前置知识:模型参数的数据类型
工具推荐:常见模型的显存占用计算器
模型占用
大模型的显存占用主要取决于以下几点:
- 参数量:以常见的大模型 Llama2为例,其常见的参数量包括7B、13B、70B;其中B表示十亿(billion)的参数级别,7B也就代表70亿个参数
- 参数精度:常见的浮点精度包括float32(占用4字节,32bit)、float16(16bit)、int8(8bit)、int4(4bit)等,占用空间依次递减,但模型的预测效果也会下滑
以Llama2-7B模型为例,在精度为float32的情况下,模型占用显存为: $$7\times 10^9\times 4 bit=28\times 10^9/1024 KB=28\times 10^9/1024^3 \ GB\approx26.077GB$$ 以此类推,精度为float16、int8和int4的情况下,模型占用显存约为13G、6.5G、3.26G
推理占用
此外,模型推理时还需要存储一些中间过程文件,因此实际显存占用会比计算值高一些;一般经验认为,此额外开销 <= 20%,即实际推理显存占用 ≈ 1.2 倍的模型显存占用
不同尺度模型推理时的所需显存:
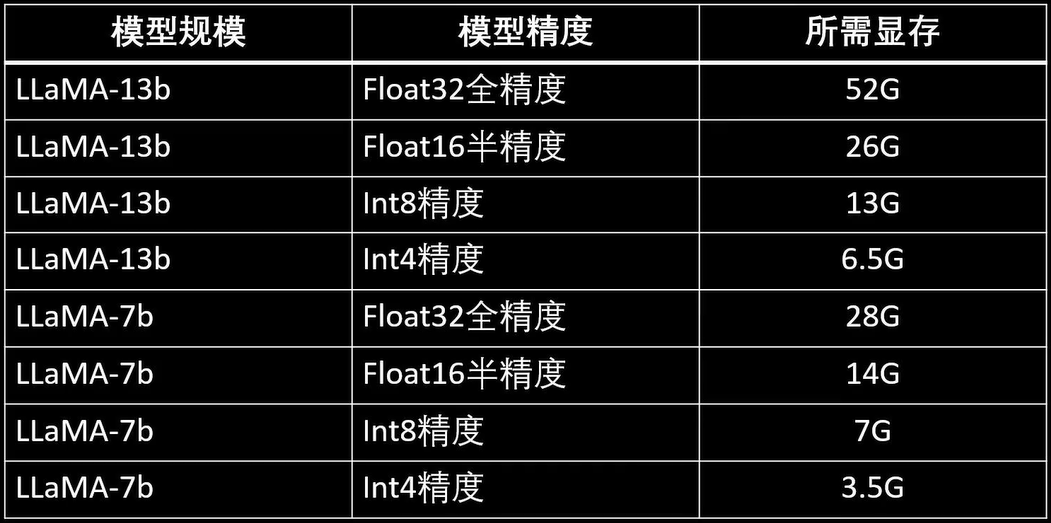
训练占用
相对于模型部署和推理时的内存占用,模型全量微调时则会大得多。一般的经验推论,认为模型全量微调/训练所需的显存会是模型推理时的十几倍;另一种说法,则认为训练时的显存占用约是参数量的 20x 或 16x(比如训练一个 7B 参数量的模型,就需要至少 140G 的显存)
模型训练时的显存占用影响因素:参数量、梯度、优化器参数、样本长度、BatchSize
为什么训练时的显存占用约是参数量的16x ?
- 假设模型的参数量为 $\theta$,使用 Adam 优化器进行混合精度训练(AMP)
- 混合精度训练中模型权重、梯度精度为 float16,优化器参数精度为 float32
- 因此训练时,模型权重和梯度的显存消耗合计为 $2\theta+2\theta=4\theta$
- 优化器需要保存一份模型权重(float32),并为每个权重参数维护两个状态变量(float32);因此优化器的显存消耗合计为 $3\theta+3\theta+3\theta=12\theta$
- 综上所述,在不考虑激活值 activation 的情况下,训练的显存占用约为 $16\theta$
其他显存占用分析:
- activations 的显存占用,一个 1.5B 的模型,序列长度为1K,batch size 为32,则激活值消耗显存为60GB;activation recomputation 能通过重计算显著降低显存占用(60GB->8GB)
- 临时缓存区,可用于存储中间结果;1.5B 的模型的临时缓存区(float32)需要 6GB 的显存
- 显存碎片;极端情况下,大模型的训练可能会导致30%的显存碎片
OpenAI 的 Andrej Karpathy 讲解 ChatGPT 的预训练需要 10TB 数据、6000 块 GPU、12 天
LLaMA 在训练 7B 模型时,需要 83 块 A100(80GB 显存),耗时 1000 小时(42 天)
微调占用
常见微调方式的显存占用(摘自 LLaMA-Factory):
| Method | Bits | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| Freeze | 16 | 20GB | 40GB | 80GB | 200GB | 360GB | 160GB | 400GB |
| LoRA/GaLore/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
- 对于输入上下文较长的模型来说,激活值 activation 的微调显存占用也是较大的