1 DBSCAN算法概况
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,基于密度的、对噪声鲁棒的空间聚类方法)是一种基于密度的经典聚类算法
2 DBSCAN算法细节
- 遍历所有样本,寻找关键的核心点(邻域内样本数>=MinPoints)
- 核心点及其邻域内的样本(包括其他核心点)形成了临时聚类簇
- 当核心点A属于核心点B的临时聚类簇时,合并两处临时聚类簇
- 重复以上过程,直至找不到新的可合并临时聚类簇
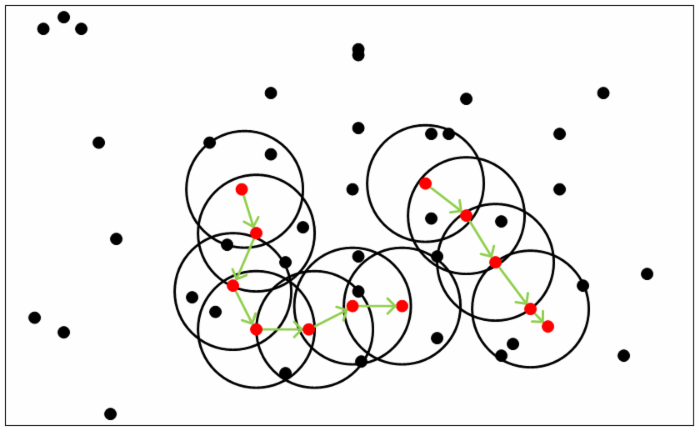
- 其中红点表示核心点;黑点表示普通样本(非核心点)
- 黑色圆圈表示核心点对应的邻域;绿色箭头表示簇的迭代聚合过程
3 算法分析
DBSCAN的优点:
- 可以对任意形状的稠密数据集进行聚类(K-Means等聚类算法一般只适用于凸数据集)
- 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
- 聚类结果没有偏倚,结果稳定(K-Means等聚类算法初始值对聚类结果有很大影响)
DBSCAN的缺点:
- 不适合样本集的密度不均匀、聚类间距差相差很大的情况
- 样本集较大时聚类收敛时间较长(可以在搜索最近邻时建立的树结构来改进)
- 调参相对复杂,不同参数(距离阈值+邻域样本数阈值)组合对聚类效果有较大影响
4 DBSCAN++
算法步骤:
- 从数据集中服从均匀分布采样$m$个样本构成数据子集$S$
- 针对数据子集$S$寻找核心点,并执行标准DBSCAN算法
- 最后将其余未标记(未采样)样本聚类到最近的核心点
算法分析:
- 仅考虑部分核心点,避免了数据量较大时的昂贵的密度估计查询成本
- 较少的核心点样本依然可以提供足够的数据集覆盖并产生合理的聚类
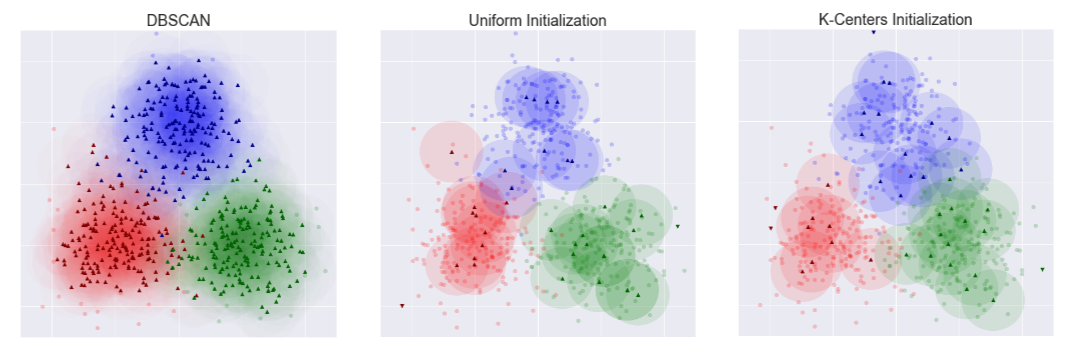
算法改进:K-Centers Initialization
- 不再随机采样$m$个样本构成数据子集
- 而是重复选取距当前集合中任何点最远的点
效果对比: