歌的后续试验表明,当软提示文本在缩短至5个字符时,依然具备较好的调节效果。这意味着对于一个110亿参数的模型来说,只需调整2万个参数就能够指导模型的行为
1.4 医疗领域
谷歌在2022年底提出了医疗领域的优化版PaLM模型——Med-PaLM以及两个基准测试数据集
- Flan-PaLM是指令调优版本的PaLM模型,最终 Flan-PaLM 生成的结果有79%优于原来的PaLM
- 而Med-PaLM则是Flan-PaLM在医疗领域的调优结果,即提供更适配于医疗领域的指令集微调模型
- 两个基准测试数据集:医学问答基准数据集MultiMedQA和在线搜索问答数据集HealthSearchQA
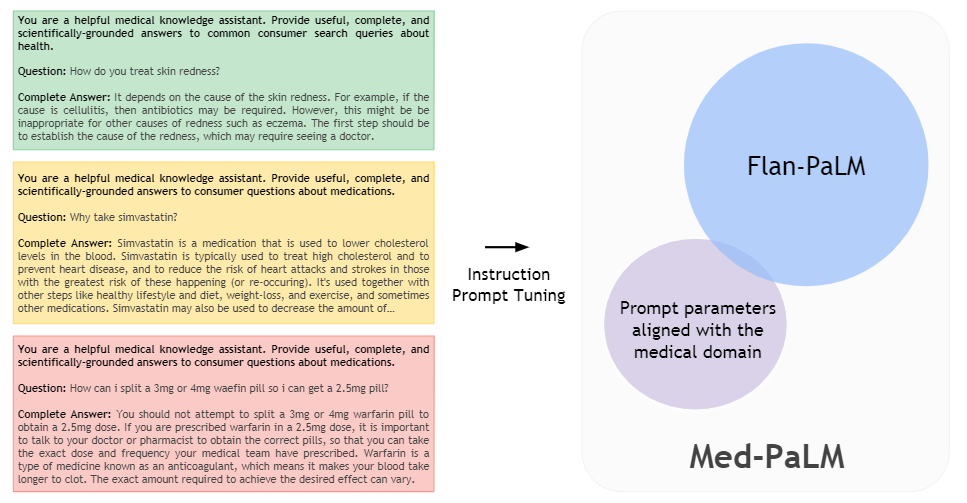 医疗领域的指令微调细节:
医疗领域的指令微调细节:
- Few-shot prompting:每类任务一般提供5个输入输出示例(指令),对于更注重上下文理解的任务,可缩减数量到3或更少
- Chain-of-thought prompting:每个指令都给出中间推理步骤,引导模型模仿人类的思维过程,提高推理能力
- Self-consistency prompting:多次采样结果,并通过投票法选择最一致的结果作为最终答案
- Prompt tuning:通过软提示学习(soft prompts)学习的方式微调模型
最终的Med-PaLM在美国医学执照考试(MedQA-USMLE)拿到了67.6%的准确率,比之前的最好成绩高17%
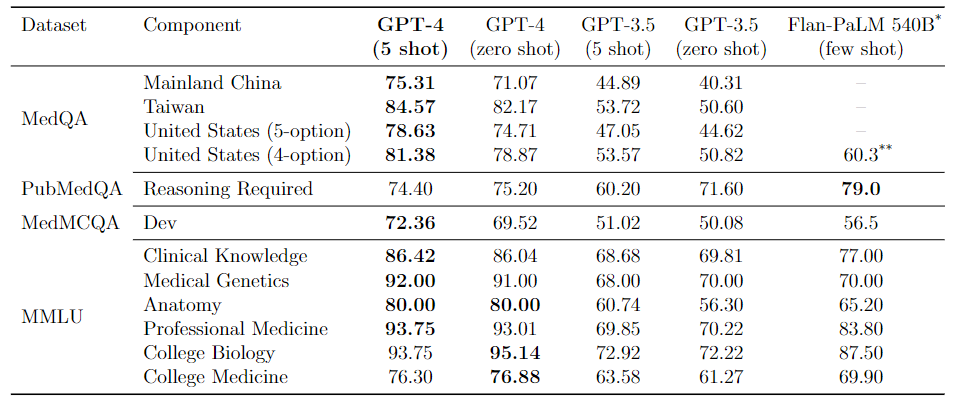
2023年3月20日,OpenAI联合微软对GPT-4在医疗领域的能力进行了充分测试(显著超过Med-PaLM):
2023年3月14日,谷歌官方博客声明了Med-PaLM的迭代版本Med-PaLM 2问世,其在医学考试问题上持续表现出 "专家 "医生水平,得分达到85%,比Med-PaLM之前的表现提高了18%(但只是简单一提,并未发布相关论文)
1.5 语言翻译
随着深度学习与自然语言处理 (NLP) 的结合,机器翻译(MT) 技术在近年取得了较大发展。虽然翻译质量有着显著提高,但现有的翻译至覆盖了大约100种语言,仅占全球活跃语言的 1%,忽略了非洲和美洲等语言多样性高的地区
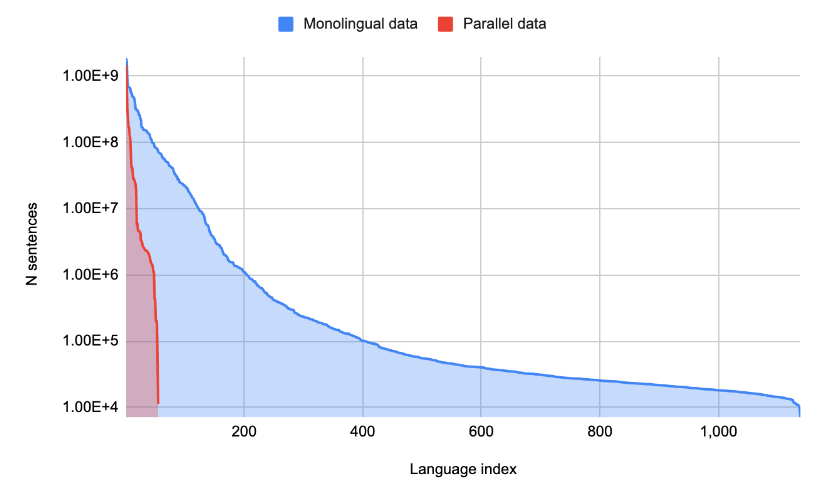
- 对于常用的83种高资源语言(high resources),谷歌可以搜集到大量的双语语料
- 对于剩下的低资源语种(low resources),缺少双语语料、即便是单语语料质量也不佳
多语言翻译支持的两大限制:数据稀缺+建模限制(依赖于平行语料)
为此,谷歌团队整理了一份多达1000种语言的单语言文本数据
- 从网络上爬取到大量语料,并通过CLD3模型进行语种识别。由于CLD3模型是简单的前馈神经网络,训练和推理速度都比较快,因此可以在语料的爬取同时进行过滤,避免了低质量的冗余存储
- 基于Tranformer架构训练了语种识别器,进行二次过滤;针对过滤结果训练CLD3模型,进行三次过滤
- 借助文档一致性进行四次过滤(基于句子进行聚类,过滤聚类结果杂乱的文章);基于词表进行五次过滤(排除不含常用词的句子);再训练Tranformer架构的语种识别器,进行六次过滤;使用TF-IDF总结不同小众语种最特殊的用词Top100,进行第七次过滤和去重;最后人工检验语料(超过2w句),进行最后的精细化过滤
- 最终的单语言文本数据,有 400 种语言的句子超过 100,000 个
- 人工评估显示,大多数数据 (>70%) 都属于高质量的文本语料(可用性>80%)
此外,谷歌团队还提出了一种简单而有效的方法用于训练多语言翻译模型
- 训练数据包括:1057种低资源单语、83种高资源单语、112种双语(以英语为中心)
- 对于双语语料,使用普通的seq2seq训练策略;对于单语语料,使用MOSS模型训练策略
- 通过类似"translate_to_french"的任务标记,实现任务标记在两类语料的训练统一(当源输入为非法语时,该标识表示”翻译“任务;当源输入为法语时,该标识表示”语言润色“任务),并最终得到了一个语言翻译大模型
和普通的seq2seq模型相比,MOSS模型主要有两处改动:
- 将原本Encoder输入端的token随机屏蔽改为连续token(句子片段)的随机屏蔽
- Decoder输入端会对连续token再次随机屏蔽的时候,输出端则会尝试还原屏蔽前的连续token
MOSS模型通过超参数$k$来控制随机掩盖的token长度,进而调整Decoder与Encoder掩码比例($k$越小,Decoder输入端所能获取的信息越少;$k$越大,Encoder端所能提供给Decoder的信息就越少),而Decoder与Encoder之间不同层次的掩码也促使着Decoder与Encoder之间进行了更充分的信息交流
谷歌团队还提出了一种新的翻译评价指标——RTTLangIDChrF,来评估所有语种的翻译质量
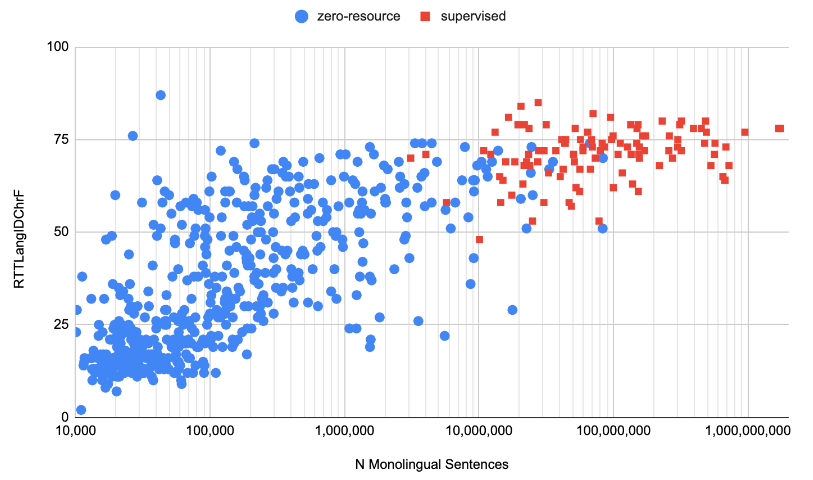
- 可以发现,最终的语言翻译大模型在很多低资源语种上的表现不逊色于有监督的高资源语种
折返翻译(round-trip-translate):将A语言翻译为B语言,再将B语言翻译为A,记为A'
RTTLangIDChrF评价指标:基于折返翻译计算A与A'的相似程度来评测翻译能力
最后,语言翻译大模型会合成大量并行数据,并在过滤后用于训练特定语种的语言翻译模型(规模更小,易于部署)
2022年5月11日,谷歌翻译基于这项技术,新增了24种语言的支持
1.6 大模型的涌现
过往的研究表明,模型表现与计算量、数据规模、模型复杂度之间存在幂律关系
而谷歌团队在特定的提示任务中,在大语言模型身上发现了涌现(Emergent)的现象。当语言模型规模超过某个阈值后,语言模型根据提示处理下游任务的能力会出现爆发式增强:
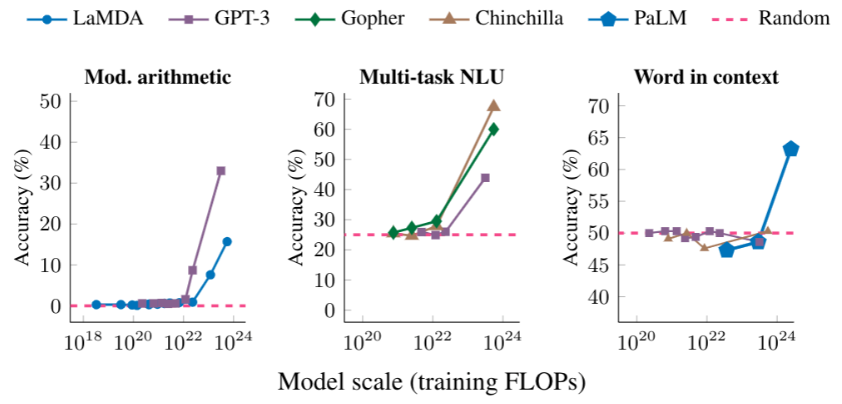
- 以上三个子图分别代表三种提示任务:多步骤算术、大学能力测试、词义理解
- 横坐标为模型规模,用总浮点运算数(FLOPs)来表示;涌现在不同类型的语言模型中均会出现
涌现或称创发、突现、呈展、演生,是一种现象,为许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。涌现在整合层次和复杂系统理论中起着核心作用
比如水分子聚集后组成了雪花是一个物理上的创发现象——摘自维基百科-涌现
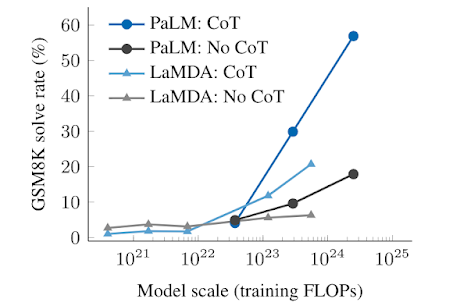
大语言模型的涌现还体现在提示策略上,当模型规模超过某个阈值后,提示策略(如CoT)的效果也会提升明显:
关于涌现的思考:
- 进一步扩大模型是否会产生更强大的涌现?语言模型在未来又会有哪些新能力?
- 为什么规模的扩大会导致涌现?是否存在其他方法在不改变规模的情况下产生涌现?
2 计算机视觉
近年来计算机视觉的一个趋势就是从卷积神经网络(CNN)转向Transformer架构(如ViT)。CNN的卷积能对局部特征进行良好的抽象,而Transformer则通过更灵活的注意力机制,更有效地利用图像的全局和局部信息
2.1 MaxViT:多轴视觉自注意力
完整的注意力机制与图像大小呈二次方关系,因此很难与应用到高分辨率的图像。
为此,MaxViT模型引入了全新的Transformer模块——多轴自注意力(multi-axis self-attention,Max-SA)
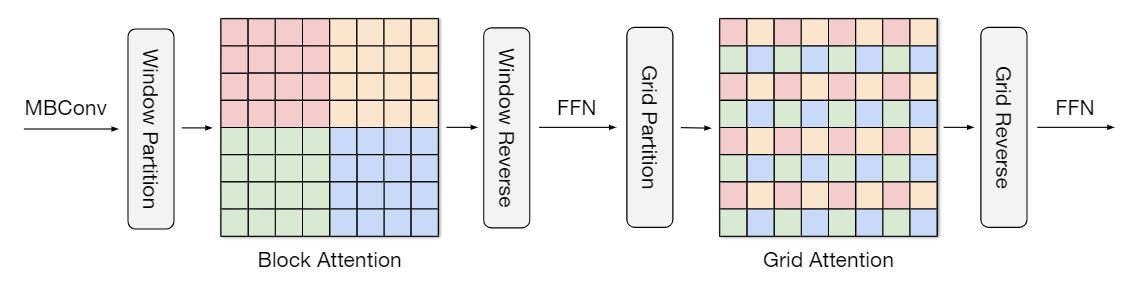
- Max-SA通过分解空间轴(按照局部和全局两个角度)将传统的注意力机制进行分解
- 对应窗口注意力(Block attention)与网格注意力(Grid attention)两种稀疏形式
- Block attention专注于局部信息,Grid attention专注于全局信息,二者具有良好的可拔插性
- 在不损失非局部性的情况下,通过注意力的稀疏(可以理解为注意力窗口尺寸转为一个固定值,如$4\times 4$),Max-SA将计算复杂度从传统注意力机制的$O(N^2)$降低到$O(N)$
Block attention操作对应卷积操作,而Grid attention对应池化操作
Max-SA模块巧妙地融合了CNN和Transformer的优势
MaxViT模型的完整结构:
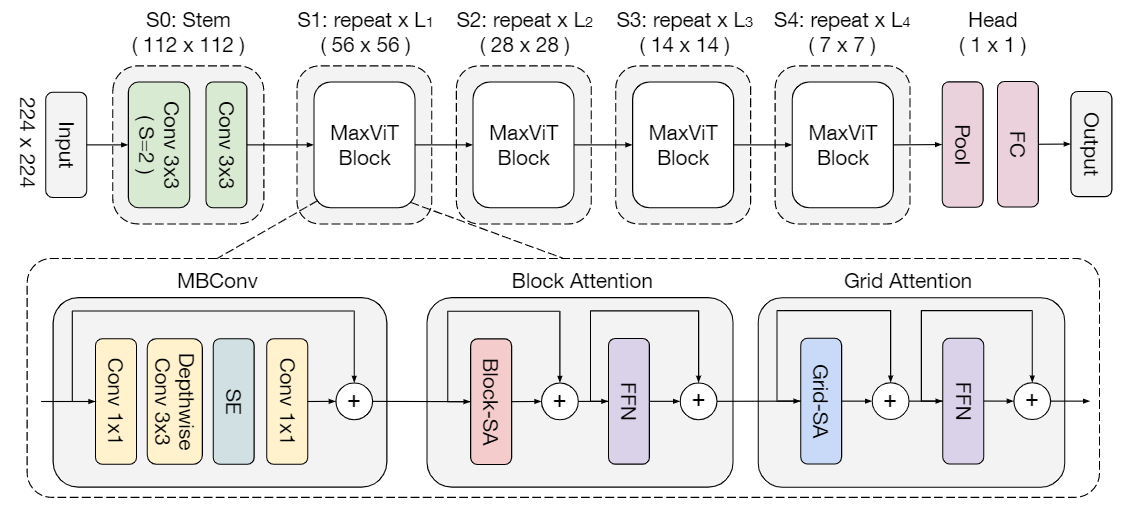
- MBConv块(源自MobileNetV2):使用1x1卷积核先升维再降维,中间包含深度卷积 (一个卷积核负责一个通道) 和 SENet(对卷积后特征图进行额外全局池化,并用于评估不同通道的权重),最后还包括一个残差连接
- MBConv块以较少的参数量为模型融入的卷积的特性,增强了模型的泛化能力和可训练性
- MBConv块中的深度卷积也可以被看作是一种条件位置编码(CPE)(卷积能提取局部邻域的相关性,比如哪两个像素是紧挨着的,可以间接地还原全局位置信息),替代了原本ViT架构中的显式位置编码
实验分析:
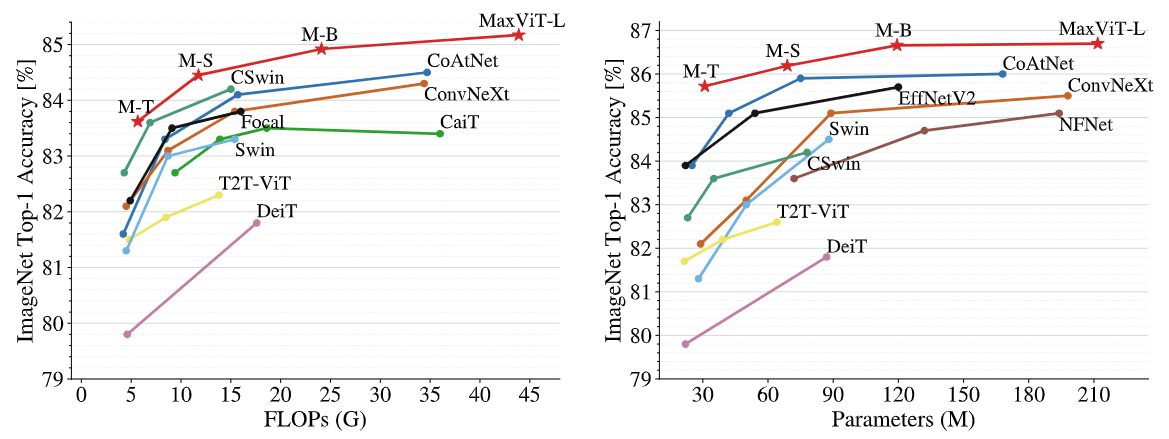
- 上图为不同模型在 ImageNet-1K 数据集上的比较,左为微调前,右图为微调后
- 最大的模型 MaxViT-XL 包含475M参数,在数据集上实现了 89.5% 的Top-1准确率
- 以MaxViT作为backbone,其在下游任务(目标检测、图像美学评估)中也有优异表现
- MaxViT模型有效地将全局信息和局部信息进行交互,也能更好地适应高分辨率图片
- 相比于其他模型,MaxViT模型在取得相同性能时,能保持更低的参数规模和计算成本
MaxViT的相关代码和模型均已开源
2.2 MAXIM:多轴MLP图像处理
现有的Transformer经常面临一个不够灵活(固定输入)和高计算复杂度$O(N^2)$的问题
MAXIM使用多轴MLP取代Transformer中自注意力运算,而多轴主要体现从局部(local)和全局(global)两个维度进行MLP操作,促使模型得到局部和全局的交互,最终MAXIM多个下游任务中均取得了SOTA效果
MAXIM是22年4月份提出的,其中的多轴思想也沿用到了22年9月份提出的2.1 MaxViT:多轴视觉自注意力|MaxViT中
MAXIM模型的完整结构:
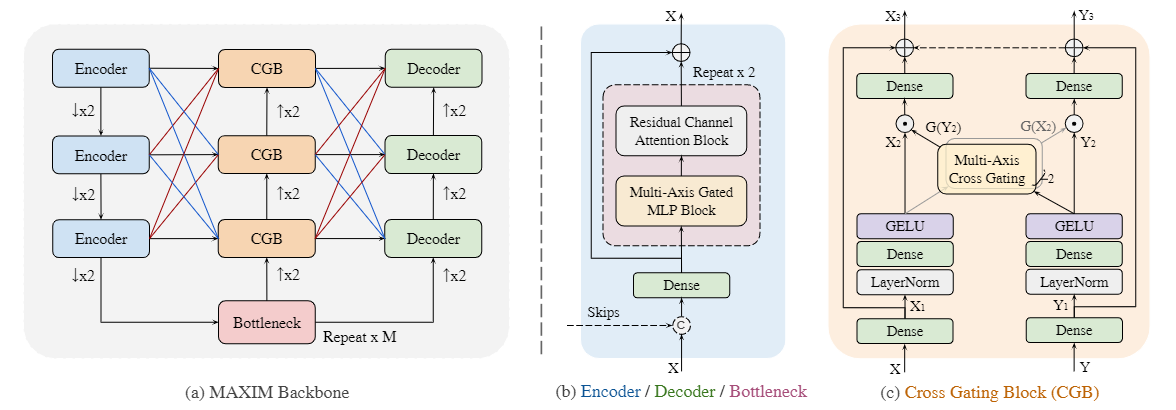
- 总体来看,MAXIM使用了类似UNet的结构,左边是一连串编码器,右边是一连串的解码器
- Residual Channel Attention 通过全局池化评估不同通道的权重,配合残差连接增强了特征的表达
- MAXIM的创新点在于引入了交叉门控块(cross-gating block)和多轴门控MLP(multi-axis gated MLP)
多轴门控MLP(multi-axis gated MLP):
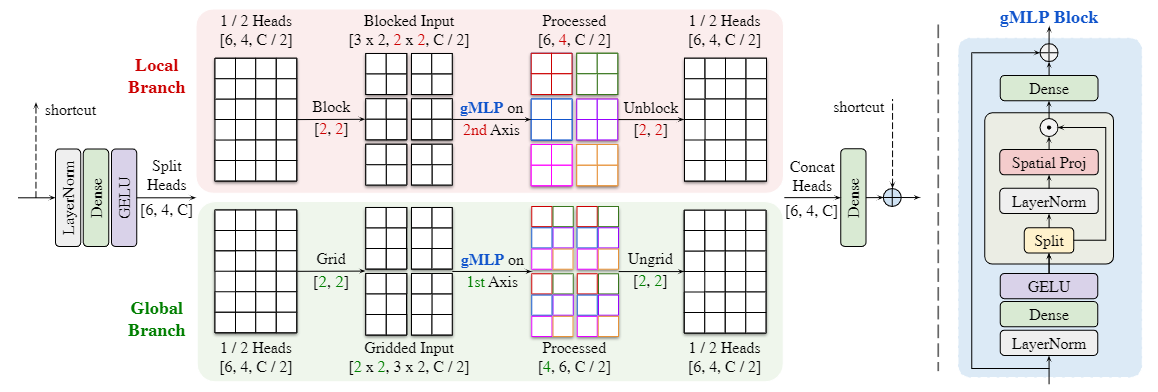
- 对于输入特征按照Heads平分,一半给局部分支(Local Branch),一半给全局分支(Global Branch)
- 局部分支对输入信息进行切块,关注局部信息;全局分支对输入信息进行网格化,关注全局信息
- gMLP模块使用带门控单元(Spatial Gating Unit, SGU)的MLPs来取代自注意力机制,在部分图像处理下游任务中更具优势。具体来说,对于输入$Z$,gMLP块经过简单处理后会按通道切分(Split)为两部分$Z_1,Z_2$,而目前的SGU计算也很简单:$SGU(Z)=Z_1\odot f(Z_2)$,其中函数$f$常选择简单的线性投影
交叉门控块(cross-gating block):
- 基本结构和gMLP是类似的,只不过因为输入本身就包括两部分$X,Y$,所以取消了切分(Split)操作
- 同时在进行SGU计算前,还会分别进行切块(关注局部特征)和网格化(关注全局特征)
- 将局部特征和全局特征拼接后进行SGU计算,$SGU(X)=X\odot f(Y),\ \ SGU(Y)=Y\odot f(X)$
MAXIM在多项图像任务(去噪、去模糊、去雾、去雨和弱光增强等)中都实现了有竞争力的表现:

MAXIM的相关代码和模型均已开源,CVPR 2022年最佳论文
2.3 Pix2Seq:语言模型框架用于目标检测
过往的目标检测方法(如Faster R-CNN、DETR)都需要精心设计网络架构和损失函数,一方面这增加了模型在系统间调整和训练的复杂度,另一方面也降低了模型的泛化能力
而Pix2Seq的思路也更具简单粗暴,将目标检测看作语言建模问题,使用经典的语言模型架构(如Transformer)直接预测目标的类别和对应的离散坐标:$[y_{min},x_{min},y_{max},y_{min},class]$,并取得了较好的性能表现
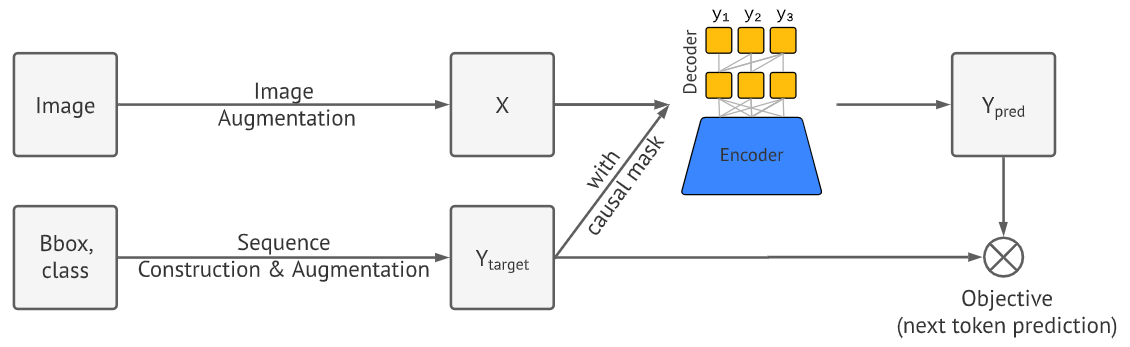
- Pix2Seq会使用常用的数据增强方法,并将边界框和类标签进行序列化处理(坐标会离散化,转化为整数)
- Pix2Seq的模型架构为常见的Encoder-Decoder,其中编码器可以是卷积网络、Transfomer或二者的组合,而解码器/生成器则是Transfomer;编码器捕捉图像信息,解码器生成目标序列
可以把Pix2Seq理解为”基于文本预测标题“,只不过输入是”图像“,而预测的标题是”坐标和类别组成的序列“
Pix2Seq的最终实验表现也很不错:
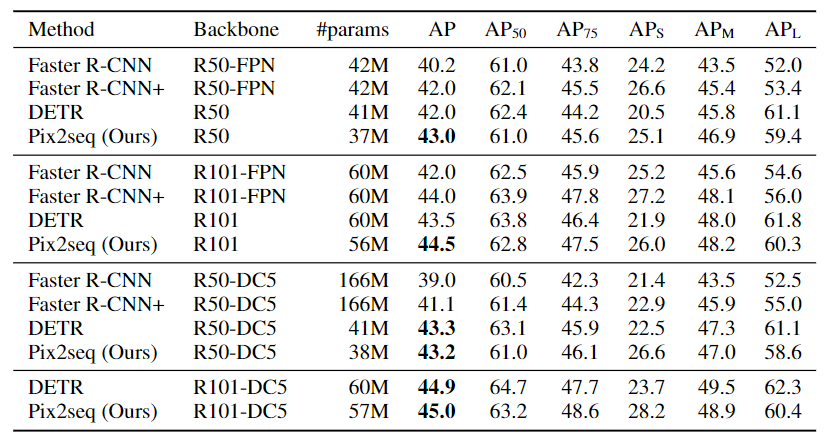
- Pix2Seq在中小型物体上的表现与Faster R-CNN相当,但在大型物体上表现更好
- 通过对中间层网络的可视化可以发现,Pix2Seq学到了每个像素点对应的模糊位置
- Pix2Seq的模型架构和损失函数是通用的(没有针对目标检测任务特意优化),很容易扩展到不同的领域
场景示例:

Pix2Seq的相关代码和模型均已开源
2.4 图片转视频
FILM模型可以在两张图片(相隔多秒)之间进行插值来创建短的慢动作视频
FILM模型主要包含三个组件:
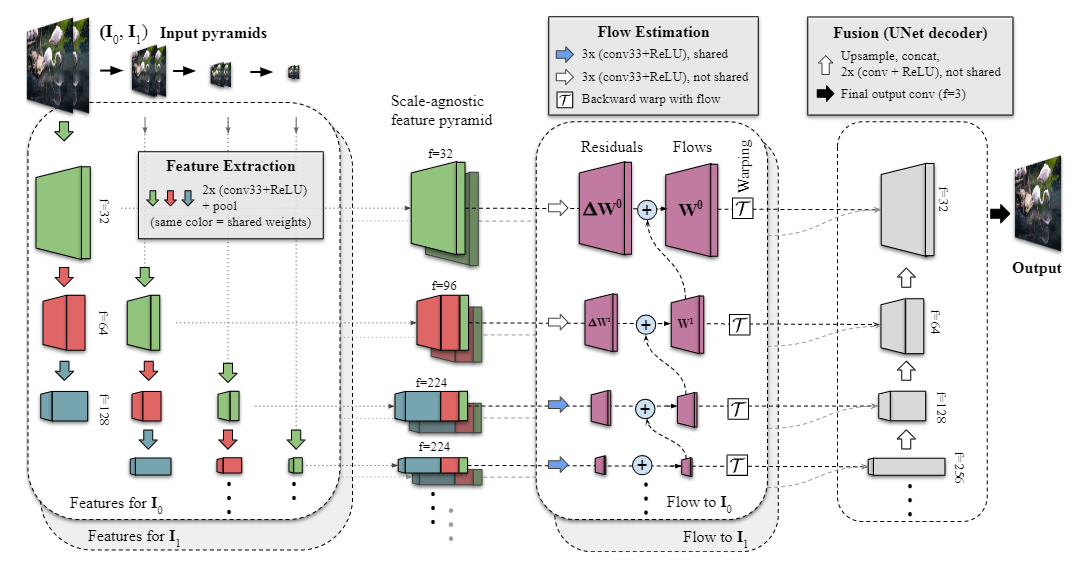
- 特征提取器:使用深度多尺度的金字塔结构进行图像特征的抽取
- 双向运动估计器:分析不同尺度的图像特征,进行像素级的运动估计
- 融合模块:汇总不同尺度、已完成运动估计的图像特征,生成中间帧图像
最终效果展示:

传统光场渲染专注于再现与视图有关的效应,如反射、折射和半透明,但需要对场景进行密集的视图采样。而基于几何重建的方法则只需要稀疏的视图采样,但不能准确的模拟非理想(non-Lambertian)散射。而谷歌提出的光场神经渲染(LFNR) 则通过Transformer架构学习示例的像素颜色变化,一组Transformer学习不同视图的对极线信息(用于对齐不同视图下的像素),另一组Transformer学习不同视图下的图像信息(学习遮挡或光线变化的推理),最终实现了稀疏采样下的高精度再现:

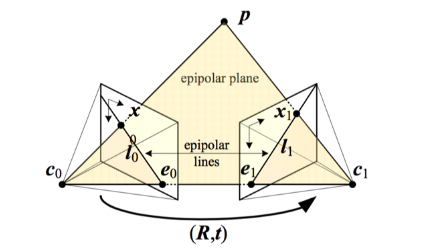
对极几何是相机在两个不同的位置生成的两幅图像,其拍摄位置和生成图像之间存在特殊的几何关系
- 极点(Epipoles):两个相机连线与两个成像平面的交点,如上图中的$e_0$、$e_1$
- 极线(Epipolar Lines):空间中点在成像平面上的投影点与极点的连线,如上图中的$l_0$、$l_1$
- 极平面(Epipolar Plane):空间中的点与两个相机的光轴中心点所组成的平面,如上图$c_0$、$c_1$、$p$所在的平面
参考来源:对极几何
LFNR 的一个局限性是Transformer会为每个参考图像单独学习对极线信息,并根据输出光线坐标和图像特征来决定信息的保留。因此LFNR不适合跨场景的渲染,可泛化性弱,而GPNR则克服了这一缺陷。
GPNR包含三组Transformer,第一组Transformer沿对极线邻域内像素提取特征信息(用于对齐不同视图下的像素,其中对极线使用相对位置编码以提高泛化能力),第二组Transformer则从不同视图中抽取图像信息,第三组Transformer将根据对极线信息,尝试理解并融合不同视图下的图像信息(深度、光影等)。最终GPNR在未经微调的新场景下表现如下:

2.5 2D转3D
LOLNeRF提出了一种框架,用于从单视图图像中学习并建模3D结构和外观
LOLNeRF 使用预测的二维关键点(landmarks)将数据集中的所有图像大致对齐到一个典型的姿态,以此来确定应该从哪个视图渲染辐射场以再现原始图像。模型主要包含两个技术核心:
- GLO(Generative Latent Optimization)用于图像的重构生成。GLO会根据正态分布随机生成N个d维的隐空间编码(latent code),记作z;然后Encoder将图像进行抽象表征后与编码z进行匹配,最后通过z反向生成图像。GLO的建模目标函数是让生成图像与原始图像尽可能相似。(编码z的引入迫使模型学习数据间的共性,增强了模型泛化能力)
- NeRF(Neural Radiance Fields)擅长从2D图像中重建静态3D对象。NeRF通过端到端的监督学习,将3D渲染像素和2D图像进行匹配,其输出结果为3D空间每个点的颜色和密度(依赖于对射线/相机光线的估计)
- LOLNeRF 将GLO和NeRF进行结合,并设计了一种硬表面损失函数避免生成结果的模糊;除此之外,LOLNeRF还借助网络对图像进行背景拆分,通过提高模型对前景网络的专注性来改善生成结果的质量
研究发现,对于猫、狗或人脸模型,只需要五个关键点(1鼻尖、2眼角、2嘴角)就可以实现准确的相机光线估计
最终效果预览:

3 多模态模型

下一代的多模态模型将不再依赖特定任务或领域,而是根据给定问题激活不同的模型路径(pathway),并能自动地处理不同的模态。而实现这一目标还有两个问题需要思考:
- 模型需要多少种模态和数据,才能融汇贯通学到的内容?
- 最终多模态的混合表示,应该以怎样的形式呈现才是最高效的?
3.1 多模态间的转换探索
不同模态间的信息即存在鲁棒性也存在互补性,比如音频流和视频帧(可以单独使用,联合起来更好)
多模态瓶颈转换器(MBT)的提出是为了更有效的融合不同模态的信息,其主要包含两部分限制:
- 通过收窄的融合瓶颈,迫使不同模态间收集并压缩最有必要分享的信息
- 共享仅发生在网络的底层,网络上层依然单独用于各自模态信息的抽取

不同网络层进行MBT瓶颈融合的性能表现与计算成本(声音分类任务):
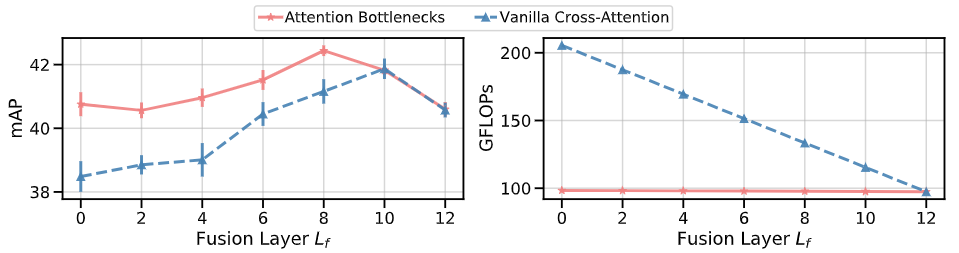
- Vanilla Cross-Attention:经典的seq2seq结构,使用交叉注意力捕捉跨频率/时间的信息
MBT 在不同单模态下游任务中的表现:

- 其中AudioSet和VGGSound为声音分类任务,其他三个是视频动作识别任务
- AudioSet的评价指标为mAP,Kitchens的评价指标为Top-1动作准确率,其他为Top-1分类准确率
注意力可视化:
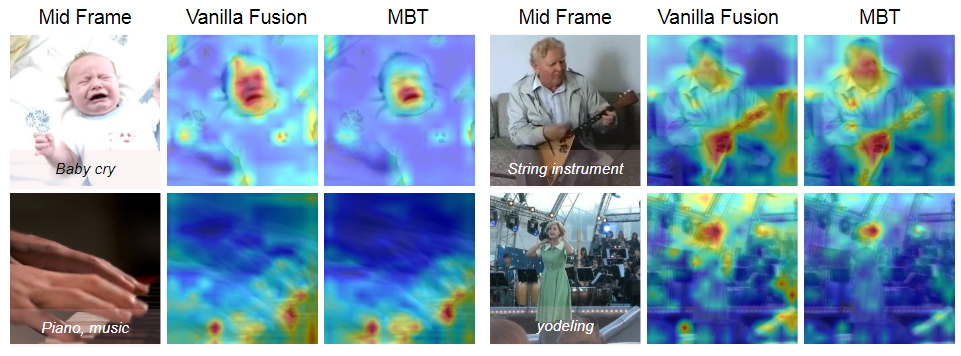
MBT更关注于包含运动或声音区域
3.2 多模态的优越性
多模态往往能实现超越单模态的性能表现
2013年,DeViSE(Deep Visual-Semantic)通过融合图像表示和词嵌入表示来提高图像分类的准确性
LiT ( Locked-image Tuning)将语言理解添加到图像模型的预训练中,极大提高了零样本图像分类性能
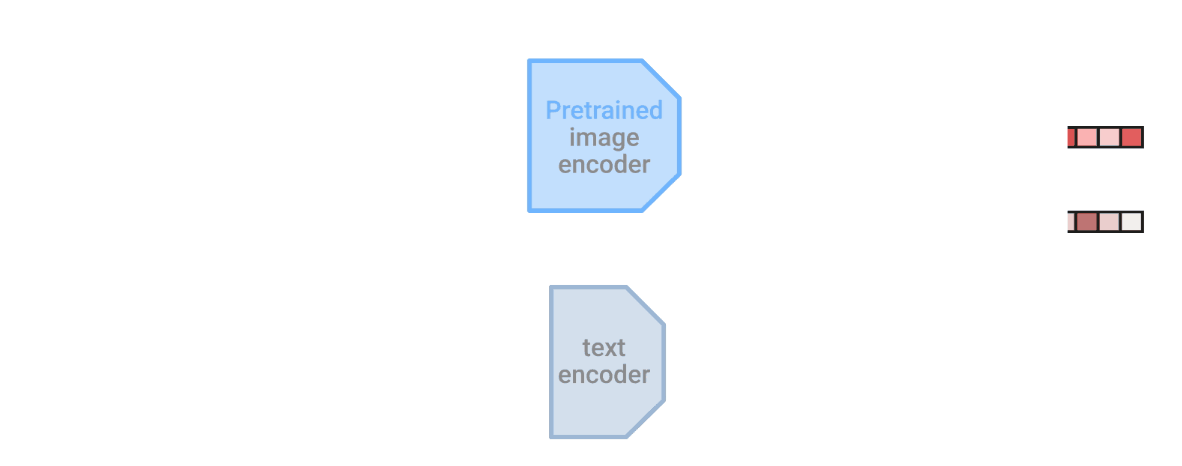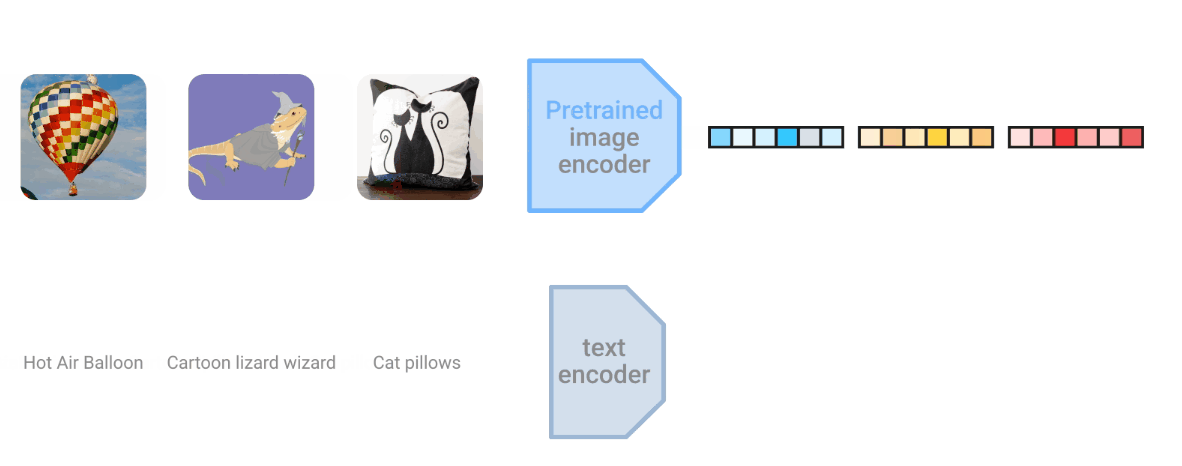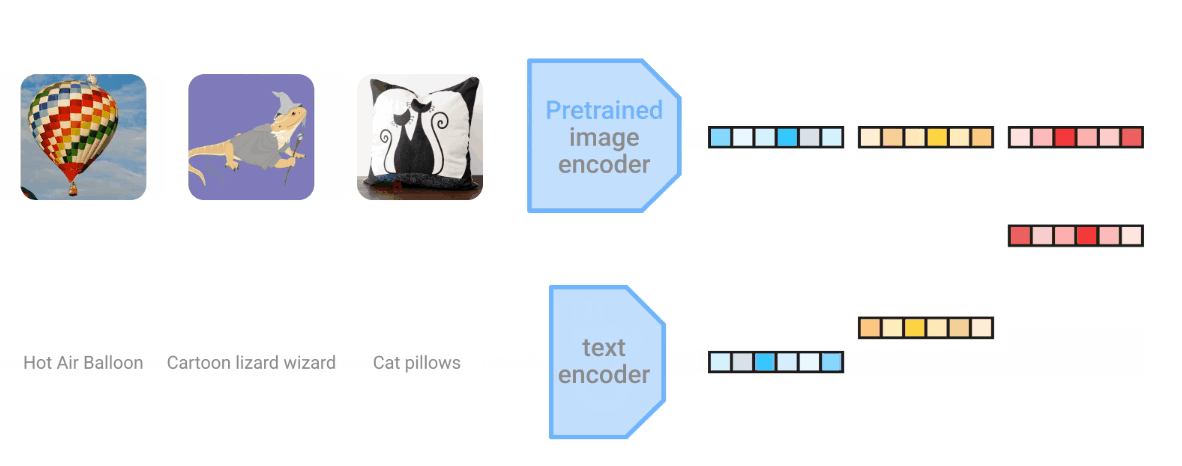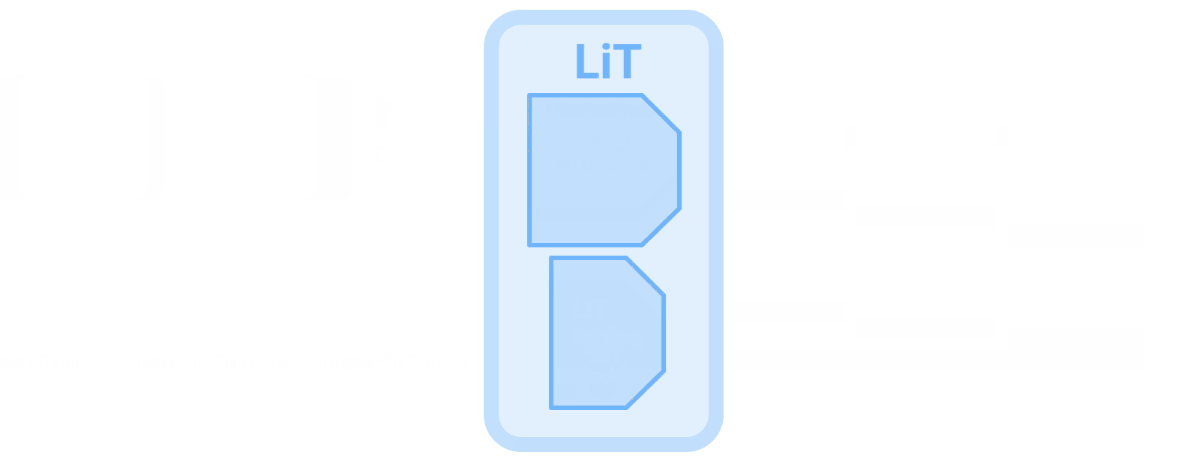
- 经过实验分析后发现,固定图像编码器并微调文本编码器的效果最好
- 文本编码器的微调主要通过对比学习实现,追求对应文本和图像的匹配
- LiT 调优模型在 ImageNet 上实现了 84.5% 的零样本准确率,并有较好的泛化能力
CoVeR对图像和视频进行联合训练,提高了视频动作分类任务的准确率
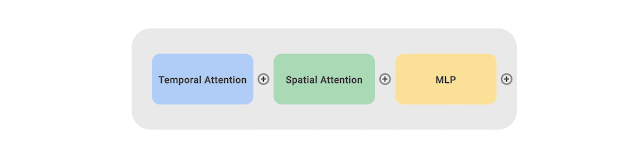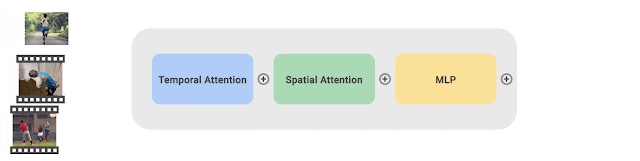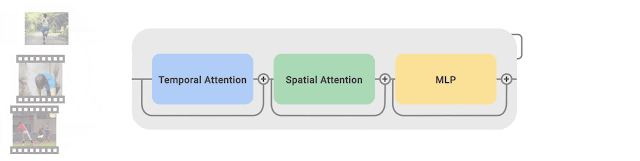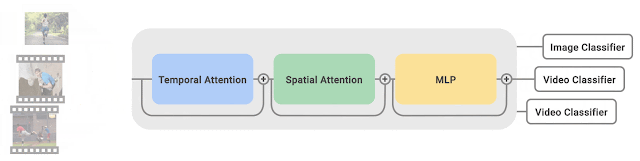
- CoVeR使用最近提出的TimeSFormer作为模型基本组成,每个TimeSFormer包含24层Transformer块,每个Transformer块包含两个Transforme层(分别专注于时间和空间信息)和一个多层感知器(MLP)
- 为了适应不同的训练任务,TimeSFormer的输出会根据训练任务的不同配置对应分类head以获得预测
- CoVeR借助多数据集进行训练,天然地适合迁移学习;模型的通用性更强,过拟合的风险更低
PaLI是一种可扩展的多模式和多语言模型,用于解决各种视觉语言任务
- 最大参数级的PaLi共包含17B的参数,其中4B为视觉模型,13B为语言模型
- PaLI 模型架构简单,具有较好的可复用性和可扩展性,无缝兼容各种经典的预训练模型
- PaLI 支持100 多种语言,并在各种视觉语言任务(视觉问答、图像字幕、对象检测、图像分类、光学字符识别、文本推理等)取得了SOTA结果,在其他纯语言/纯视觉任务上也保持着不错的性能
FindIt通过融合文本理解和多层级的视频信息,实现了自然语言查询式的目标检测任务

视频文本迭代协同式表征(video-text iterative co-tokenization approach)进行视频问答:

其他多模态成果:
- VDTTS:基于视频驱动的文本转语音(根据口型和表情恢复说话者的韵律和情绪)
- 谷歌助理优化:根据说话者相关的视觉(凝视方向、距离远近、面部匹配)和听觉线索(语音匹配、意图识别)来优化谷歌主力与人的交互,避免各种场景下的错误唤醒
- 自动驾驶优化:将激光雷达的3D点云数据与其他传感器(如车载摄像头)数据进行结合,实现更好的感知与决策
4 生成模型
2022年的生成模型在很多方面(图像、视频、音频)展现出各种惊人的进步:

4.1 图像生成
图像生成相关的重点模型的发现历程:
- 2015年,扩散模型被提出,其核心思想在于迭代式扩散过程系统地、缓慢地破坏数据分布中的结构,然后在反向扩散过程中从噪声中逐步恢复数据分布中的结构。扩散模型以可控的输入控制着图片生成
- 2016年,PixelRNN 通过引入循环架构实现了更高效的卷积,并为深度神经网络像素级生成奠定了基础
- 2017年,VQ-VAE对特征进行稀疏编码,并借助PixelRNN、PixelCNN等自回归模型进行高质量图像生成
- 2018 年,Image Transformer使用自回归 Transformer 模型生成图像
- 2021年,CLIP基于海量图像文本(低质量)对进行弱监督训练,实现了较强的zero-shot性能,为更好的图像生成性能打开了大门(可以作为预训练模型迁移到图像生成领域)
Imagen模型直接使用大语言模型(如T5,也不需要微调)抽取文本的特征,之后利用这个特征指导扩散模型生成对应文本的高质量图像,论证了文本理解对高质量图像生成的重要性
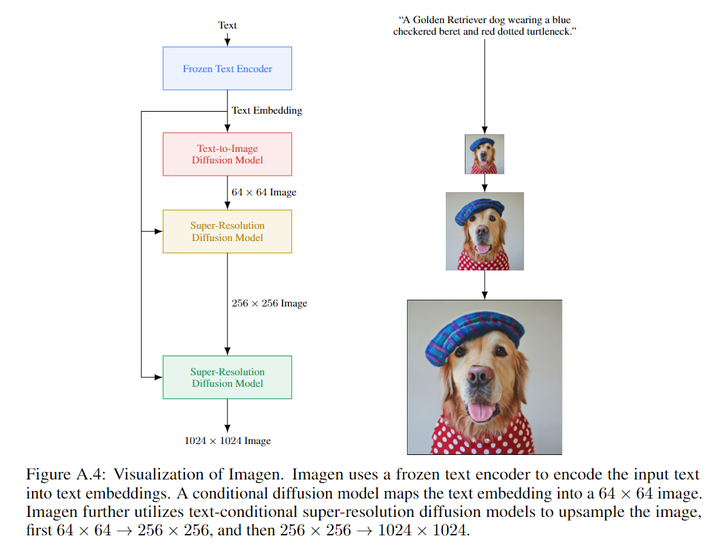
Parti在VQVAE的基础上引入了对抗性损失以促进高质量图片的生成,同时用 ViT 替换 CNN 编码器和解码器(这种方式在保持性能的提前下,提高了模型容量和训练效率)
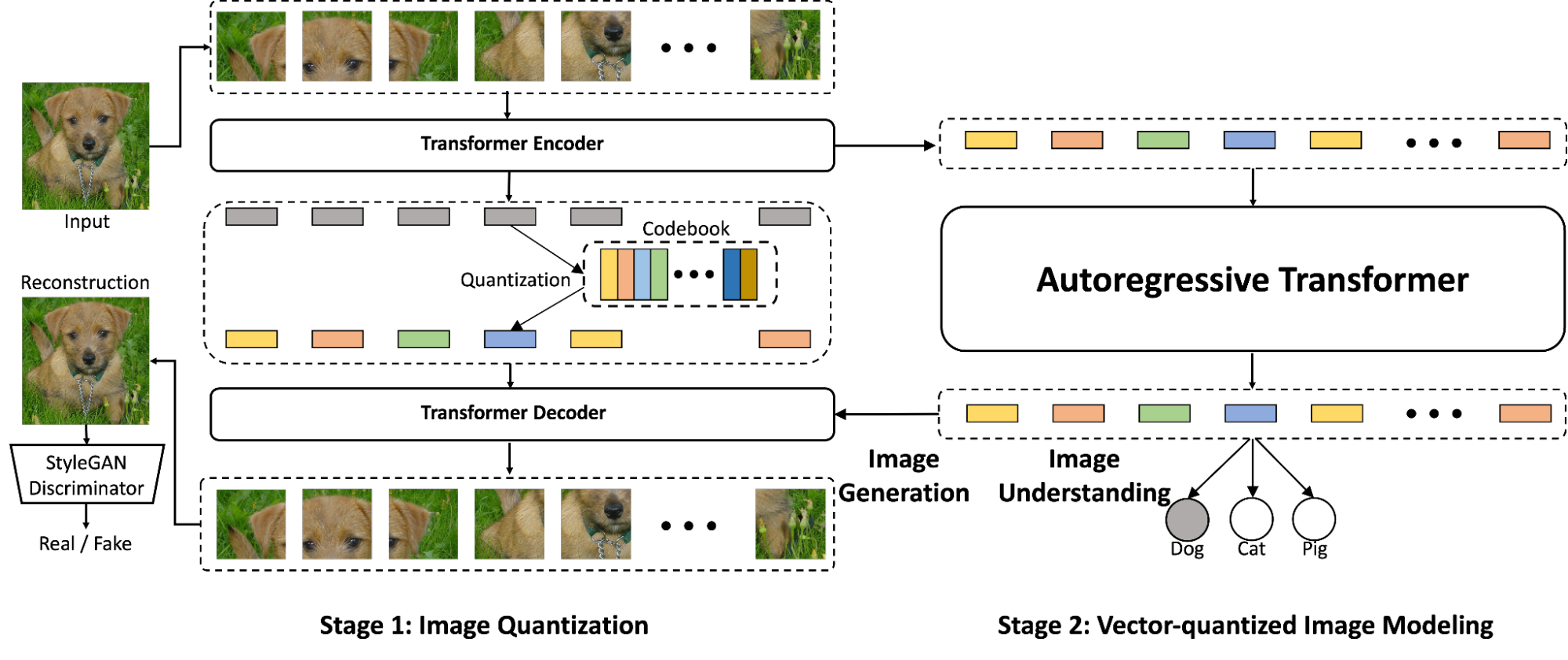
- 在训练的第一阶段,ViT-VQGAN 将图像转换为离散整数(稀疏编码)
- 之后自回归 Transformer进行建模学习,借助文本增强模型对图像的理解
- 最后将稀疏编码根据编码表(相当于embeding层)和图像特征进行图片的还原
最后对比一下两种图片生成方式:

- Imagen(左)支持更复杂的文本提示:“皇家城堡的墙壁。墙上有两幅画。左边一幅是皇家浣熊王的详细油画。右边一幅是详细油画皇家浣熊女王的画作”
- PartiParti(右)文本提示:“一只泰迪熊戴着摩托车头盔,披着斗篷在纽约市的出租车上冲浪。单反照片”
4.2 用户控制
DreamBooth通过给定文本和图像,可以微调像 Imagen 或 Parti 这样的训练模型
Dreambooth的实现思路很简单,也很巧妙:
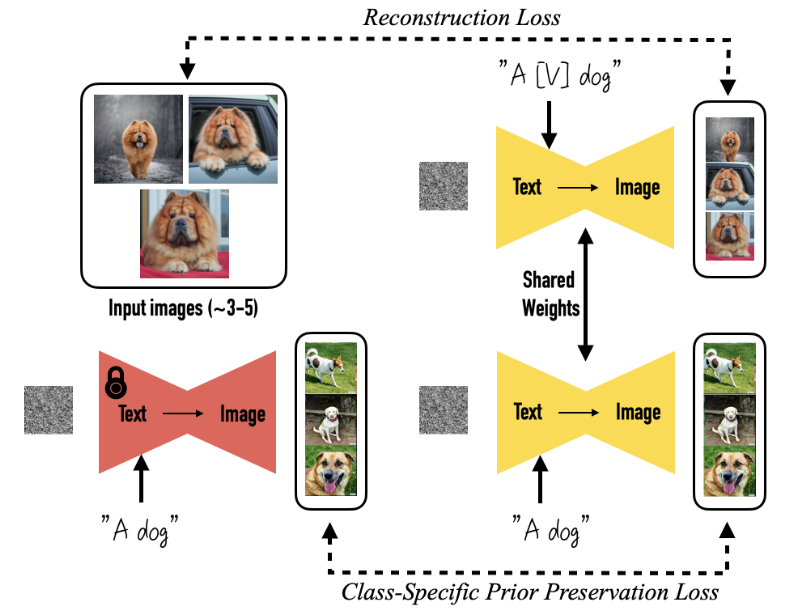
- 给定一组输入图片后,先添加特殊标记符
[v]对模型进行微调 - 利用大模型的过拟合能力,让模型将这组图片与其他的狗狗图片分开
- 再通过输入期望的提示文本+特殊标记符
[v],实现可控的图片生成
最终效果:

4.3 视频生成
相比于图像生成,视频生成不仅要考虑每一帧中的像素与属性(如提示文本)匹配,还要在连续帧之间保持一致
Imagen Video使用级联扩散模型生成高分辨率视频
Imagen Video模型包含1个冻结(frozen)的文本编码器,1个用于视频解析的基础扩散模型,3个SSR(解析空间超分辨率的扩散模型)和3个TSR(解析时间超分辨率的扩散模型),总计7个扩散模型,11.6B模型参数:
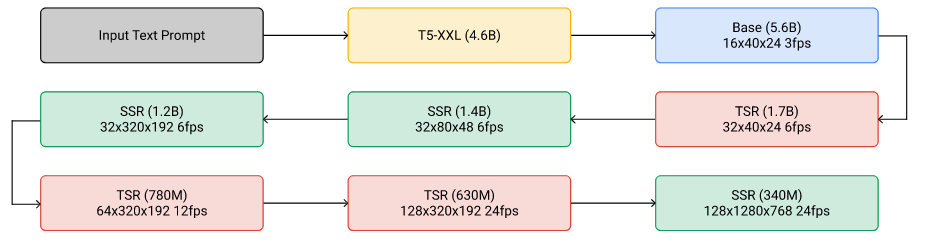
- 实际使用时,级联间的不同扩散可以单独训练,并且文本表征会注入每一个扩散模型
- 图像生成时,SSR会在所有帧中反向扩散视频的空间结构,而TSR通过填充中间帧来丰富视频的视觉结构
Imagen Video效果展示(“一头戴着生日帽的快乐大象在海底行走”):

Phenaki提出了一种新的Transformer视频表示方法
- 使用编码器-解码器结构,先将视频转化为离散标记(稀疏编码),再解码生成视频
- 通过双向 Transformer实现文本嵌入与视频标记的转换
- 使用时间维度的因果注意力(?)灵活控制生成视频的时长
Phenaki效果展示:

- 提示文本(较复杂):"一只逼真的泰迪熊正在旧金山的海洋中游泳。泰迪熊潜入水中。泰迪熊和五颜六色的鱼儿在水下不停地游来游去。一只熊猫正在水下游泳。"
Imagen 擅长生成单帧高分辨率的视频,Phenaki擅长生成长时间尺度视频,二者可以互补融合
4.4 音频生成
语音序列的特性:
- 相比于文本,语音序列具备更复杂的局部结构(例如音素或音节)
- 句子可以由几十个字符表示,但其音频波形通常包含数十万个值
- 语音序列还会受到说话风格、情感内容和录音条件等因素的影响
AudioLM提出了一种新的音频生成框架,通过只听音频来学习生成逼真的语音和钢琴音乐
AudioLM 输入主要包含两部分:
- 从自监督音频模型w2v-BERT中提取到的语义标记,其中捕获了语音的局部依赖性(例如,演讲中的发音、钢琴音乐中的局部旋律)和全局长期结构(例如,语言句法和语义内容、钢琴音乐中的和声和节奏)
- 为改善音频保真度太差的问题,引入了SoundStream 神经编解码器生成的声学标记,其中捕获了音频波形的细节(例如扬声器特征或录音条件)并允许语音的高质量合成
AudioLM 训练的三个阶段:
- 仅使用语义标记,对音频序列的高级结构进行建模
- 将整个语义标记序列与过去的粗略声学标记连接起来,然后预测未来的标记
- 使用精细声学模型处理粗略的声学标记,从而为最终音频添加更多细节
AudioLM 生成的音频表现出长期一致性(例如,语音中的语法、音乐中的旋律)和高保真度,优于以前的系统。通过人工评分者对真实音频和生成音频进行区分,最终成功率为51.2%,略高于瞎猜(50%)
最后在文章结尾贴一下语音生成的效果展示~