1 编译器和解释器
首先需要理解编译和解释的联系与区别
二者的联系:都是将高级语言翻译成机器语言执行的过程
过程上的区别:编译是将源程序翻译成可执行的目标代码,翻译与执行是分开的;而解释是对源程序的翻译与执行一次性完成,不生成可存储的目标代码。
结果上的区别:编译的话会把输入的源程序翻译生成为目标代码,并存下来(无论是存在内存中还是磁盘上),后续执行可以复用;解释的话则是把源程序中的指令逐条解释,不生成也不存下目标代码,后续执行没有多少可复用的信息。
Python是一种解释型语言(interpreted language),简单易懂,方便调试但是效率不足,不能充分利用重复调用的信息。因此在深度学习框架中,常采用符号式(symbolic)编程以突破Python解释器原有的性能瓶颈,同时也方便后续的移植部署。
符号式编程的一般过程为: 1. 定义计算流程(计算图) 2. 将流程编译成可执行程序 3. 给定输入,调用已编译的程序
为了兼容两种编程范式的优势,大部分深度学习框架都会考虑混合式编程模型,即在开发与调试时使用命令式编程范式,并在计算与部署时自动转化为符号式程序,以便改善程序的计算效率和可移植性
比如Torch借助torchscript特性实现混合式编程:
import torch
from torch import nn
from d2l import torch as d2l
# 生产网络的工厂模式
def get_net():
net = nn.Sequential(nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 2))
return net
x = torch.randn(size=(1, 512))
#@save
class Benchmark:
"""用于测量运行时间"""
def __init__(self, description='Done'):
self.description = description
def __enter__(self):
self.timer = d2l.Timer()
return self
def __exit__(self, *args):
print(f'{self.description}: {self.timer.stop():.4f} sec')
net = get_net()
with Benchmark('无torchscript'):
for i in range(1000): net(x)
# 无torchscript: 2.2015 sec
net = torch.jit.script(net)
with Benchmark('有torchscript'):
for i in range(1000): net(x)
# 有torchscript: 2.1262 sec
而TensorFlow借助autograph特性实现混合式编程:
import tensorflow as tf
from tensorflow.keras.layers import Dense
from d2l import tensorflow as d2l
# 生产网络的工厂模式
def get_net():
net = tf.keras.Sequential()
net.add(Dense(256, input_shape = (512,), activation = "relu"))
net.add(Dense(128, activation = "relu"))
net.add(Dense(2, activation = "linear"))
return net
x = tf.random.normal([1,512])
net = get_net()
with Benchmark('Eager模式'):
for i in range(1000): net(x)
# Eager模式: 1.2853 sec
net = tf.function(net)
with Benchmark('Graph模式'):
for i in range(1000): net(x)
# Graph模式: 0.4431 sec
2 异步计算
受限底层设计,Python对于并发和异步类的代码支持并不友好,因此主流深度学习框架都采用“前后端解耦”的方式实现异步操作:
- 前端的编程语言可以是多样的,主要作用是传递操作
- 不同深度学习框架借助更支持异步的语言实现后端,从而执行操作
- 前端线程不需要执行实际的计算,也就绕过了可能的性能瓶颈
在异步计算中,往往还需要阻塞操作来强制Python等待完成计算,诸如输出/转换等操作也可以作为隐式的阻塞器,但可能影响原本高效代码的性能
3 自动并行
当深度学习框架在后端构建好计算图后,系统就了解了所有依赖关系,从而并行地执行多个互不依赖的任务,以提高程序运行效率。并行化计算主要应用于多GPU场景,偶尔会应用于多CPU场景
这种并行化一般是自动进行的,但不适用于任务间耦合性很强(比如需要频繁针对某些信息进行全局同步)的情况,当并行数较多时,计算效率主要受到数据交换IO的制约
4 硬件
计算机关键组件:
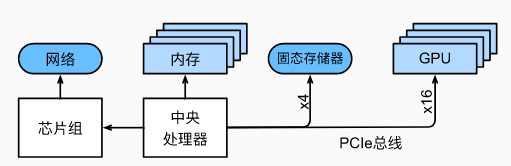
数据从内存到计算的路径:主内存 -- L3 -- L2 -- L1 -- 寄存器计算
伴随着路径的深入,访问延迟成倍降低,空间也成倍降低
- L1访问延迟:0.5ns
- L2访问延迟:7ns
- 主内存访问延迟:100ns
注意:高端CPU适合并行计算,但是超线程因为共享寄存器所以提升不明显
GPU VS CPU
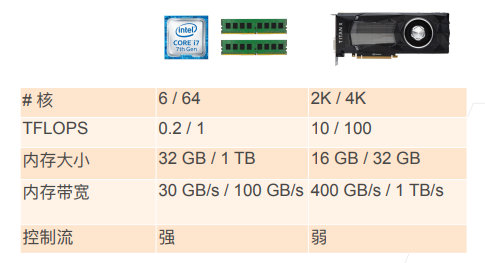 GPU特性:核数多,带宽大,图像处理能力强,通用计算能力弱
GPU特性:核数多,带宽大,图像处理能力强,通用计算能力弱
计算优化技巧汇总:
- 提升时间上的本地性:复用的数据保持在缓存里
- 提升空间上的本地性:按序读写数据时可以预读取
- 当矩阵按行存储时,访问行比访问列更快(行内的数据内存地址是连续的)
- CPU和GPU之间的传递带宽小,数据传输要争取量大次少
- 模型与硬件相匹配:例如,一些Intel Xeon CPU特别适用于INT8操作,NVIDIA Volta GPU擅长FP16矩阵操作,NVIDIA Turing擅长FP16、INT8和INT4操作。
5 多GPU并行
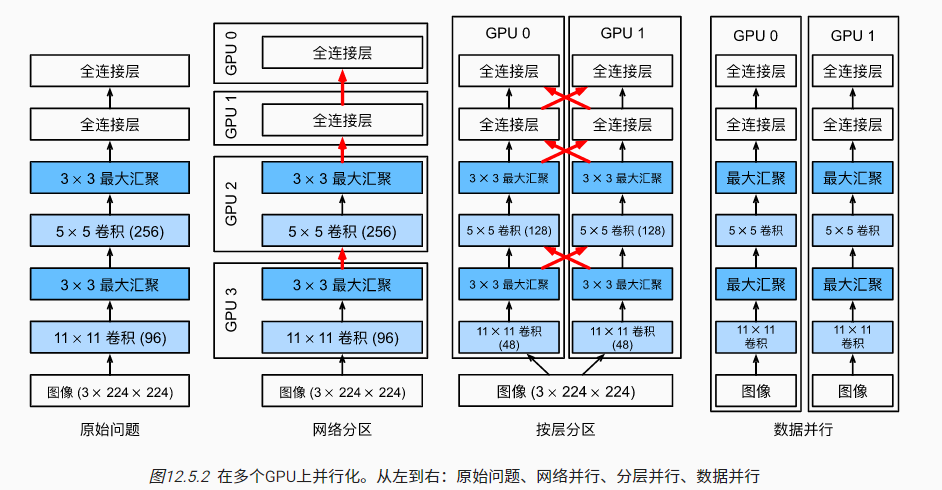
数据并行:将样本分开分配到多个节点,每个节点包含完整的模型参数。最终汇总方式也有两种,一种是传递并汇总所有梯度信息,最后进行统一的参数更新;另一种是传递并汇总更新后的参数,取参数均值并在节点间同步。
模型并行:根据网络结构,将模型的不同层(inter-layer)或同一层的不同参数(intranet-layer)进行拆分,分配到不同的节点并分别进行训练,节点间保持通信。
- 数据并行简单易用,在工业界更常见
- 模型并行拆分和通信麻烦,比如TF框架就需要拆分最小依赖子图,并在子图间借助通信算子实现模型的并行训练。但模型并行能处理单节点无法容纳的大参数规模模型
- 通道并行是一种结合数据并行和模型并行的并行策略
扩展阅读:聊一聊深度学习分布式训练
5.1 数据并行的代码实现
以PyTorch为例:
%matplotlib inline
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 初始化模型参数
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
# 定义模型
def lenet(X, params):
h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])
h1_activation = F.relu(h1_conv)
h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))
h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])
h2_activation = F.relu(h2_conv)
h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))
h2 = h2.reshape(h2.shape[0], -1)
h3_linear = torch.mm(h2, params[4]) + params[5]
h3 = F.relu(h3_linear)
y_hat = torch.mm(h3, params[6]) + params[7]
return y_hat
# 交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# 辅助函数:分配附加梯度的参数到特定设备中
def get_params(params, device):
new_params = [p.to(device) for p in params]
for p in new_params:
p.requires_grad_()
return new_params
# 辅助函数:在GPU0上聚合其他所有设备中的参数值
# 补充说明:聚合过程可以在CPU上进行,也可以每个GPU负责一份特定参数组的聚合
def allreduce(data):
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device)
for i in range(1, len(data)):
data[i][:] = data[0].to(data[i].device)
#@save 特殊记号,将定义的函数、类或语句保存到d2l中,方便反复调用
def split_batch(X, y, devices):
"""将X和y拆分到多个设备上"""
assert X.shape[0] == y.shape[0]
return (nn.parallel.scatter(X, devices),
nn.parallel.scatter(y, devices))
def train_batch(X, y, device_params, devices, lr):
X_shards, y_shards = split_batch(X, y, devices)
# 在每个GPU上分别计算损失
ls = [loss(lenet(X_shard, device_W), y_shard).sum()
for X_shard, y_shard, device_W in zip(
X_shards, y_shards, device_params)]
for l in ls: # 反向传播在每个GPU上分别执行
l.backward()
# 将每个GPU的所有梯度相加,并将其广播到所有GPU
with torch.no_grad():
for i in range(len(device_params[0])):
allreduce(
[device_params[c][i].grad for c in range(len(devices))])
# 在每个GPU上分别更新模型参数
for param in device_params:
d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 将模型参数复制到num_gpus个GPU
device_params = [get_params(params, d) for d in devices]
num_epochs = 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
timer = d2l.Timer()
for epoch in range(num_epochs):
timer.start()
for X, y in train_iter:
# 为单个小批量执行多GPU训练
train_batch(X, y, device_params, devices, lr)
torch.cuda.synchronize()
timer.stop()
# 在GPU0上评估模型
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(
lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))
print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'
f'在{str(devices)}')
# 单GPU训练
train(num_gpus=1, batch_size=256, lr=0.2)
# 多GPU训练
train(num_gpus=2, batch_size=256, lr=0.2)
5.2 GPU并行的简洁实现
以PyTorch为例:
import torch
from torch import nn
from d2l import torch as d2l
#@save
def resnet18(num_classes, in_channels=1):
"""稍加修改的ResNet-18模型"""
def resnet_block(in_channels, out_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(d2l.Residual(in_channels, out_channels,
use_1x1conv=True, strides=2))
else:
blk.append(d2l.Residual(out_channels, out_channels))
return nn.Sequential(*blk)
# 该模型使用了更小的卷积核、步长和填充,而且删除了最大汇聚层
net = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU())
net.add_module("resnet_block1", resnet_block(
64, 64, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1,1)))
net.add_module("fc", nn.Sequential(nn.Flatten(),
nn.Linear(512, num_classes)))
return net
net = resnet18(10)
# 获取GPU列表
devices = d2l.try_all_gpus() # 此函数定义在6.1节
# 我们将在训练代码实现中初始化网络
def train(net, num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 在多个GPU上设置模型
net = nn.DataParallel(net, device_ids=devices)
trainer = torch.optim.SGD(net.parameters(), lr)
loss = nn.CrossEntropyLoss()
timer, num_epochs = d2l.Timer(), 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
for epoch in range(num_epochs):
net.train()
timer.start()
for X, y in train_iter:
trainer.zero_grad()
X, y = X.to(devices[0]), y.to(devices[0])
l = loss(net(X), y)
l.backward()
trainer.step()
timer.stop()
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))
print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'
f'在{str(devices)}')
# 单GPU训练
train(net, num_gpus=1, batch_size=256, lr=0.1)
# 多GPU训练
train(net, num_gpus=2, batch_size=512, lr=0.2)
技巧:增加GPU时,batch_size最好同步增加,也可以稍微提高学习速率
6 参数服务器
参数服务器(parameter server)是一个为了解决分布式机器学习问题的编程框架
一般包括服务器端(接收梯度,保存并更新参数)、客户端(接收梯度和最新参数,计算并发送梯度)、调度器(节点管理,数据同步)
一个好的参数服务器需要考虑:低通信延迟、一致性、可拓展性、高容错、易用性
层次的参数服务器与网络通讯:
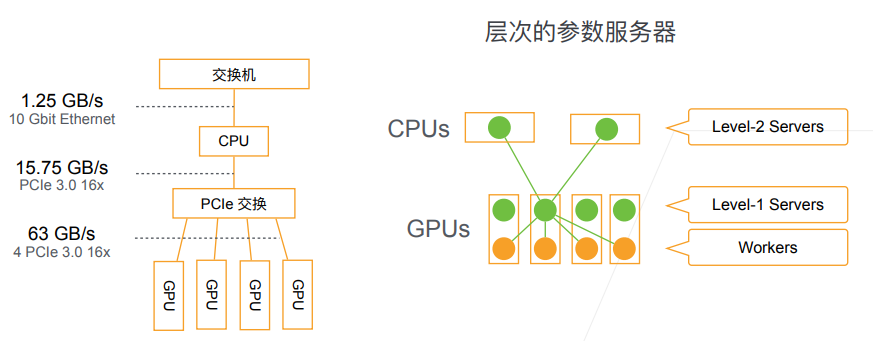
- 分布式训练的性能瓶颈往往在网络通讯
- 尽量提高GPU间与节点间的带宽,减少不同层次间的数据交换
- 计算(FLOP)通讯(model size)比越高越好:Incception>ResNet>AlexNet
- 其他优化方向:异步更新、硬件定制、高效同步协议
知识拓展:
- 英伟达提出的NVLink借助硬件的定制化实现了更强大的通信能力
- Leyuan Wang等人在2018年提出了双环同步协议,对NVLink实现进一步优化
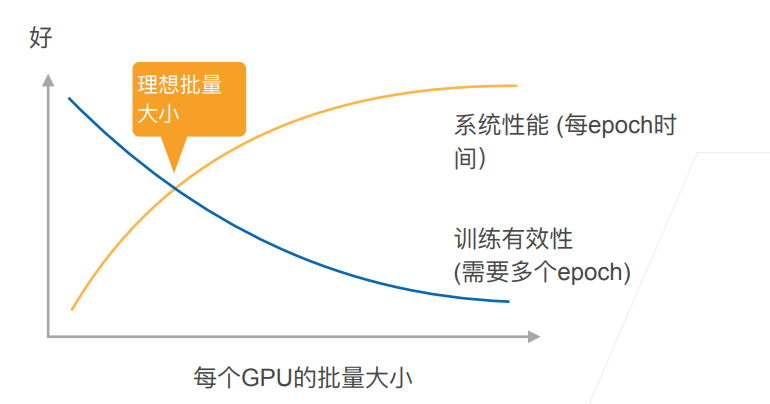
使用合适的批量大小找到最高的训练性价比:
7 补充:其他硬件
DSP:数字信号处理
- 低功耗、高性能,擅长处理卷积运算
- 编程和调试困难,编译器质量良莠不齐
FPGA:可编程阵列
- 通过配置逻辑单元和连接方式,实现更强的硬件定制化
- 通常比通用硬件更高效,但是工具链质量不一,且编译麻烦
AI专用芯片:AI ASIC
- 各大厂都在研发,其中典型为Google的TPU
- 研发成本高,后续的硬件成本低,效率高
Systolic Array:谷歌Ai芯片的核心设计
- 针对矩阵运算进行计算加速和功耗优化
- 设计简单明晰,适合模块化,成本可控
- 通过平衡计算和IO优化在高并发场景下的表现
Google强推的Transform结构特别适合TPU,大矩阵点积+大内存
总结:CPU -- GPU -- DSP --FPGA -- ASIC (易用性变低、性能变高、功耗变低)
