论文数据获取
arXiv 预印本论文资源
- arXiv 是一个免费、开放获取的预印本仓储网站,主要收录物理学、数学、计算机科学、生物学、定量金融学、统计学等学科的学术论文预印本
- 科学家和研究人员可以在正式发表论文之前,先在 arXiv 上分享研究成果;arXiv上的论文对所有人免费开放,任何人都可以访问和下载
- arXiv 也提供了基本的查询和下载 API,其 Python 代码示例如下:
import urllib, urllib.request
url = 'http://export.arxiv.org/api/query?search_query=all:electron&start=0&max_results=1'
data = urllib.request.urlopen(url)
print(data.read().decode('utf-8'))
PubMed 生物医学文献资源
- PubMed 数据包含海量生物医学文献的引文和摘要
- PubMed 数据支持通过 FTP 服务或 E-utilities API 获取
- PubMed 数据会按年份归档,同时也会有每日文献的更新
- 相关资源:PubMed 文献下载、PubMed 期刊列表
2025-08-29 update,Cool Paper 作为一个论文总结工具,也有 RSS 功能
论文数据解析
<code>paperetl</code> 是一个用于处理医学和科学论文的 ETL 库
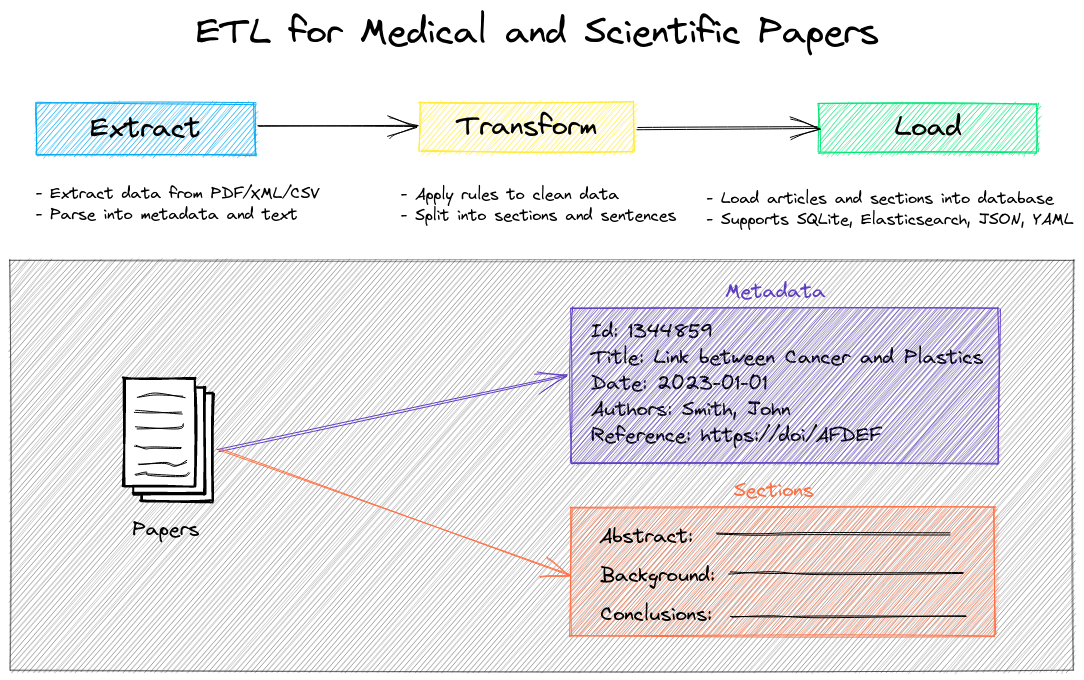
paperetl能够对论文进行信息的抽取、转换与存储paperetl支持 arXiv 和PubMed 的 XML 格式文件,也支持完整 PDF 文件、符合文本编码倡议(TEI)的 XML 文件和记录文章元信息的 CSV 文件paperetl支持的存储形式:SQLite、JSON、YAML 和 ES
Python 示例:
# jupyter notebook 环境准备
# pip install paperetl==2.5.1
# !python -c "import nltk; nltk.download('punkt')"
# 下载数据
!wget -N -P pubmed/ https://ftp.ncbi.nlm.nih.gov/pubmed/updatefiles/pubmed25n1535.xml.gz
# 数据处理
!python -m paperetl.file pubmed pubmed_clean
import sqlite3
import pandas as pd
from IPython.display import display, HTML
def execute(sql):
db = sqlite3.connect("pubmed_clean/articles.sqlite")
cursor = db.cursor()
cursor.execute(sql)
df = pd.DataFrame([list(x) for x in cursor], columns=[c[0] for c in cursor.description])
display(HTML(df.to_html(index=False)))
# Show articles
execute("SELECT * FROM articles LIMIT 5")
# Show sections
execute("SELECT * FROM sections LIMIT 5")
论文数据分析
<code>paperai</code> 是一个用于处理医学和科学论文的 AI 应用程序

paperai通过 AI 驱动的报告生成,为研究任务提供强力支持(支持 RAG)paperai能根据配置文件,以高效的方式执行批量 LLM 推理操作paperai可以生成 Markdown、CSV 格式的报告,并可直接在 PDF 上标注答案
配置文件模板:
%%writefile report.yml
name: Report
Hypertension:
query: COVID-19 and hypertension
columns:
- name: Date
- name: Study
- {name: Sample Size, query: number of people/patients, query: how many people/patients, type=int}
- {name: Comorbidities, query: covid-19 and hypertension, question: what diseases}
Python 示例:
# jupyter notebook 环境准备
# pip install paperai==2.5.0
# !python -c "import nltk; nltk.download(['punkt', 'punkt_tab', 'averaged_perceptron_tagger_eng'])"
# 索引数据
!python -m paperai.index pubmed_clean/
# 查询数据,只显示Top2,最低匹配度为0.75
!python -m paperai.query "COVID-19 and hypertension" 2 paperai 0.75
# 根据配置文件的 RAG pipeline 调用大模型,完成简单的QA任务
python -m paperai.report report.yml 5 csv paperai
import pandas as pd
from IPython.display import display, HTML
# 展示结果
display(HTML(pd.read_csv("Hypertension.csv").to_html(index=False)))
根据配置文件的 RAG pipeline 不同,
paperai可以作为论文助手完成各种任务