中文标题:基于角色标注的中国人名自动识别研究
英文标题:Classification-based Financial Markets Prediction using Deep Neural Networks
发布平台:计算机学报
发布日期:2004-01-01
引用量(非实时):87
DOI:缺失
作者:张华平, 刘群
文章类型:journalArticle
品读时间:2021-08-28 12:14
1 文章萃取
1.1 核心观点
从语料库中自动抽取的角色信息,采取 Viterbi 算法对切词结果进行角色标注,在角色序列的基础上,进行模式最大匹配,最终实现98%的召回率中国人名的识别。
1.2 综合评价
- 利用五分钟一次提取的高频数据,构建了9895个特征
- 利用高性能处理器进行RNN神经网络训练
- 最终结果得到了不错的夏普值,是比较常规的NER方法
1.3 主观评分:⭐⭐⭐
2 精读笔记
2.1 引言
人名识别的必要性
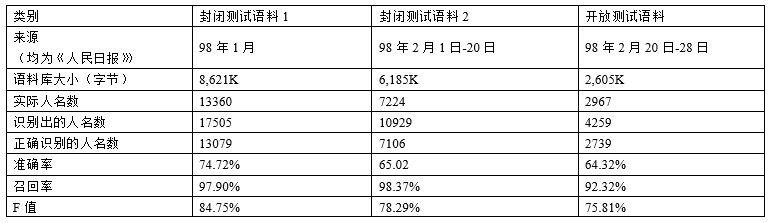
- 对人民日报1998年1月的语料库(共计2,305,896字)进行的统计
- 每100字中含未登录词1.192个(不计数词、时间词),其中48.6%的是中国人名
- 中国人名的召回率仅为68.77%,其切分错误高达50%以上
- 对所有分词错误进行统计,姓名错误占了将近90%
人名识别的困难点
- 人名构成复杂,比如"刘总 称 赵 已离开江西"
- 人名内部相互成词,如“朱朝阳”、“高峰”
- 人名与上下文成词,如“这里有 关羽 的遗迹”中的“有关”
- 同源冲突引起的歧义理解,如“王致和 同学爱吃臭豆腐”
2.2 中国人名自动识别
2.2.1 人名的构成:
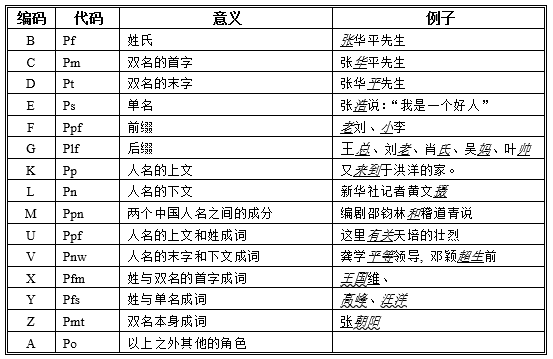
2.2.2 自动标注与人名识别
$W=(w_1,w_2,...,w_m)$:表示分词后的Token序列(即未登录词识别前的分词结果)
$T=(t_1,t_2,...,t_m)$:表示$W$的某个可能的角色标注序列
$T^\eta =argmax_TP(T|W)$ :表示最终标注结果,即概率最大的角色标注序列
根据$Bayes$公式可得$P(T|W)=\frac{P(T)P(W|T)}{P(W)}$,其中$P(W)$在数据足够的情况下为常数
因此$T^\eta =argmax_T P(T)P(W|T)$
引入隐马尔可夫模型 HMM 来计算 $P(T)P(W|T)$,其中 $W$ 表示观察值序列(一系列的字),而 $T$ 表示状态值序列(一系列的字的标注),而HMM的特性在于当前字的标注主要取决于上一个字的标注,所以最终的目标函数为:
$$T^\eta =argmax_T \Pi_{i=0}^m P(t_i|t_{i-1})P(w_i|t_i)=-argmin_T \Sigma_{i=0}^m {lnP(t_i|t_{i-1})+lnP(w_i|t_i)}$$ 这是一个最短路径问题,利用Viterbi算法就可以求解$T^\eta$
借助大规模已标注语料集(本论文使用给定是1998年版人民日报数据),可以统计得到$p(w_i|t_i)$和$p(t_i|t_{i-1})$,需要注意的是原始语料的标注是词性标注,需要转换为本文构建的标注。
除此之外,还要对$U$(人名的上文和姓成词)和$V$(人名的末字和下文成词)进行分裂处理,相应地分裂为KB、DL或者EL。这样最终的人名就可以通过以下结果集进行匹配: $$ { BBCD, BBE, BBZ, BCD, BEE,BE,BG,BXD,BZ,CD,EE,FB, Y,XD}$$
2.2.3 实验结果
相关资源
- 论文在线地址
- 本地文件地址:2004_基于角色标注的中国人名自动识别研究_张华平_刘群.pdf
- 本地Zotero地址:2004_基于角色标注的中国人名自动识别研究_张华平_刘群.pdf
