中文标题:CALM:可信的自适应语言建模
英文标题:Confident Adaptive Language Modeling
发布平台:NIPS
发布日期:2022-10-25
引用量(非实时):36
DOI:10.48550/arXiv.2207.07061
作者:Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, Donald Metzler
文章类型:preprint
品读时间:2023-09-08 18:45
1 文章萃取
1.1 核心观点
- CALM 框架通过动态为每个输入和生成时间步长分配不同的计算量,跳过中间无用的层(early exit),为基于Transformer架构大模型的推理提速。最终的实验分析表明,CALM 框架可以在保持较高的性能的同时实现高达3倍的推理加速(三种NLP任务,文本摘要、机器翻译和问答)。具体来说:
- 模型在训练阶段对所有层的预测进行加权平均,增强中间层的预测能力;
- 引入全局期望/风险一致性约束(确保early exit后性能不会下降)来构建局部衰减阈值
- 在推理阶段,使用局部衰减阈值对模型的early exit的置信度进行判断
1.2 综合评价
- 通过全局一致性约束,实现了自适应的局部衰减阈值
- 支持根据自定义容的忍误差和错误率来调控模型的early exit
- 本文的实验部分稍微简单一些,整体架构存在较多的人为设计
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
LM 中的饱和事件:排名靠前的预测在某些层之后保持不变并向上传播
常见的推理加速方法:
- 模型压缩:知识蒸馏(knowledge distillation)、浮点量化(quantization)
- 模型裁剪:层剪枝(layer pruning) 、向量丢弃(vector dropping,类似于dropout 的一种结构变体,在中间层暂时删除词向量,并在必要时在最后一层恢复)
- 仅使用完整网络的稀疏子集:如专家混合路由(MoE)、重复模块(在Transformer中引入RNN循环机制来实现参数复用)、访问外部存储器(保留模型推理能力,将记忆能力外迁)
- 基于early exit的自适应计算:常用方法包括使用内在的置信度度量(softmax分布)、提前预测路由(比如基于hash函数来为输入分配固定的退出层)、训练用于识别early exit的分类器
2.2 算法细节
本文提出的CALM框架主要在以下几个方面进行了改进:
- 调整损失函数的学习,不局限于使用最顶层进行预测,而是对所有层的预测进行加权平均,只是为顶层分配更高的权重。从而在保障模型性能的同时,增强中间层的预测能力
- 定义局部置信度,用来捕获模型对中间层预测的置信度,本文主要探索了3种度量方法: (a)softmax response,基于softmax分布计算最大预测概率(最简单快速) (b)state propagation,计算当前隐藏层表示与上一层表示间的余弦相似度 (c)early-exit classifier,专门训练用于预测局部一致性的分类器输出
- 设置用于 early-exit 的局部置信阈值。在初始阶段设定一个较高(保守)的阈值门槛,之后随着时间的推移逐步降低;置信阈值的衰减对于每层的每个token都是独立的:
$$\lambda^t=clip_{[0,1]}(\frac{9}{10}\lambda^{t-1}+\frac{1}{10}e^{-\tau\cdot t/N})$$
- 其中$t$是时间(层数),$\tau$是用户定义的温度,$N$是输出序列长度,$\lambda$)
- $clip$函数用来约束最终的置信阈值是在
[0,1]之间的数
为了更好地找到初始化$\lambda$,本文引入了一些额外的符号定义:
- $\Lambda=(\lambda_1,...,\lambda_k)$,$\lambda$的一组可能值,所有位置的$\Lambda$构成了问题的搜索空间
- $S_{cal}:={P_i}_1^n\in \mathcal{P}$,一个独立同分布(i.i.d)的校准集作为LLM的提示(Prompt)
- $Y_{early}$和$Y_{full}$分别表示LLM的自适应(存在early-exit)输出和标准输出;
- $Z_{test}$表示可用来参考的金标准输出;$\delta$为容忍误差,$\epsilon$为最低容忍概率

- 浅绿色阴影表示对应的token产生输出所使用层数少于总层数的一半
- 浅红色阴影表示对应的token产生输出所使用层数大于总层数的一半
- Rouge-L是NLP评价指标,通过计算最长公共子序列来评估文本生成的效果
本文定义了两种类型的一致性约束:
- 文本一致性约束:自适应输出和标准输出应该尽可能一致(距离$D$小于$\delta$)
$$P(E[D(Y_{early},Y_{full})]\leq \delta)\geq1-\epsilon$$ 2. 风险一致性约束:自适应输出相对于标准输出的预期损失增加$R$应尽可能小 $$P(E[R(Y_{early},Z_{test})-R(Y_{full},Z_{test})]\leq \delta)\geq1-\epsilon$$
$\Lambda_{valid}$表示满足两种一致性约束的$V_{}$,最终的$\lambda$取值是集合$\Lambda_{valid}$中的最小值
最终的CALM框架可表示如下:
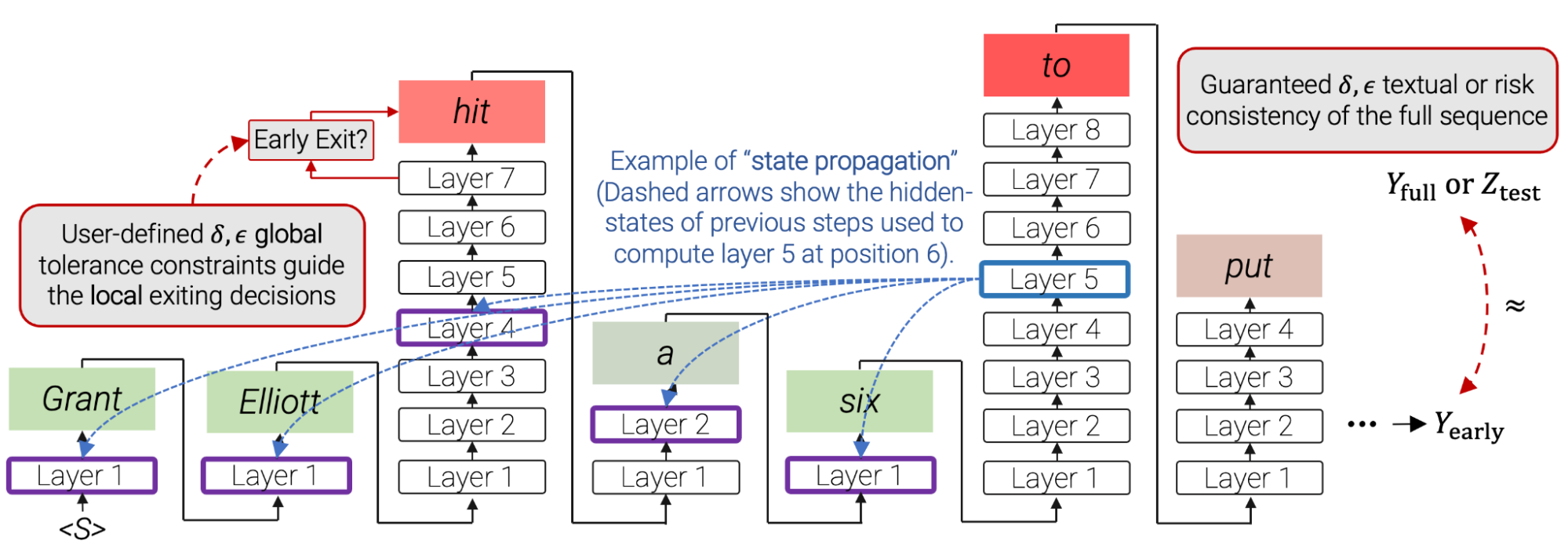
- 其中红色填充框表示使用层数较多的token,绿色填充框表示跳过层数较多的token
2.3 实验分析
模型在不同干扰和温度设定下的性能分析:
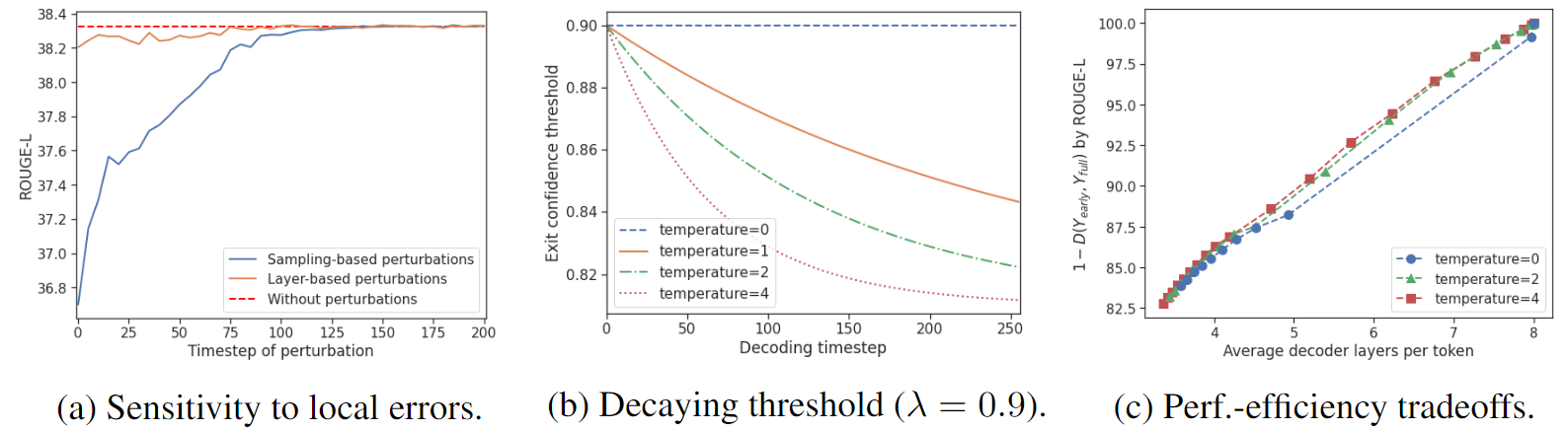
- 图(a)描述了不同噪声对模型输出的影响(干扰主要在早期,后面就被逐渐消解掉)
- 图(b)描述了不同温度设定对模型输出的影响,温度越高局,部置信阈值越低
- 图(c)中可知,全局一致性约束确保了模型输出在不同温度设定下都表现稳定
模型在不同超参设定下,针对不同NLP任务的表现:
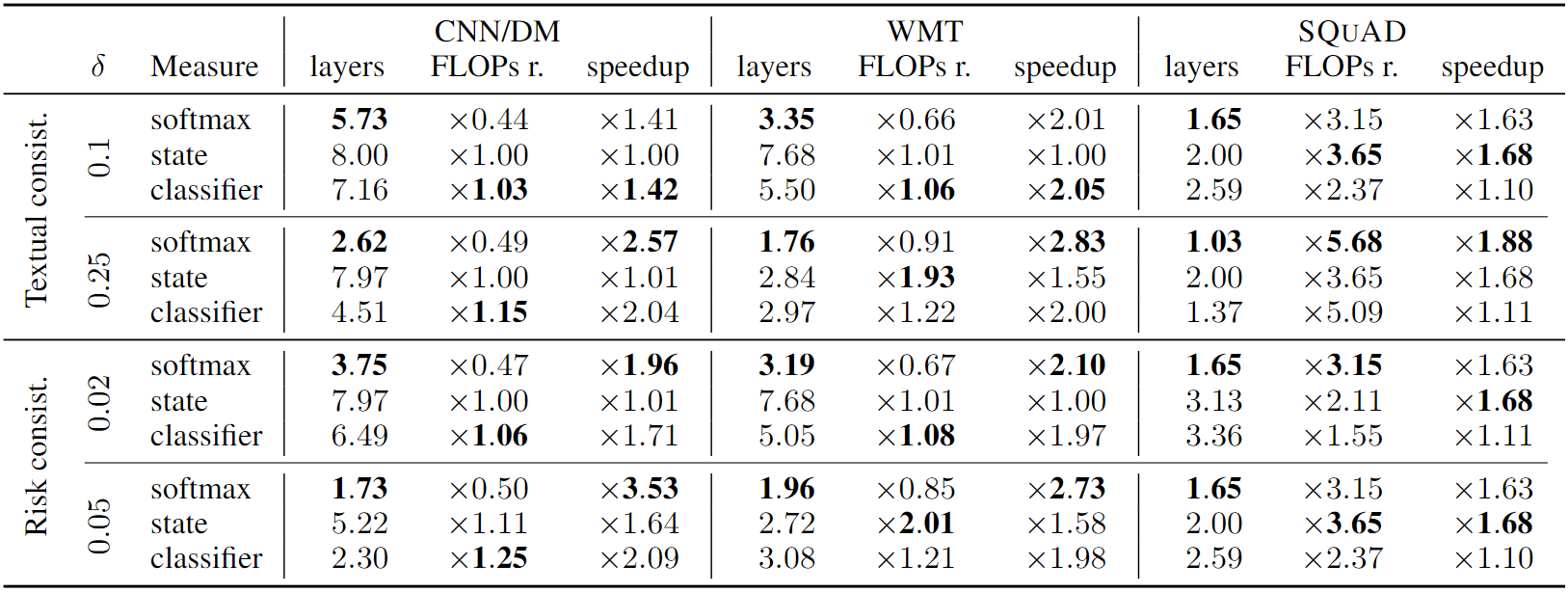
- 横向对比的是三种不同的NLP任务:文本摘要、机器翻译和问答
- 纵向对比的是不同容忍误差$\delta$取值和3种不同的置信度度量方法
- 综合来看,CALM框架在保持性能的同时取得到了较大的推理效率提升