本文对谷歌年度盘点系列博客进行总结(在原文的基础上进行了一定拓展)
本次盘点由于内容较多,因此拆分为了三部分:
Google Research 2022年度盘点 PART Ⅰ
Google Research 2022年度盘点 PART Ⅱ
Google Research 2022年度盘点 PART Ⅲ
博客主题与原地址:语言模型、计算机视觉、多模式模型、生成模型、负责任的人工智能、机器学习与计算机系统、高效深度学习、算法进步、机器人学、自然科学、健康、社区参与
1 负责任的人工智能
谷歌AI的应用原则:
- Be socially beneficial.
- Avoid creating or reinforcing unfair bias.
- Be built and tested for safety.
- Be accountable to people.
- Incorporate privacy design principles.
- Uphold high standards of scientific excellence.
- Be made available for uses that accord with these principles.
1.1 为什么ML落地时常表现欠佳
当机器学习 (ML) 系统用于现实世界环境时,ML可能无法以预期的方式运行,从而降低了系统实际收益
其中最常见的问题是“虚假相关性(spurious correlations)”和“捷径学习(shortcut learning)“
- 在基于医疗图像的疾病诊断分类任务中,不同类型的相机拍摄图片对应的预测精度存在差异
- 在针对性别歧视的语义理解中,不同模型虽然最终预测精度近似,但并不是都能理解偏见的成因
- 通过RNN预测AKI未来一周就诊人数时,模型并不能理解就诊人数与科室工作节奏的关系
检验捷径学习问题的测试方法:
- 分层表现评估(Stratified performance evaluations):选取特征并进行数据分层,判断不同层之间的模型表现稳定性
- 迁移表现评估(Shifted performance evaluations):对数据进行分布变换(人为干扰),判断模型表现的稳定性
- 对比评估(Contrastive evaluations):搜集各种特殊样本,作为模拟极端场景的测试用例,判断模型的稳定性
针对已有的医疗AI公平诊断,本人筛选了谷歌的两篇论文进行了精读:
- 基于因果框架的医疗领域数据分布偏移评估:本文基于因果框架提出了一种通用的分布偏移检验算法,能独立于场景适用于多种类型数据的偏移检验,最终结果包含针对每一项特征的检验p值,并以联合因果图的形式说明分布的结构偏移
- ShorT:用于医疗AI公平的捷径学习检测和预防:本文在多任务学习的基础上,借助敏感属性的编码程度和模型公平性的负相关性来识别和量化捷径学习,还通过实验分析了抽样法和反向梯度更新这两种缓解策略对模型公平性和预测性能的影响
1.2 如何更好地增强AI的责任感
谷歌提出了很多改善模型泛化/增强模型鲁棒性的方法:
- 基于负增强的视觉转换器(ViT)鲁棒性的理解和改进:本文通过设计基于图像块、破坏语义的转换对模型进行了“负面增强”,借鉴了对抗训练+对比学习的思路避免模型学习到这类不合理(不符合人类语义)特征,从而提高ViT类模型的鲁棒性
- 提升视觉变换器(ViT)对图像块级扰动的鲁棒性:本文通过实验分析发现ViT模型面对图像块级别对抗性干扰时更加脆弱,基于此现象本文提出了基于温度缩放的平滑注意力,通过阻止注意力集中于单一图像块,从而有效提高了ViT类模型的鲁棒性
- 文本分类器模型鲁棒性改进的集成方法研究:本文首先基于“简单”子集(偏差训练集)和弱学习器训练偏差模型,之后通过“困难”子集(偏差挑战集)找到的最优偏差模型,最后通过PoE方法与主模型融合,避免主模型学习到偏差特征。最终模型在文本推理任务中表现出更好的鲁棒性。
同时谷歌也期待通过外部社区使用参与式系统来指导模型的评估(什么时候是对的?为什么是对的?),这种做法明确了预测结果的民主所有权,也尊重个人是否愿意披露敏感信息的遗愿;
除此之外,还需要避免性别偏见、重视文化差异和审计问责
- 比如推进对不公平性别偏见的更准确评估,减轻对少数性群体的伤害
- 使用联邦学习等方式以更好地理解文化差异,增强模型的跨文化考虑
- 问责制是负责任AI的必要条件,可以通过审计和可解释性等透明机制来促进
AI的能力来源于对人类的模仿,所以AI不可避免地带有人类的价值观,这份价值观一般是常见的,但并不一定是正确的
一项在印度的调查问卷分析表明,在不充分证据证明AI能力的情况下,有79.2%的人接受AI的建议;这表明AI具有影响人类行为的能力,也间接说明,人类急需一套更严谨而负责的AI规范,来减轻AI对人类或社会的可能负面影响
1.3 以人为本的AI辅助设计与创造力
不同于传统机器学习(ML),大语言模型可以通过使用自然语言提示来降低人们进行原型设计的门槛,诸如设计师、项目经理、前端开发等人士可以通过提示工程的方式加快原型设计,减少沟通障碍。但也要注意针对提示设计的逆向工程、以及更有效的调试和评估
此外,谷歌还引入了AI链(AI Chains)的概念——将LLM步骤链接在一起的概念,其中一个步骤的输出成为下一个步骤的输入,从而汇总了每个步骤的收益。最终用户可以通过模块化的方式修改这些链及其中间结果,该方法不仅提高了任务结果的质量,还显著增强了系统的透明度、可控性和协作意识。此外,还可以利用子任务来校准模型期望,通过“单元测试”来调试导致意外输出的子组件/链
People + AI Research (PAIR) 是 Google 的一个多学科团队,通过进行基础研究、构建工具、创建设计框架以及与不同社区合作来探索以人为本的 AI 。该团队认为,为了使机器学习发挥其积极潜力,它必须是参与性的,涉及它所影响的社区,并由不同的公民、政策制定者、活动家、艺术家等指导。
PAIR的团队主页有较为丰富的内容分享,包括GuideBook,EXPLORABLES,TOOLS,RESEARCH和EVENTS
本文筛选了两篇PAIR团队在2022年比较重要的研究成果进行分享:
- Saliency:基于显著性图检测模型偏差:本文通过常用的遮挡、梯度等方法对模型的偏差进行识别;之后本文基于显著性图,提出了区域显著像素占比这一指标用于量化模型的偏差;最后本文探索了目前常见的识别模型偏差和模型可解释性的方法与路线
- 通过联邦学习保护隐私:联邦学习能够在用户不共享私人数据的情况下互相协作训练模型,一个简单的方式是用户本地训练模型后,使用服务器进行模型的组合;而更合理的方式是通过加密的方式进行安全聚合(输入添加随机数,输出剔除随机数的影响,中间过程不可见);由于数据的不可见,联邦学习很难检测并处理异常值,并且离群样本对模型的影响也可能会引发隐私问题(所以要注意限制单个样本对模型的贡献,同时添加随机噪声,来提高模型的差异隐私性)
用AI激活人类的创造力:
- 谷歌团队构建了一个作家工坊,探索人工智能辅助创意写作的潜力和局限性
- 论文探究了专业作家对自然语言生成 (NLG)作为写作创意助手的评价;整体来看专业作家一般拥有独有的风格和受众、完善的写作体系和方法,而NLG 技术难以保持风格,并且缺乏对故事内容的深刻理解
- 论文1和论文2则分别探究了AI对服装设计和音乐领域的影响(风险和机遇并存)
1.4 模型的可解释性探索
本小节在原文中一笔带过,本文根据引用的论文进行了内容扩展
训练数据归因 (TDA),即确定哪些训练样本会导致模型产生特定的事实断言
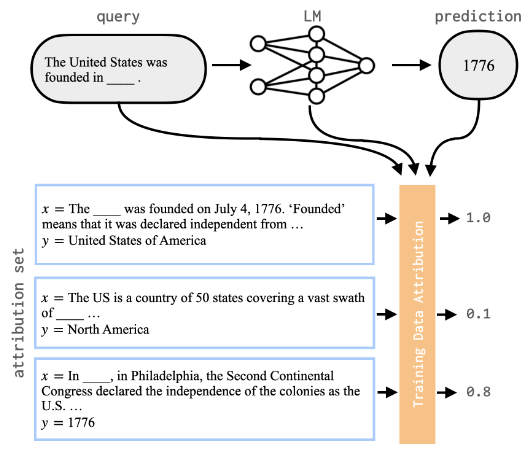
- 常见的两种数据归因方法包括:基于梯度的归因和基于嵌入表示的归因
- 基于梯度的经典TDA算法是TracIn:跟踪训练过程,捕获各个训练样本被访问时预测的变化,最终得到每个训练样本的影响力得分,有助于对训练过程的理解,也能有效识别到数据中的错误样本或离群点
- 基于嵌入的方法思路则相对简单,但效果一般优于基于梯度的方法;由于嵌入层包含着对相似性搜索有用的高级特征,所以可以直接根据余弦相似度查询到与当前样本最相似的训练样本
- 谷歌团队联合MIT开源了评测数据归因的基准数据集FTRACE,最终模型评测如下(其中BM25是基于单词重叠度构建的基线,其在 MRR 方面的评价表现优于神经方法。。。)
IMACS:评估图像模型之间的属性差异
- 模型之间常通过性能指标(ROC、混淆矩阵等)进行比较,这种方式可能会遗漏模型的深层特征;本文介绍了一种将模型属性和可视化相结合的方法(IMACS),用于总结两个图像模型之间的属性差异
- 具体来说,IMACS先通过采样的方式平衡混淆矩阵(真阳、假阳、真阴、假阴),然后分割图像并计算每一个图像片段的Shapley值(描述了该图像片段对模型预测的贡献度),根据第三方模型的嵌入层对图像片段进行聚类,以识别相似特征集。
- 实验测试使用包含5 类(郁金香、雏菊、蒲公英、玫瑰和向日葵)花卉的 3,670 张图像。模型A正常训练,而模型B的“向日葵”类训练样本会有50%的概率随机添加水印(即人为构建有偏模型,方便验证模型的对比效果)
- 最终两个模型的可视化对比如下所示(横轴表示特征贡献度,仅展示了聚类结果中的其中一个簇):

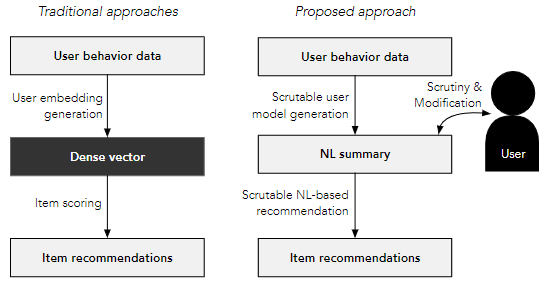
基于自然语言用户画像的透明和可推导的推荐:使用自然语言表示用户偏好的算法可以显着提高推荐算法的透明度,并能够更友好地提供可行建议或者进行结果的约束控制;使用此类算法的推荐系统也能减少对嘈杂隐含观察的依赖,也增加了个人兴趣知识的可移植性
1.5 促进AI责任感的产品改善
谷歌团队联合MIT教授,发布了Monk肤色量表(MST),旨在更全面地涵盖全球范围内的肤色,改善图像技术对有色人种的忽视和误解(比如改善图像搜索和相册筛选器的多样性和肤色表现)

另一方面,谷歌搜索也进行了很多优化:
- 利用对自然语言反事实数据增强的研究来改进安全搜索,将不合理的搜索结果(种族、性取向和性别相关)减少了 30%;
- 着重优化了搜索自杀、性侵犯、药物滥用和家庭暴力等相关的信息所得到的搜索结果(如全国热线,自求措施等);
- 改善面向未成年人的安全搜索模式,即使关闭安全搜索也会尽量理解搜索意图,尽量减少不合理搜索结果
- MUM 是21年就提出的搜索模型,语言理解能力强(基于T5模型,复杂度高于BERT),跨模态(理解图像和网页),消除语言障碍(训练使用75种语言),安全性高(评估流程严格,人工评分辅助,尽量减少模型偏见)
- 从人类标记的违规区域中提取每帧视觉和音频特征来生成训练数据集
- 聚合视频片段上的帧特征,训练关于违规策略的细颗粒多标签模型
- 模型预测输出作为“提示”给人工评分者,一级“提示”以折线图的形式展现可能存在违规的时间轴
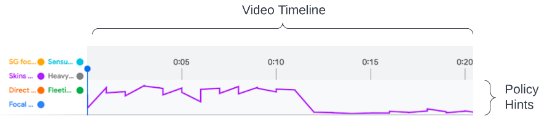
- 二级“提示”则会展开,预填充模型预测违规的视频片段及其违规类型,减少人工标注成本
- 人工验证/更正标签用于模型的完善,最终建立一个高效的人类-ML 正反馈循环
- 最终实验结果表明,视频违规片段有56%是模型创建的,细分违规类型的接受率为35%,而“生成”模型的 AUC 也提高 5-8%,但审核的整体耗时增加了3%(但是长视频的审核耗时减少明显,违规视频的注释数量增加明显)
实际操作中,模型给出的“提示”还会限制显示片段的数量以防止信息过载,对相近(间隔<视频总长度的3%)相似的片段进行合并以避免视觉混乱,并借鉴排名算法对片段进行优先级排序。
基于多任务训练框架处理标注分歧的问题:本文提出了一种基于多任务学习框架的训练方式(把每个标注者的标注结果看作一种预测任务,不同任务间共享模型的学习表示),处理标注分歧问题,并在实验分析中实现更好地性能表现。
1.6 增强AI责任感的数据和工具
模型卡(Model Cards):
- 模型卡的目标是以结构化的方式组织机器学习模型,包含模型的类型,输出形式,性能评估,局限性等信息
- 语言翻译类的模型卡也可以很多进阶信息:包含关于行话、俚语、方言,或衡量模型对拼写差异的容忍度
- 模型卡可以面向开发人员进行模型强化或限制,也可以面向专家引入专业意见,面向普通观众也能降低技术的理解门槛
- 模型卡应保持足够的透明度,需要更多的参与者,并由所有参与者共同维护(因此模型卡是独立于谷歌的一项产品)
- 目前模型卡工具包(MCT)使用JSON格式存储模型信息,支持模型信息的自动抽取和手动录入
数据卡(Data Cards):
- 数据卡的目标是以结构化的方式组织ML数据集,包括数据的来源、发展、概述、示例、意图、使用情况等信息
- 和模型卡一样,数据卡也在追求不同数据说明文档的一致性和可比性,增强信息的透明度和互惠共享
- 目前谷歌提供了数据卡使用指南提供为数据创建数据卡的用户指南和基础模板,也存储并分享已有的数据卡
谷歌团队尝试提出一个行业标准来存储和共享ML相关模型和数据的信息,初衷是很好的,可惜不是所有人都会买账。至少截至20230629时,数据卡的上次更新时间已经是4个月前了,明显缺少大众的广泛参与和官方的积极维护
近期开源的数据集:
- “Sensitive Terms”(敏感字词)数据集:包含被 37 个来源认定为有害、敏感和有问题(刻板印象、种族歧视等)的 590 个单词和词组,可检测文本生成类模型的公平性。更多细节查看该数据集对应的数据卡
- Toxicity(毒性检测)数据集:包含 10,000 个帖子及其评论的数据集,用于辱骂或攻击性文本的检测;该数据集的特点是具备评论回复的上下文,有助于提高审核辅助模型的质量。更多细节可查看该数据集对应的原始论文
- Societal Context(社会语境)数据集:由谷歌 SCOUTS 团队与 Perspective 合作推出,该数据集包含与种族、宗教、年龄、性别或性取向等类别相关的身份术语。通过对训练集中不同身份的数据进行平衡和补充,有助于减少模型的错误偏见
Perspective 使用机器学习,提供一种识别有害、不合理、冒犯性或其他“有毒”评论的免费 API
近期开源的工具:
- 学习可解释性工具 (LIT):一个用于可视化和理解 ML 模型的开源平台,现在支持图像和表格数据。该工具已在谷歌广泛用于调试模型、审查模型发布、识别公平性问题和清理数据集。
- Counterfactual Logit Pairing (CLP):提高了模型对敏感属性扰动的稳健性(比如说针对毒性文本检测任务,评论者的性别变化不应该成为影响毒性检测的依据),并且可以积极影响模型的稳定性、公平性和安全
1.7 人工智能的社会效益
- 基于AI的个性化语音识别,使得发音不标准的人能够更轻松地与他人交流
- 该应用目前支持供澳大利亚、加拿大、加纳、印度、新西兰、英国和美国的 18 岁以上英语使用者
启动语音无障碍项目
- 该项目计划构建一个大型的语言障碍数据集,以增强无障碍应用程序的研究和产品开发
- 该项目还会尝试利用目光追踪技术来帮助患有严重运动障碍和语言障碍的人群
健康领域
- 用技术改善存在慢性健康隐患的人群生活,同时解决系统性不平等问题,并允许透明的数据收集
- 借助健身传感器和手机等搜集到的健康数据,实现了对多发性硬化症的有效预测(以前都是用神经影像数据)
- 通过预测干预措施提高临床风险评分的可解释性:具体来说,该论文基于MIMIC-Ⅲ数据进行多标签(死亡风险+13项干预措施)学习,基础模型为逻辑回归,多标签学习模型为LSTM(参考的开源代码。最终模型表现优于单独的死亡风险建模,同时预测输出的风险评分在结合干预手段后也具备了更好的可解释性。
- 针对消费和数字健康应用程序中的跨性别和X性别用户进行大型国际研究,探索模型的公平性实现
媒体领域
- 联合多个机构,针对12年,440 多个小时的电视节目进行分析,描绘了不同肤色、不同性别、不同年龄在屏幕和说话时长方面的显着差异。该研究报告借助AI技术了解媒体的演变过程,最终目标是激发主流媒体的公平性。
2 机器学习和计算机系统
Great machine learning (ML) research requires great systems.
2.1 分布式机器学习系统
Google Cloud TPU v4 Pod 部分图:

- TPU v4 芯片提供的计算能力是 TPU v3 芯片的 2 倍以上,每个 Pod 都能够提供超过 1 exaflop/s 的计算能力
- 4,096 个 TPU v4 芯片通过超高速互连网络连接到一个 Cloud TPU v4 Pod,每个芯片的带宽比传统训练系统高 10 倍
- 480B 参数模型在2048个 TPU 上端到端训练时间约为 55h,200B 参数模型在1024个 TPU 上端到端训练时间约为 40h
- TPU v4 的超快互连消除了网络中的延迟和拥塞,因此整个训练过程中的计算效率为 63% ,处于行业领先水平
CollectiveEinsum 策略:
- CollectiveEinsum 是谷歌2022年最大的效率改进策略,该策略最终实现了1.38 倍的性能提升
- CollectiveEinsum 主要用于评估神经网络核心的大规模矩阵乘法运算,是有效扩展 Transformer 推理工作的关键组成部分
- 不同于以前将通信与设备本地计算分开的 SPMD 分区策略,CollectiveEinsum使用快速 TPU ICI 链接来重叠通信,减少数据通信开销并缓解数据传输延迟,最终实现了更好的系统利用率,峰值FLOPS利用率为72%
单程序多数据(Single program, multiple data,SPMD)是一种常用的并行技术。在SPMD中,一个程序同时启动多份,形成多个独立的进程,在不同的处理机上运行,拥有独立的内存空间,进程间通信通过调用MPI标准接口来实现。
TPU ICI (Inter-Core Interconnect)理解:原始通信集合及其计算操作,可以拆分为更细粒度的操作,也因此创造了更多的通信重叠机会,最终产生可并行执行的、新创建的、更细粒度的通信和计算操作。更多关于CollectiveEinsum和ICI的细节可参阅原文
DTensor extension和 JAX也开始集成了SPMD式分区的概念,这两个工具可以在不改动代码的情况下拓展为多设备程序
DTensor是用于分布式计算的 TensorFlow 扩展程序。DTensor 提供了一个全局编程模型,使开发者能够编写以全局方式在张量上进行运算,通过将应用与分片指令分离,DTensor 可以实现在单个设备、多个设备甚至多个客户端上运行相同的应用,同时保留其全局语义。
JAX 是用于高性能数组计算的工具,提供Numpy风格的API,同时也支持自动分布式计算
Alpa 自动化模型并行深度学习:
- 已有的GSPMD 严重依赖启发式方法来实现分区自动化推理,但有时仍需要手动做出重要决策(影响性能)
- Alpa能探索算子内部和算子之间的pipeline并行性测量,实现完全自动化分区推理,并且能达到手动调整时的性能
GSPMD,一种基于编译器的自动并行化系统,用于常见的机器学习计算。它允许用户以与单设备相同的方式编程,然后通过一些有限的用户注释推断不同操作的对应分区,从而给出如何分配张量的提示,最终在此基础上实现并行计算。GSPMD分区表示简单而通用,能在各种模型上表达不同或混合的并行范例
下图展示了Apla的主要工作流程:
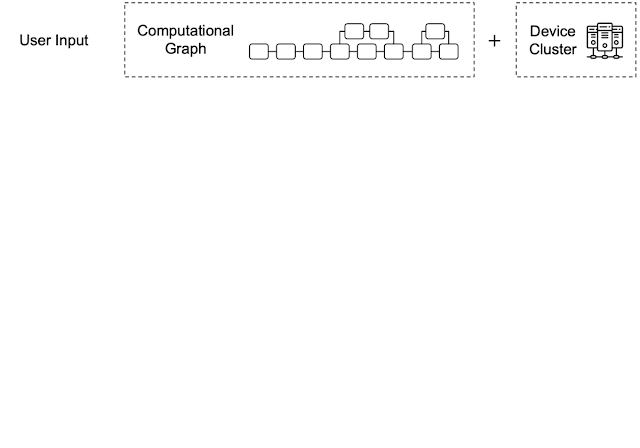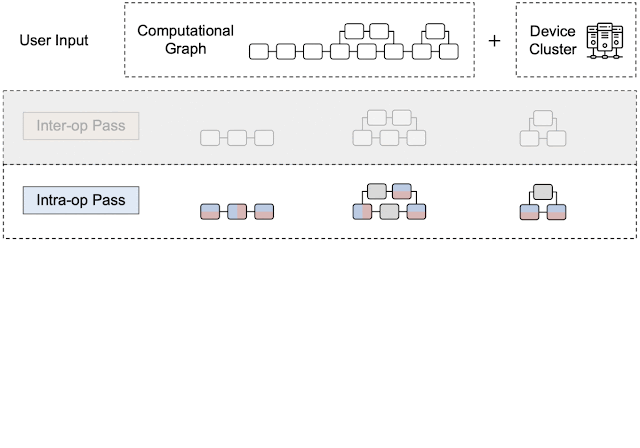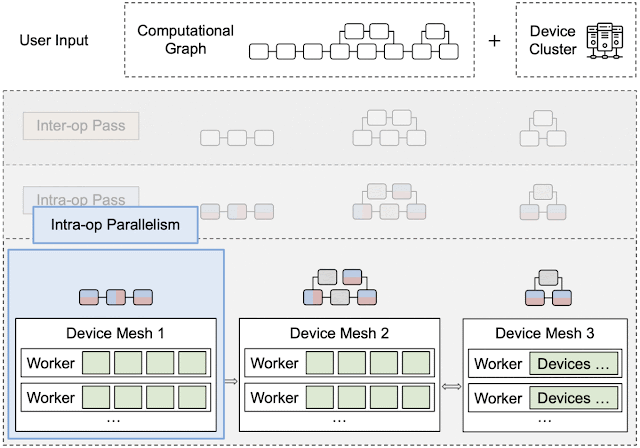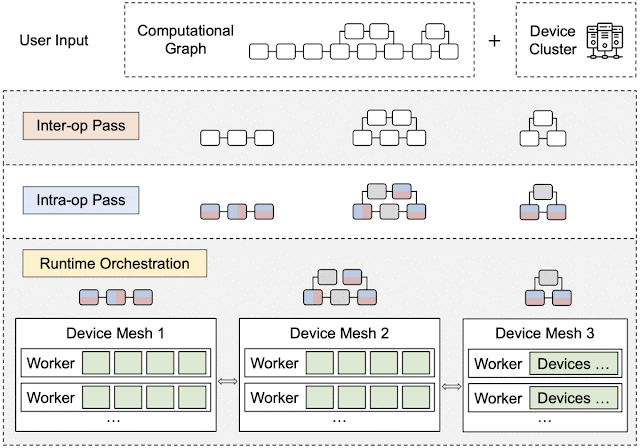
- 在初始输入阶段,用户需要设定好设备集群(Device Cluster)并输入计算图(Computational)
- 在算子间处理(Inter-op Pass)阶段,计算图被分割为子图,设备集群被分割为子网格(即分区的设备集群),并确定将子图分配给子网格的最佳方式。最佳分配方法主要通过动态规划算法实现,算法追求总运行延迟最低
- 在算子内处理(Intra-op Pass)阶段,每个字计算图的pipeline阶段通过张量划分为每个独立算子(如矩阵乘法)定义一组并行化策略;因为一个张量既可以是一个算子的输入,也可以是另一个算子的输出,因此张量划分可能存在冲突并需要额外的通信成本进行重新分区;所以本阶段会考虑将算子内传递公式化为整数线性规划(ILP)问题,LIP追求计算和通信成本最小
- 在运行编排(Runtime Orchestration)阶段,对计算和通信操作进行排序,生成最终的静态计划(不同子网格间分派执行不同的静态指令序列,子网格内设备间执行相同的静态指令序列),用于指导在实际设备集群上执行分布式计算图
Pathways 系统在提高效率和容错率的同时,能够轻松实现跨TPU pod的多任务计算,更多信息可参考盘点 PART Ⅰ
TensorStore 是一个用于多维数组存储的新库,能提供数据库级保证 (ACID),适合多控制器运行的大语言模型(LLM)训练
2.2 用于机器学习的编程语言
MLIR 项目致力于构建更加可控、可组合和模块化的编译器堆栈。MLIR 旨在解决软件碎片问题,改进异构硬件的编译,显着降低构建特定领域编译器的成本,并帮助联合现有编译器在一起。
IR,也就是中间代码(Intermediate Representation,有时也称 Intermediate Code,IC),它是编译器中很重要的一种数据结构。编译器在做完前端工作以后,首先就是生成 IR,并在此基础上执行各种优化算法,最后再生成目标代码。
根据抽象层次的由高到低,IR还可以继续分为HIR、MIR 和 LIR 三类。参考来源
IREE (Intermediate Representation Execution Environment) 是一种基于 MLIR 的端到端编译器,可将机器学习 (ML) 模型程序降低为统一的 IR,也可以灵活扩展以满足不同数据中心,还充分考虑到了移动和边缘部署的特殊场景与限制。
𝛼NAS:神经网络架构搜索(NAS)改进
- 利用抽象解释和程序合成等编程技术,成功减少了执行NAS所需的资源成本
- 𝛼NAS能在任意神经架构上定义的一组程序属性,执行搜索空间更小的抽象搜索空间
- 𝛼NAS使用进化算法训练出一个高效的合成过程,在接受一组程序属性后返回合理的神经架构
- 在保证准确率的情况下,𝛼NAS能搜寻到更有效的神经网络模型架构
2.3 硬件加速器和机器学习
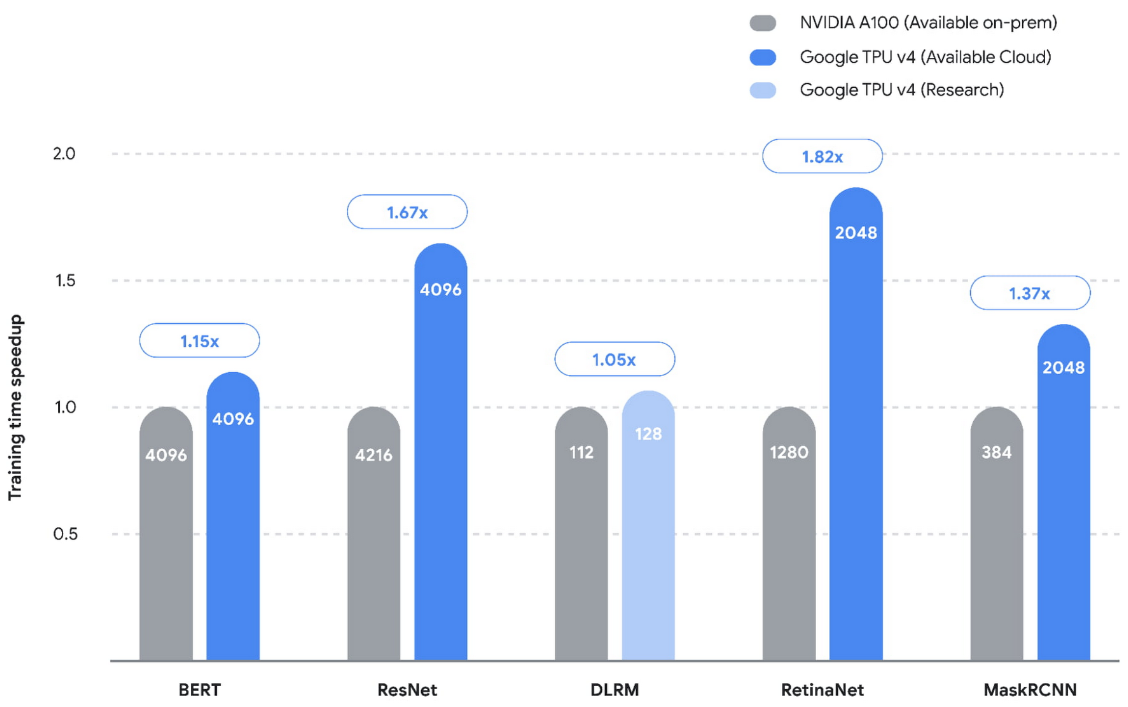
TPU v4 在MLPerf,的五个基准测试中创造了新记录,比之前的最优性能平均提高了1.42 倍:
全栈搜索技术(Full-stack Search Technique,FAST)
- 通过引入硬件器加速搜索框架来缩短设计周期时间,降低硬件加速器构建的高昂初始成本
- 该框架可同时优化数据路径、调度和重要的编译器决策,涵盖了软硬件堆栈中的关键设计
Circuit Training 是一个开源框架,用于通过分布式深度强化学习生成芯片平面图。Circuit Training 能够使用数百个宏来优化芯片模块,可在数小时内自动生成平面图,而基线方法通常需要人类专家参与循环,并且可能需要数月时间。
PRIME引入了一种基于 ML 的方法来搜索硬件设计空间,该方法仅利用记录的加速器数据(包括可行和不可行的加速器)和相应的性能指标(如延迟、功耗等),而PRIME不需要任何进一步的硬件模拟就能构建硬件加速器。与最先进的仿真驱动方法相比,PRIME 的性能提高了约 1.2 倍至 1.5 倍,同时将仿真时间缩短了 93% 至 99%
平台感知神经架构搜索(Platform-aware NAS)
- 通过将硬件架构知识融入 NAS 搜索空间的设计来弥补传统NAS因缺乏硬件知识而受到的限制
- 一个关键的调整是最大化并行性,以确保加速器内的不同硬件组件尽可能高效地协同工作
- 最大化模型算术强度(即优化高带宽内存上的计算和操作之间的并行性)对于实现最佳性能也至关重要
- 其生成的 EfficientNet-X 模型在 TPU v3 和 GPU v100 上分别比 EfficientNet 快 1.5 倍到 2 倍,且精度相似
2.4 机器学习用于受限搜索空间导航
Telamalloc技术优化中间层搜索
- 中间层主要考虑分区器(将工作负载映射到多个设备)和编译器(将工作负载转换为硬件可理解的机器码)
- Telamalloc 采用 ML 模型和启发式相结合的方式进行多选项的决策,并利用约束求解器来推断进一步的决策
- Telamalloc 基于启发式搜索与求解器相结合来指导其决策,效果显著由于传统的整数线性程序 (ILP) 求解器
- Telamalloc 使用机器学习来不断改进对工作负载长尾的搜索,实现了高达两个数量级的分配时间加速
- 使用深度强化学习(RL)框架来提出候选分区策略,然后通过约束求解器纠正该策略(剔除可能无效的策略)
- 使用约束求解器确保RL能够经常在稀疏空间中找到有效的解决方案,相比非学习策略所需样本量显著下降
- 相比于非学习搜索策略,该方法使用更低时间成本(3小时减少到9分钟)发现了模型在设备之间更好的分布
2.5 机器学习用于大规模生产系统
MLGO——第一个工业级通用ML部署框架
- 将 ML 技术系统地集成到 LLVM (一种开源工业编译器基础设施,常用于构建关键的高性能软件)
- MLGO 使用强化学习 (RL) 训练神经网络,用于替代 LLVM 中的启发式方法来做出优化决策
- MLGO 使得决策时的binary size减少 3%–7%,优化寄存器分配决策时的吞吐量提高 0.3% ~1.5%
XLA用于指导ML 工作负载选择 TPU 内核的最佳切片大小,从而节省了数据中约 2%总 TPU 计算时间
YouTube 缓存替换算法中的启发式算法也被替换为简单启发+学习模型,使得峰值字节丢失率改善约 9%
2.6 人工智能与可持续发展
通过遵循“4M”规范,机器学习从业者可以将训练中的二氧化碳当量排放量 (CO2e) 减少几个数量级:
- 模型(Model),选择最高效的ML模型架构,比如Primer比Transformer训练快4倍
- 机器(Machine),选择最节能的计算机,比如TPU v4相比于以前的P100每瓦性能提高约 15 倍
- 机械化(Mechanization),大型云数据中心的能效一般比常见小型数据中心高约1.4倍
- 地理位置(Map),选择合理的地理位置能极大地改善能源供应的清洁度(试验为9倍)
3 高效的深度学习
3.1 高效架构
解耦上下文处理上下文增强语言建模:本文提出一种基于编码器-解码器架构的上下文增强语言模型,通过上下文编码的离线预计算和缓存生成,实现了具有上下文编码和在线语言推理分离的独特计算优势。最后,本文通过语言生成和问答实验分析,验证了这种简单架构的有效性,并表明上下文增强对模型的巨大改进
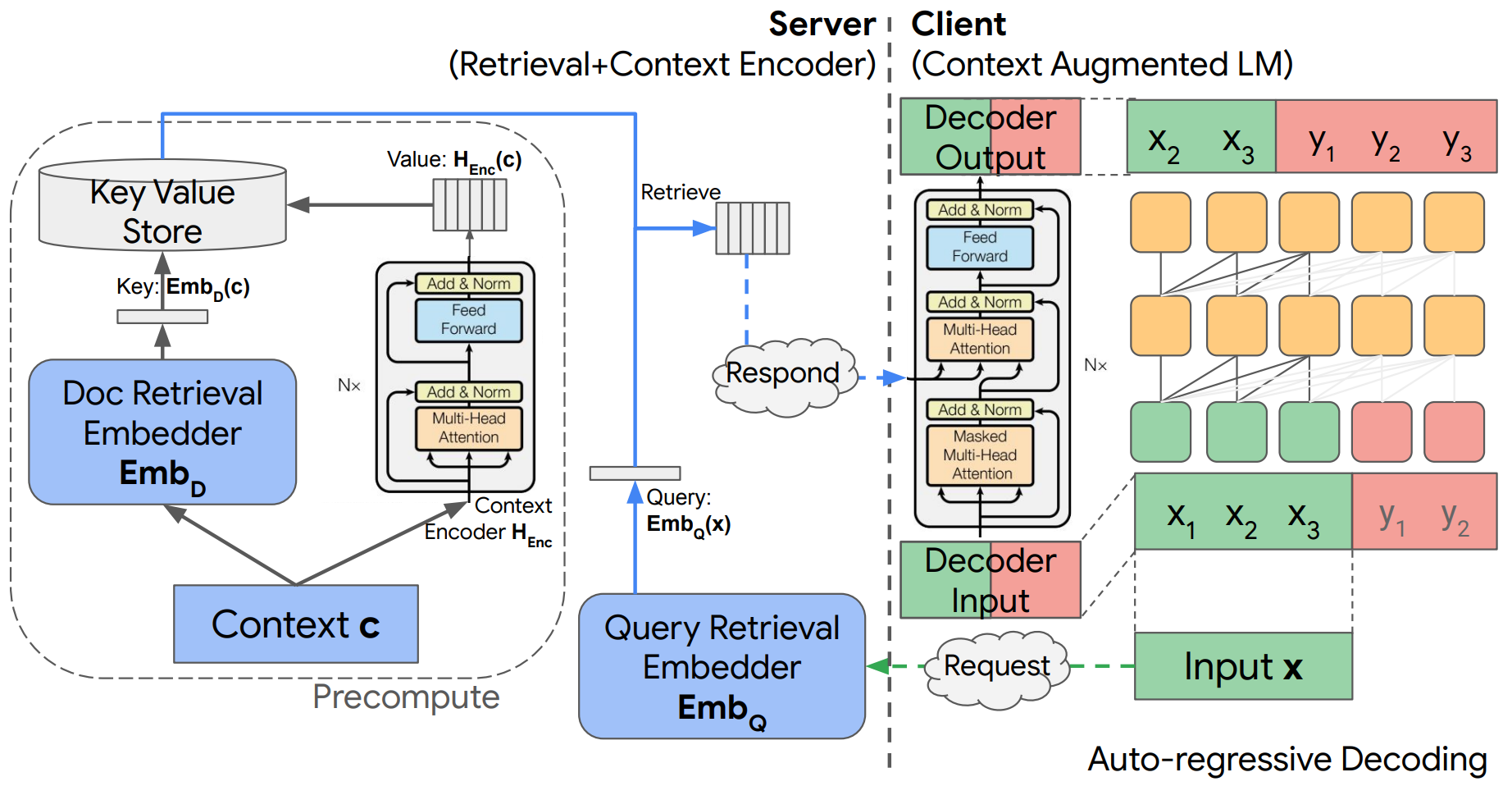
上下文增强模型的另一个挑战是如何更快得从大型数据库中检索信息:
- 谷歌团队基于TPU设计了一种高效的K最近邻搜索(KNN)算法,该算法针对内存和指令瓶颈进行了优化。实证结果表明其优于最先进的 GPU 求解器,并已集成到Tensorflow中
- 除此之外,搜索算法通常涉及大量的超参数和设计选择,这使其很难快速调整以用于新的任务。谷歌团队提出了一种新的约束优化搜索算法,给定搜索成本或召回率后,该算法会自动调整超参数,并在基准测试中实现了较高的效率(计算成本低,搜索到的超参质量好)
基于激活网络的稀疏子图网络能显著降低推理成本:
- 典型的Switch Transformer 通过专家混合 (MoE) 机制,在接受输入后只激活特定的子网络进行推理,从而显著降低模型推理所需的参数量;另一种方式的将输入映射到一组子网络(依然小于完整网络),并以加权的方式聚合输出
- 谷歌则提出了一种具有一个或多个稀疏激活层的网络模型,其中的稀疏激活层能根据输入来决定不同子网络是否被激活以及激活后的权重系数;为了更好地从理论上分析网络中的稀疏激活层,谷歌团队还使用基于局部敏感哈希(LSH)的路由评估稀疏网络的逼近能力
- 另一方面,谷歌提出了一种专家选择路由(Expert Choice Routing),该方法不再使用 top-k 函数为每个token分配固定数量的专家(可能存在负载不均衡或者专家训练不足的问题),而是让让专家选择前 k 个token(每个token可被路由的专家数是可变的,而每个专家都具有了相对固定的存储桶大小),并最终以更快训练收敛速度得到更优的性能表现
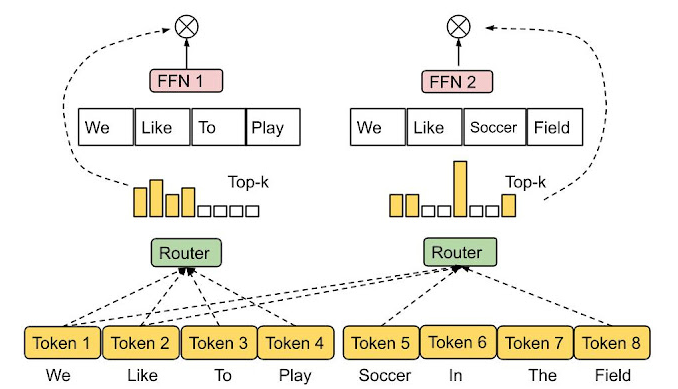
大模型的稀疏性说明模型可以在不影响性能的情况下减少FLOP
- Treeformer将注意力计算转化为基于决策树的最近邻检索问题,给定查询后使用密集梯度树来检索需要关注的TopK键。此外,作者还开发了一种bootstrapping+自监督学习方法来逐步训练TreeFormer模型的稀疏注意力层,使用反向传播将决策树训练为神经网络的一部分。 最后TreeForme在保持与标准 Transformer 架构相匹配的精度;TreeFormer的注意力层计算成本( FLOPs)降低了 30 多倍,与 SOTA BigBird 相比,成本降低了 9 倍
- 顺序注意力 Sequential Attention实现了一种将注意力机制与经典前向贪婪算法相结合的可微特征选择方法,相关数据和代码也是公开的
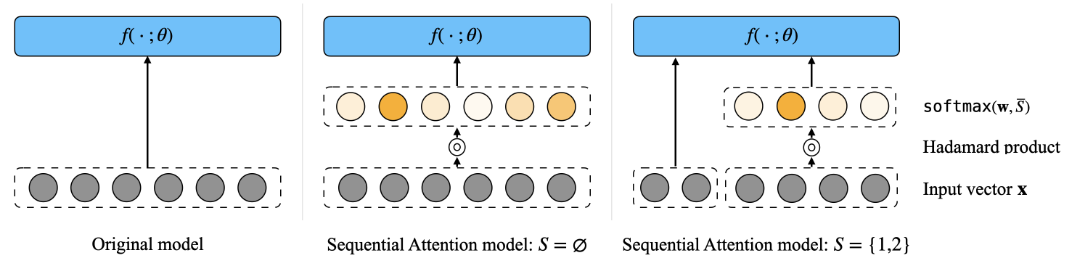
提高 Transformer 效率的另一种方法是加快注意力层中的 softmax 计算速度:
- CRT(Chefs' Random Tables)是一类新的非三角随机特征 (RF),用于逼近高斯和 softmax 内核;它提供了第一个 softmax 内核的“正且有界”随机特征近似,并且在序列长度上是计算线性的
- 谷歌团队还首次提出了一种综合方法,以可扩展的方式将各种屏蔽机制(比如因果和相对位置编码)合并到 Transformers 架构中
3.2 训练效率
Adam 等自适应梯度方法允许对LLM进行稳健训练,但需要使用额外内存为代价。
SIBERT针对BERT模型进行网络和训练层面上的改造,使其配合普通的SGD(随机梯度下降)就可以实现高效稳健的训练效果(下游任务表现类似于Adam的训练效果):
- 改造1:修改网络架构以实现尺度不变,即参数值的整体缩放不影响网络的输出
- 改造2:添加L2正则项来约束参数以实现参数衰减,配合SGD达到类似学习速率衰减的效果
- 改造3:梯度裁剪,裁剪上界与标准参数值、参数衰减率和学习速率有关
LocoProp使用与一阶优化器相同的计算和内存资源,实现了二阶优化器类似的性能:
- LocoProp考虑将神经网络分解为以层为主的模块化组合;网络的每一层都分配了独立的权重正则化器、输出目标和损失函数(损失函数要与激活函数是相匹配的)
- 每一层都可以单独训练实现局部损失的最小化;不同层之间的训练也可以是并行的
- 实验结果表明,该方法的性能与高阶优化器相当,同时在单个GPU上运行时速度明显更快

LeCun在社交平台曾指责了LocoProp方法,认为其文中所提到的开创性名不副实;因为相似的思路在早年的目标传播(target prop)方法早已提出过了~
SGD 等优化器的一个关键假设是每个数据点都是从分布中独立且相同地采样的。但这在强化学习等实际环境中很难满足。为此谷歌团队提出了一种带有逆经验回放功能的 SGD(SGD-RER), 可用于线性动力系统、非线性动力系统以及强化学习的 Q 学习等场景的训练:
- SGD-RER通过构建多个缓冲区(Buffer),将数据按时间顺序(从左到右)进行保存
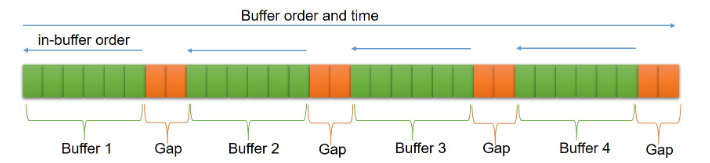
- 间隙(Gap)确保了不同缓冲区之间样本是相对独立的,训练时从左到右的考虑缓冲区
- 每个缓冲区内部数据会按照相反(从右到左)的顺序进行处理,比如进行标准的SGD
- SGD-RER方法在参数误差和预测误差方面都实现了接近极小极大最优错误率
- 该方法的增强版本IER也在各种主流 RL 基准上取得了最稳定、最先进的性能表现
3.3 数据效率
在大型数据集上训练深度神经网络会产生高昂的计算成本,一个合理的处理方法是进行数据子集的选择——即从训练集中找到信息最丰富的子集,以近似(甚至改进)整个训练过程。为此谷歌团队提出了一种名为 IWeS的算法,该算法通过构建样本重要性作为采样概率来选择数据子集,在算法性能上有明显的提高,并且适用于。
IWeS算法采样概率计算方法有两种:
- 在相同数据子集上进行不同的随机初始化,之后对比两个模型的熵一致性;样本在两个模型中熵的分歧越大,该样本被选中的概率越低:
$$p(x,y)=|P_f(y|x)log|P_f(y|x)-P_g(y|x)log|P_g(y|x)|$$ 2. 只训练一个模型(减少计算成本),然后将该模型的结果与随机猜测(从标签集合$\mathcal{Y}$中随机抽取)对比;该定义不需要使用真实标签,适用于主动学习/流式计算等场景: $$p(x,\cdot)=-\Sigma_{y'\in\mathcal{Y}}P_f(y'|x)log_2|P_f(y'|x)log_2|\mathcal{Y}|$$
训练大型网络的另一个问题是,它们可能对训练数据和真实数据之间的分布差异高度敏感,尤其是在训练数据有限,不足以涵盖所有真实数据场景的时候。为此,谷歌团队提出了DAFT 和 FRR两种方法来提高神经网络的鲁棒性:
- DAFT算法利用大量对抗鲁棒性的丰富特征来对教师网络进行标准训练,同时使用对抗性训练对学生网络进行指导,以此增强学生网络的鲁棒性(对较小的神经网络受益明显)
- FRR算法则在线性层鼓励模型使用更多样化的特征进行分类(以此摆脱线性分类头过度依赖简单特征的问题),在使用该方法优化线性层后,也可以再冻结线性层进行整个网络的微调,以细化模型所学习到的特征以更好地适应分类;最终该算法在具有极端分布变化的半合成数据集上展示了 OOD 准确性高达 15% 的增益
3.4 推理效率
蒸馏是一种简单而有效的模型压缩方法,它极大地扩展了大型神经模型的潜在适用性
- 在标记数据有限的情况下,使用无标记样本进行蒸馏是一种有效的方法;教师网络先用有标记数据上训练,之后针对无标注数据生成伪标签并用于训练实际部署的学生网络;同时该方法还会围绕教师网络预测的不确定性和学生网络损失函数的“扭曲”程度对样本重要性进行权重评估;该方法的特点是无超参、与数据解耦、易于实现,但最终效果取决于教师网络生成的标签质量
- 教师指导训练(TGT)框架则假设教师网络已经获得了对底层数据域的(低维流式)良好表示,除了使用教师网络构建伪标签外,TGT还会通过教师网络及其低维表示空间寻找信息最丰富的额外样本来帮助学生更快地学习;TGT适用范围广,效果出色(师生差异缩小了37%~63%),并且TGT还可以和其他主流蒸馏方法联合使用
- EmbedDistill是一种用于信息检索(IR)的知识蒸馏模型。该模型按照师生框架进行训练,先利用大型教师模型来学习的查询(Query)和文档(doc)之间的相对几何关系,之后采用嵌入匹配(Embedding matching)任务来提供更强的信号来对齐教师和学生模型的底层表示,以提高实际部署的质量和计算收益。此外,EmbedDistill还利用查询生成来探索数据流形,以减少训练数据稀疏的情况下学生和教师之间的差异(保留 95-97%)
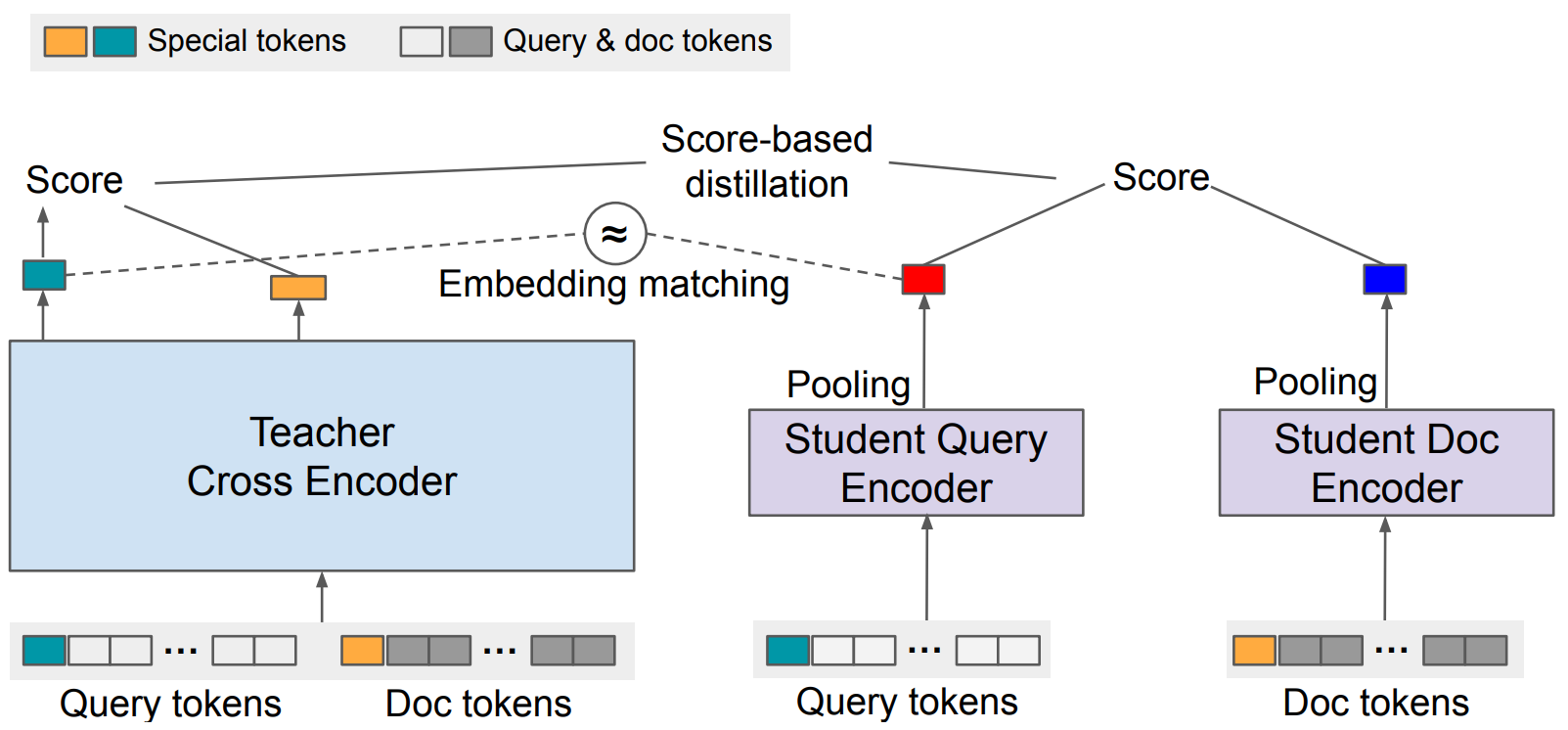
直观上讲,对于一些比较“简单”的样本,其所需要的计算量应该会少于“复杂”的样本。自适应计算就是基于这一思路设计的一种依赖于样本的计算机制:
- CALM框架通过动态为每个输入和生成时间步长分配不同的计算量,跳过中间无用的层(early exit),为基于Transformer架构大模型的推理提速。最终的实验分析表明,CALM 框架可以在保持较高的性能的同时实现高达3倍的推理加速
- 另一种流行的自适应计算机制是两个或多个基本模型的级联,使用级联的一个关键问题是决定是否将预测推迟到下游模型。在谷歌团队提出了提出了一种新的“学习推迟”(L2D)框架,该框架先在基础模型上设计合适的损失函数来训练延迟函数,之后决定何时推迟决策给专家——即预测模型错误的成本超过专家模型成本的时候
- 对于检索场景,标准语义搜索技术通过LLM将文本转化为固定长度文本嵌入表示;而套娃式表示学习则可以根据下游任务或者场景约束灵活调整嵌入表示的尺寸。该方法要求嵌入表示存在自然排序(训练线性分类器对每个嵌入层的不同尺寸进行相对重要性评估),这样在资源受限或精度足够的情况下,就可以只使用嵌入层的TopN维度;而在资源充足或精度要求高的场景下,就可以使用更多维度的嵌入表示;该方法在保持性能的情况下可实现最多16倍的推理加速