中文标题:电路追踪:揭示语言模型中的计算图
英文标题:Circuit Tracing: Revealing Computational Graphs in Language Models
发布平台:在线平台
发布日期:2025-03-27
引用量(非实时):无
作者:Anthropic 团队
关键字: #CircuitTracing #电路追踪 #可解释性
文章类型:webpage
品读时间:2025-08-21 17:26
1 文章萃取
1.1 核心观点
电路追踪(Circuit Tracing)通过引入稀疏编码技术,形成具备单一语义的稀疏特征,之后尝试利用跨层转码器 (CLT)重建和恢复模型;在转码器和稀疏编码的基础上,本文定义了归因图来描述模型推理过程中关键节点及节点间虚拟权重关系,同时将经过图剪枝处理后的归因图的进行可交互的可视化展示,借此实现模型内部逻辑的可解释,同时评估特定提示词对模型思维过程的影响
本文通过大量的示例来对大模型的内部思考逻辑进行定性探究,挖掘出很多不同于人类的模型思考模式;这种可解释性技术也能缓解了大模型的潜在问题,对未来大模型的改进起到很多作用;最后本文也经过严格而缜密的实验分析,总结了本文技术的合理性与局限性
1.2 综合评价
- 借助归因图实现对大语言模型内部思考逻辑的可视化
- 在大模型的可解释性方面具备开创性,实证案例丰富
- 相关的归因图技术和可交互的可视化方法,均已开源
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 算法细节
2.1.1 跨层转码器 CLT
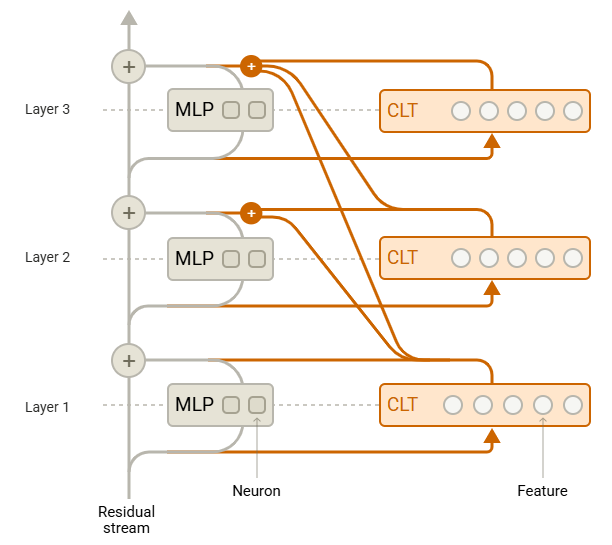 跨层转码器(cross-layer transcoder,CLT)被切分在原始神经网络的 $L$ 层中,利用稀疏激活特征编码来替换原始模型每一层中的 MLP 输出 $y^{\ell}$;具体来说:
跨层转码器(cross-layer transcoder,CLT)被切分在原始神经网络的 $L$ 层中,利用稀疏激活特征编码来替换原始模型每一层中的 MLP 输出 $y^{\ell}$;具体来说:
- 针对第 $l$ 层的 MLP 输入 $x^{l}$,CLT 会先构建编码器来生成稀疏特征编码 $a^{l}=JumpReLU(W^{l}_{enc}x^{l})$
- 然后 CLT 通过解码器来尝试还原 $\hat{y}^{\ell}=\Sigma_{\ell}W^{\ell}_{dec}a^{\ell}$,目前是让 $\hat{y}^{\ell}$ 尽可能接近原来的 MLP 输出 $y^{\ell}$
- CLT 的所有参数是联合训练的,其损失包括重建误差损失 $L_{MSE}$ 和稀疏惩罚项 $L_{sparsity}$:
$$ \begin{aligned} & L_{\mathrm{MSE}}=\sum_{\ell=1}^{L}|\hat{\mathbf{y}}^{\ell}-\mathbf{y}^{\ell}|^{2} \\ & L_{\mathrm{sparsity}}=\lambda\sum_{\ell=1}^{L}\sum_{i=1}^{N}\mathrm{tanh}(c\cdot|\mathbf{W_{dec,i}^{\ell}}|\cdot a_{i}^{\ell}) \end{aligned} $$
- 其中 $L$ 表示最大层数,$N$ 表示对应层的稀疏特征数,$\lambda$ 和 $c$ 是超参数
JumpReLU分段激活函数:当输入低于某个阈值时输出零,否则输出等于输入
2.1.2 局部替代模型
替代模型(Replacement Model):
- 给定一个训练好的 CLT,依次替换原始模型中的 MLP 神经元,即可构建出替代模型
- 替代模型的正向传递与输出,和原始模型是相对一致的;对于一个 18 层的 CLT 替代模型在词预测(next-token completion)任务中,能够与原始模型的输出有 50%的一致概率
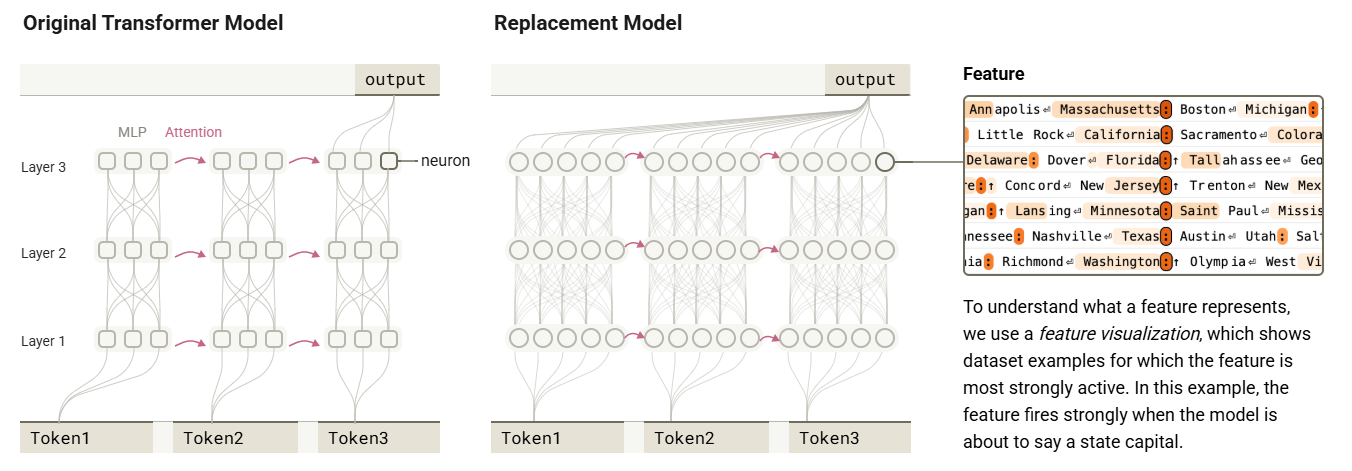
- 在上图中,当替代模型即将表达“某个州的首府时”时,相关的稀疏特征会激活(高亮部分)
局部替代模型(Local Replacement Model):
- 其目标是缩小替代模型与原始模型之间的差异,辅助分析特定提示 $p$ 对原始模型的影响
- 局部替代模型仍然使用 CLT 替换原始模型的 MLP,但有以下改动:(1)冻结原始模型的注意力权重和归一化层分母(2)添加偏差项 $error=y^{\ell}-\hat{y}^{\ell}$ 来修正 $\ell$ 层进行 CLT 替换所引入的误差
- 以上操作,确保最终的局部替代模型内部的所有激活值和最终输出与原始模型保持严格一致
局部替代模型的局部线性关系:由于注意力权重和归一化层分母都是冻结的,因此源特征的激活对下游特征的预激活值(Pre-activation,即输入非线性函数之前的值)的影响是线性的 而这种稀疏特征间的局部线性影响,也被称为虚拟权重,是构建归因图(Attribution Graphs)的基础
2.1.3 归因图的构建
归因图的节点(Nodes)
- 输入节点(Input):提示文本 P 中的每个 Token 的 Embedding 向量
- 中间节点(Intermediate):处理提示文本 P 中的每个 Token 时被激活的CLT 特征
- 误差节点(Error):原始模型中每个 MLP 输出中没有被 CLT 解释的部分
- 输出节点(Output):模型预测下一个 Token ,只考虑 Top10 且概率>95%的情况
归因图的边(Edges)
- 边的源节点包括输入节点、中间节点、误差节点,目标节点包括中间节点、输出节点
- 给定一个源节点 $s$ 和目标节点 $t$,边权重定义为 $A_{s\to t}:=a_{s}w_{s \to t}$ ;其中 $a_{s}$ 表示源节点的激活值,$w_{s \to t}$ 表示局部替代模型中的虚拟权重,即目标节点 $t$ 的预激活值相对于 $a_{s}$ 的导数
- 在计算虚拟权重的过程中,局部替代模型的所有非线性项都处于梯度停止(stop-gradients)状态;因此在反向传播过程中,模型的非线性组件可表示为雅可比行列式 $J_{c_s,\ell\to c_t,\ell_t}$,以方便高效计算:
$$ A_{s\to t}=a_sw_{s\to t}=a_s\sum_{\ell_s\leq\ell<\ell_t}(W_{\mathrm{dec},s}^{\ell_s\to\ell})^TJ_{c_s,\ell\to c_t,\ell_t} W_{\mathrm{enc},t}^{\ell_t} $$
上式主要展示了源节点和目标节点为中间节点的情况,其他类型的边公式是相似的
由归因图的定义可知,任意特征节点 $t$ 的预激活值都可以简单表示为图中所有输入边的汇总: $$ h_{t}=\Sigma_{S_{t}}w_{s\to t} $$
- 其中 $w_{s}$ 表示节点 $t$ 的所有上游节点集合,其中上游节点需要满足两个限制条件(1)层级限制:节点所在层 ≤ $t$ 所在的层(2)时序限制:节点上下文位置 ≤ $t$ 的位置
- 归因图中的边,可以将每个节点的激活值进行线性分解,便于捕捉模型思考的路径
上游节点的限制条件理解:(1)层级限制,确保信息在网络层级间的单向传递(2)时序限制,防止未来信息的泄露,其作用类似于自回归模型中的因果掩码
2.1.4 归因图的可视化
归因图的规模问题:即使对于较短的提示文本,最终构建出的归因图中边的数量也可能达到百万级别;并且随着稀疏特征向量维度和提示文本长度的增加,归因图的量级会迅速膨胀
归因图的剪枝策略(先修剪节点,再修剪边):
- 对边权重进行无符号化处理(取绝对值),然后构建邻接矩阵,并遍历每个节点的输入边进行归一化处理,使其输入边的权重和为 1;定义归一化后的无符号邻接矩阵为$A$
- 定义间接影响矩阵(ndirect influence matrix)$B=A+A^2+A^3+\dots=(I-A)^{-1}-I$,其第 $i$ 行第 $j$ 列的元素值表示节点对 $<i,j>$ 间路径的累积重要性(类似 PageRank 的思想)
- 遍历矩阵 $B$ 中输出节点对应的行,根据模型对不同 token 的输出概率作为权重,进行加权平均计算,得到所有非输出节点的预测影响得分(衡量非输出节点对最终输出的贡献)
- 按照预测影响得分对非输出节点进行降序排列并截断,使得保留后非输出节点的累积预测影响得分在所有节点的预测影响得分汇总的占比达到 80%(相当于保留了 80%的预测可解释性)
- 针对节点剪枝后的归因图,采取相同的方式重新计算每个节点的预测影响得分,然后根据归一化后的边权重,计算每个边的预测影响得分,之后采取相同策略进行边的裁剪(阈值提升为 98%)
剪枝策略的补充说明
- 输入节点(embedding)和误差节点,不参与节点的剪枝操作
- 剪枝策略中的阈值(80%和 98%)为实验参数,可根据实际情况灵活调整
- 当提示文本过长时,可考虑采用自适应算法来搜索 TopN 个重要节点构建图
剪枝后的归因图,节点的数量通常减少约 10 倍,边的数量通常减少约 500 倍
归因图的可视化
- 归因图经过剪枝后,通常包含数百个节点和数万条边(信息量依然很大)
- 本文开发了一个交互式归因图可视化界面,旨在实现“追踪”图中的关键路径,保留重新访问先前探索的节点和路径的能力,并且能根据需要呈现解读特征所需的信息
2.2 归因图应用
2.2.1 归因图的典型案例
典型案例 - 理解大模型构建缩写词的能力:
- 说明:给定任意标题,大模型构建并返回其缩写词
- 输入示例:
The National Digital Analytics Group (N - 期望输出(后续文本的补全):
DAG)
由于 tokenizer 包含用于大写锁定的特殊 token,因此实际输出为特殊 token+缩写词(小写);下文中的归因图示意进行了适当简化,不影响对模型思维过程的解释
案例的归因图可视化:
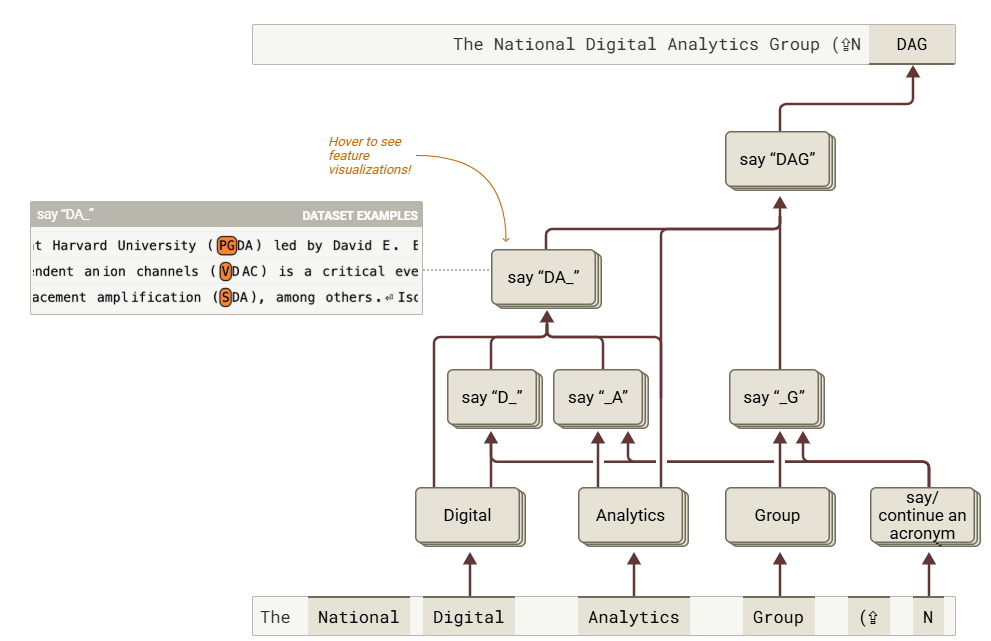
- 方框表示一组被激活的相似特征,鼠标悬停可进行每个特征的可视化展示
- 剪头表示特征组或 token 对其他特征或输出节点存在直接影响
- 归因图中展示了三个关键路径,分别对应缩写词
DAG的三个缩写字母 - 单词
National对应的缩写字母N已经输出,因此字母N会对三个路径都产生影响,从而保证后续的输出DAG能够完全接上前文,并实现National Digital Analytics Group的缩写补齐
2.2.2 归因图的基础操作
归因图的详细展开:
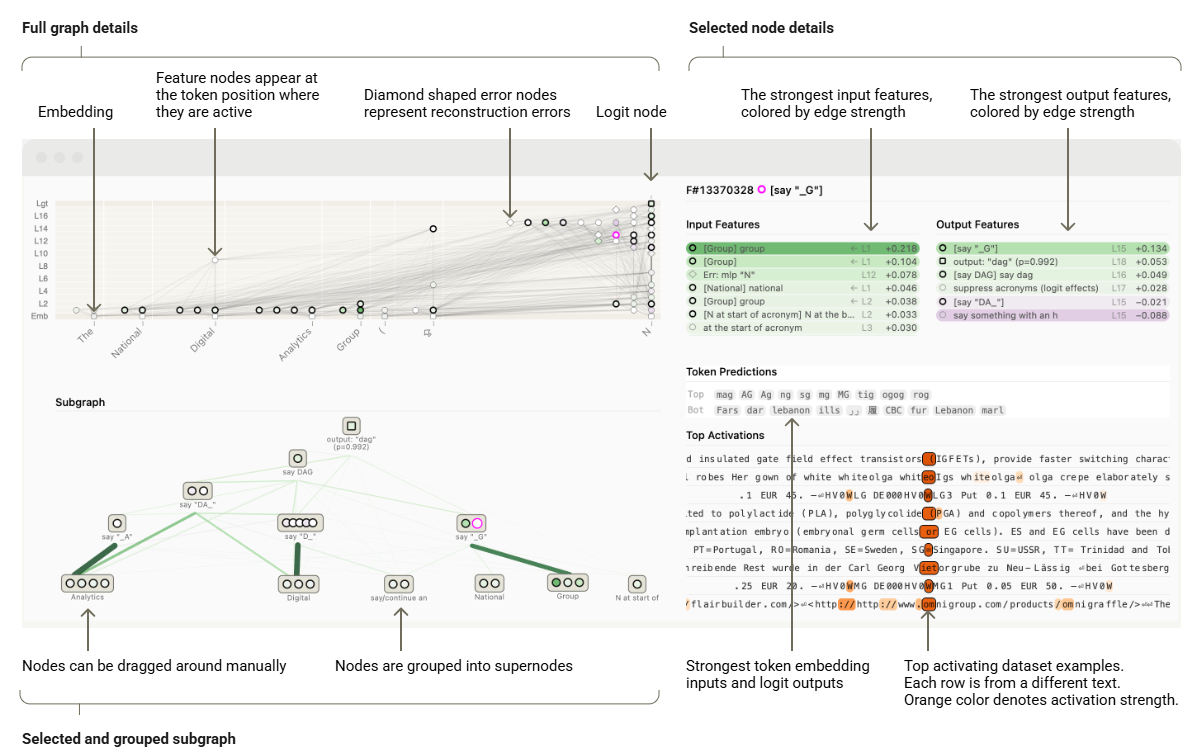
- 左上:完整的归因图,包含不同类型的节点与边,颜色深浅表示预测影响得分
- 左下:局部的归因图,节点可支持鼠标拖拽,点击节点可展开查看节点的特征详情
- 右上:根据边的预测影响得分,展示对每个节点影响最大的 N 个输入节点/输出节点
- 右下:每个节点的详情,既包括节点对最终 token 的影响,也包含关键的历史示例
归因图的基础操作:
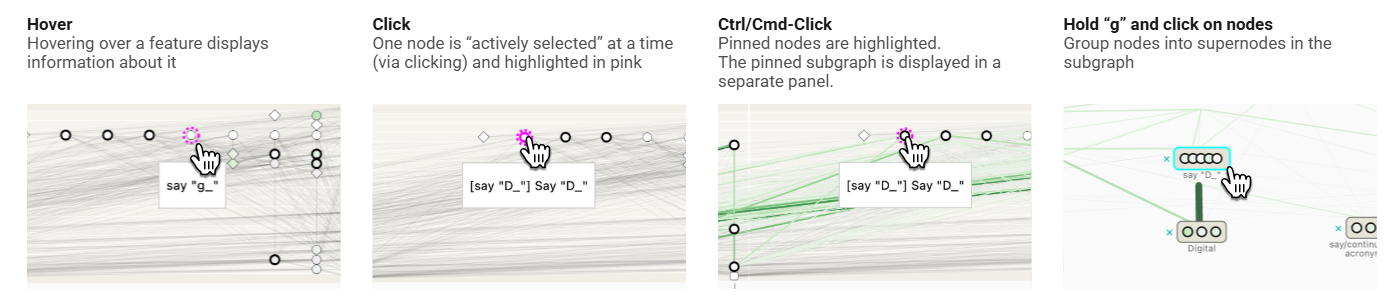
- 鼠标悬停(Hover):将鼠标悬停在一个节点上,会展示该节点的详细信息
- 鼠标点击(Click):主动选择一个节点,选中的节点会高亮显示为粉色
- Ctrl/Cmd+鼠标点击:主动固定节点,多个固定后节点可以构建一个独立显示的子图
- 按住“g”键并点击节点:将子图中的多个节点重新分组为一个超节点(手动聚类)
2.2.3 归因图的干扰与验证
归因图的验证方法:通过在底层模型中执行特征扰动(修改激活值或解码器),并检查对下游特征或模型输出的影响是否与基于图的预测相匹配,来验证归因图的断言
归因图的干预与验证示例:
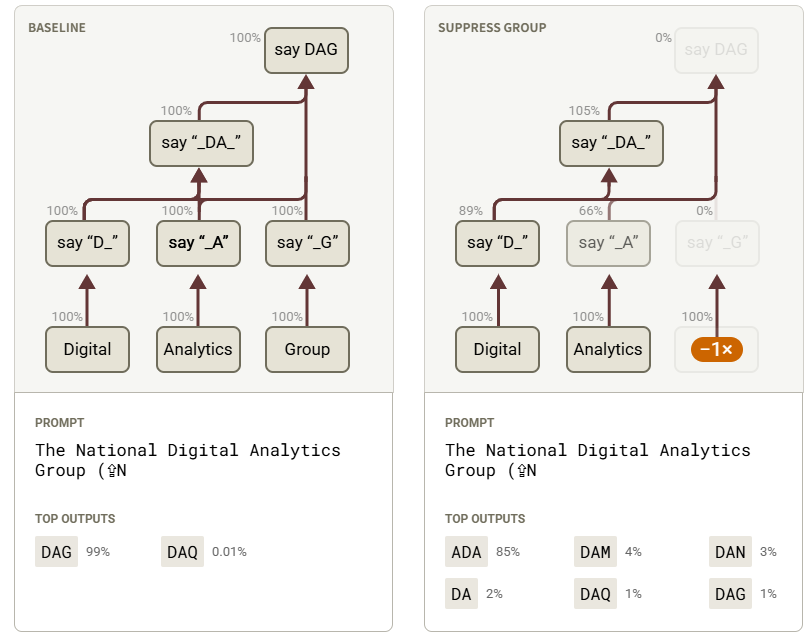
- 上图中,左侧表示干预前的归因图示意,右侧表示干预后的归因图示意
- 干预方式:抑制归因图中“Group”这一超节点对其他节点以及输出的影响
- 干预结果:预测输出的 Token 概率分布发生较大变化,并符合归因图的推断
超节点的抑制主要通过乘以一个
-1的因子来产生负向引导,而不是直接删除
2.2.4 用归因图定位重要层
通过归因图还可以定位一个特征的解码,评估哪些层能对输出产生更大的影响
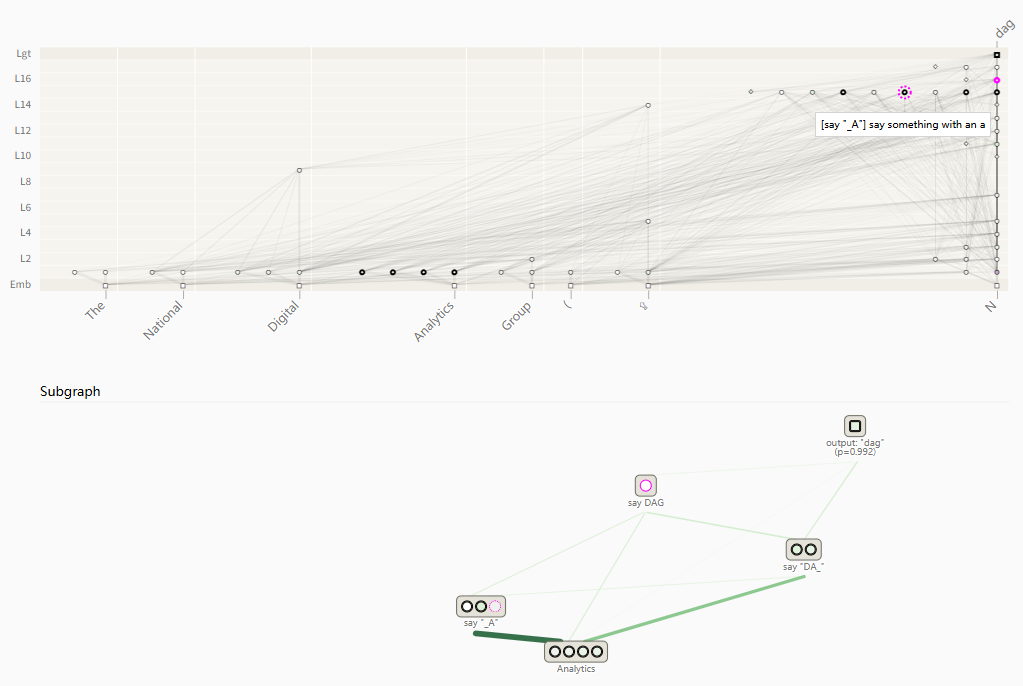
- “Analytics”超节点,主要通过第 13 层及更高层的中间特征组“say_A”、“say_DA_”和“say_DAG”这三个节点来间接地对输出节点“dag”做出贡献
- 在不同层对“Analytics”超节点的特征进行抑制(负向引导),可发现当抑制发生在第 1~12 层时,输出节点会受到较大的影响(“Analytics”超节点对 13 层及以上不再具备直接影响):
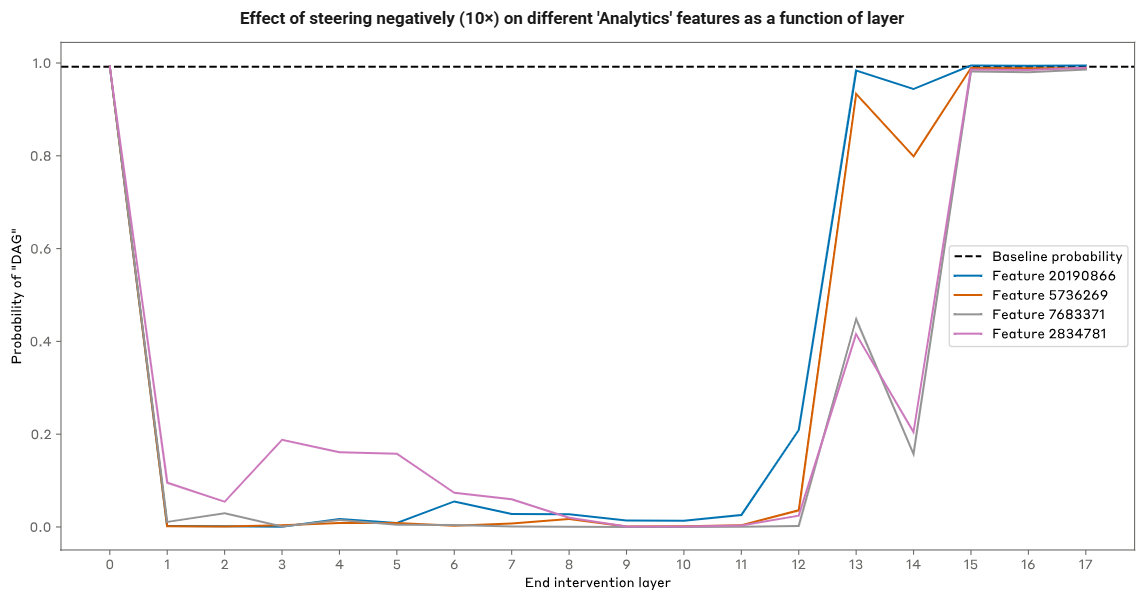
2.2.5 分析模型对事实的记忆
案例:输入“Fact: Michael Jordan plays the sport of”,会有 65%的概率补齐单词为“basketball”
归因图可视化:
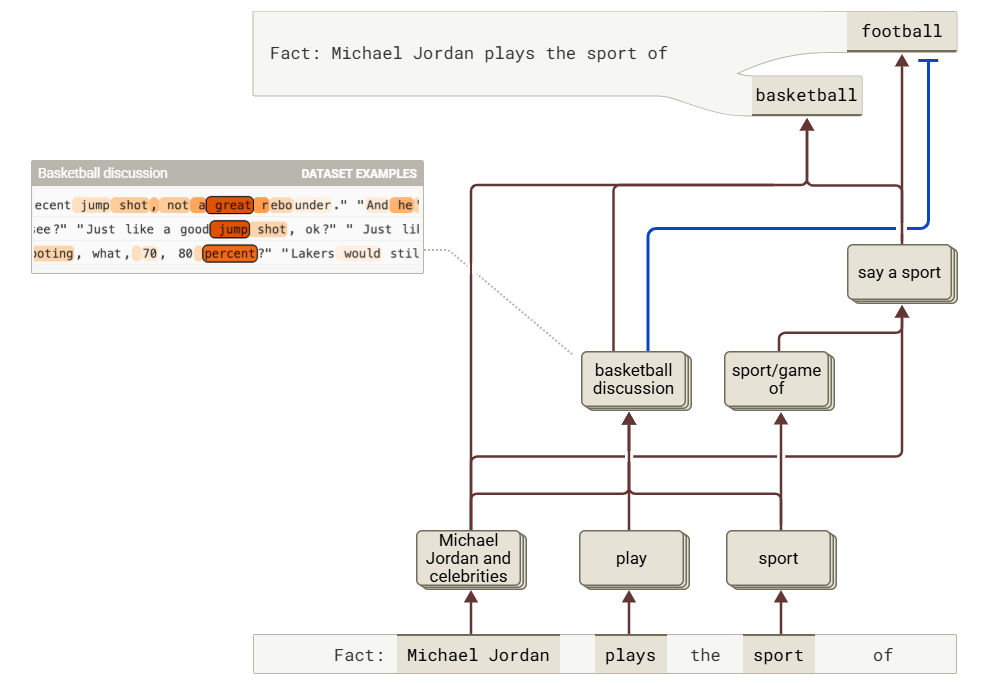
- 第一条路径,从“plays”和“sport”开始,激活了篮球、足球等运动相关稀疏特征
- 第二条路径,从“Michael Jordan”开始,正向引导了篮球的激活,并抑制了足球的激活
归因图可视化详情:
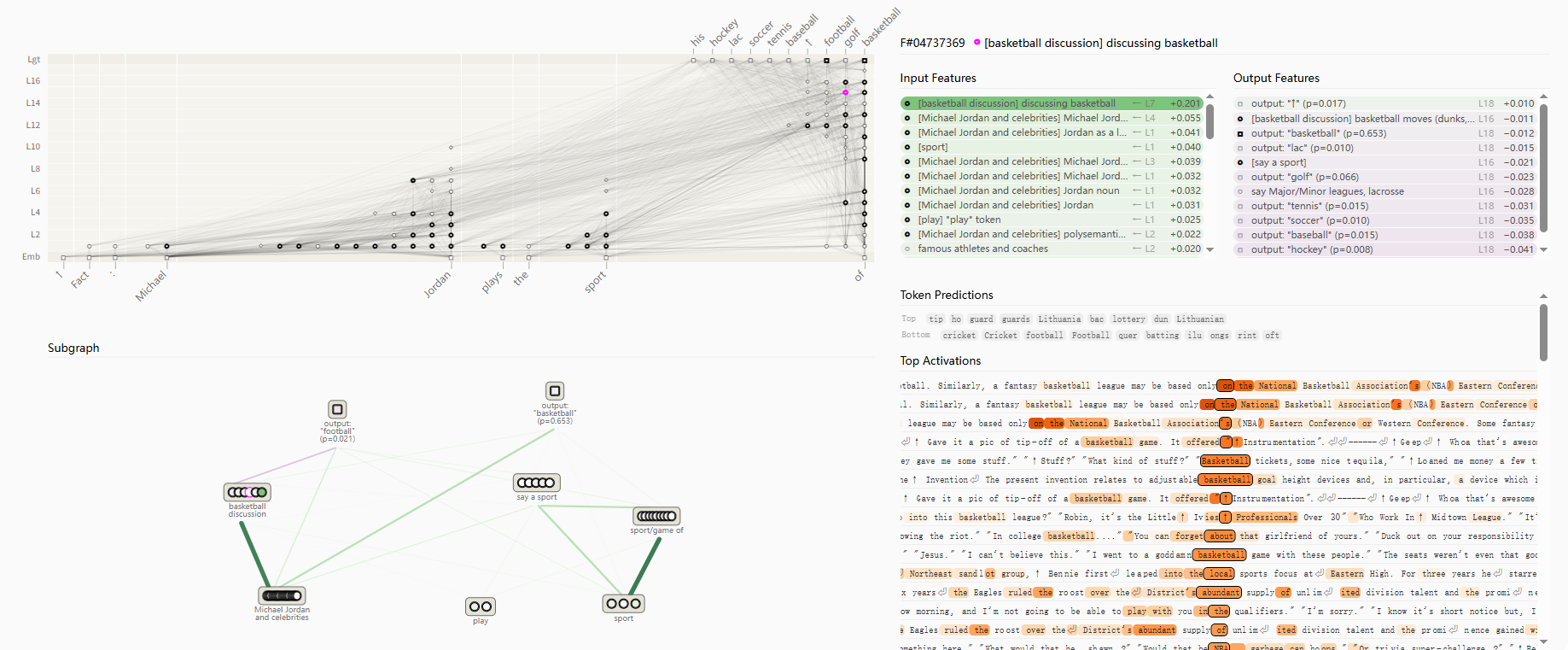
- 删除“sport” 或 “Michael Jordan”超节点,对输出概率的影响较大,但对其他超节点影响较小,这说明模型的思维路径并不是简单的单线推理,而是存在并行路径结构
- 抑制中间节点“basketball discussion”,也会对输出概率有较大的影响
2.2.6 分析模型的加法运算
案例:输入“calc: 36+59”,期望输出为“95”
归因图可视化:
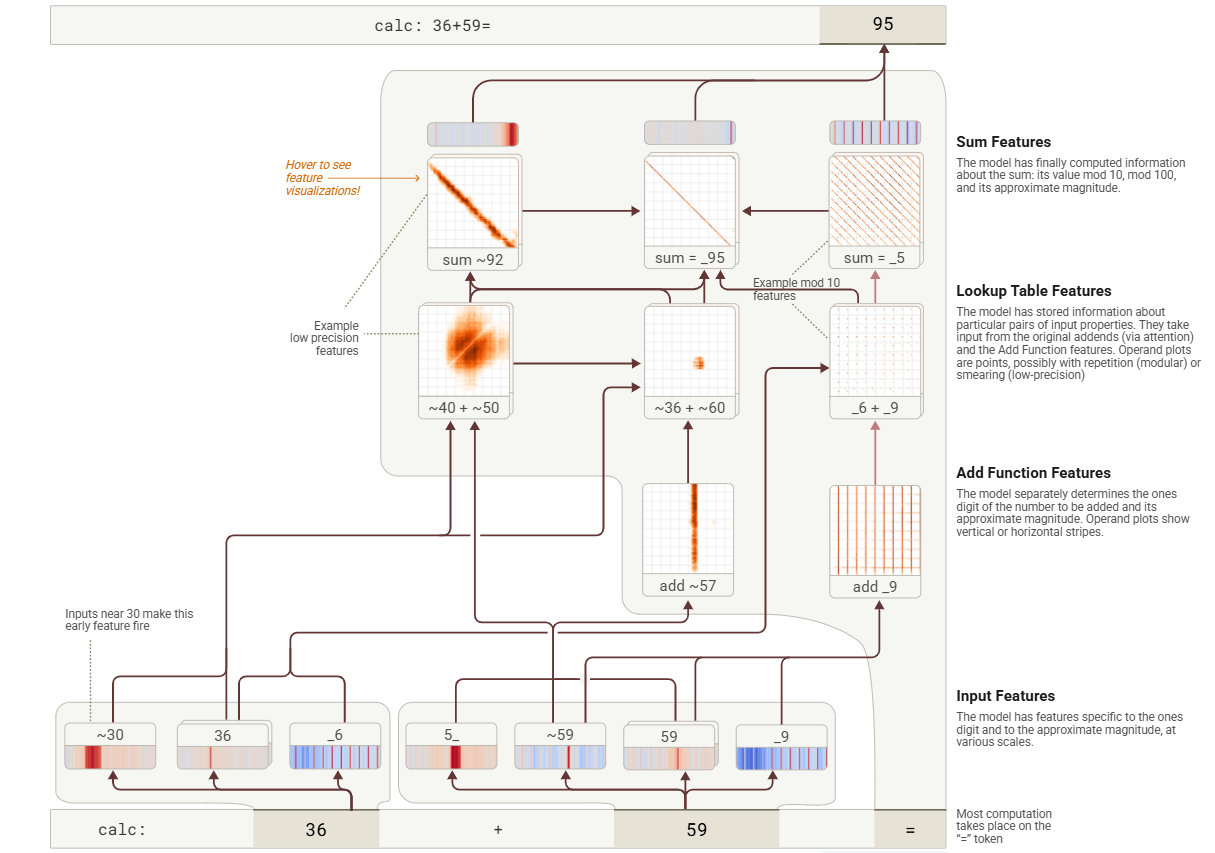
- 左侧路径:将输入进行近似处理,然后进行低精度计算 “~40+~50=~92”
- 中间路径:针对输入项进行中精度计算 “~36+~60=_ 95”,其中“sum=_ 95”节点中的对角线结构表示对求和(sum)操作的某种约束
- 右侧路径:针对个位数进行精确计算 “_ 6 + _ 9 = _ 5”,其中“add=_ 9”节点中的网格结构表示对输入数字的模运算(modular)操作约束
归因图的干预分析:
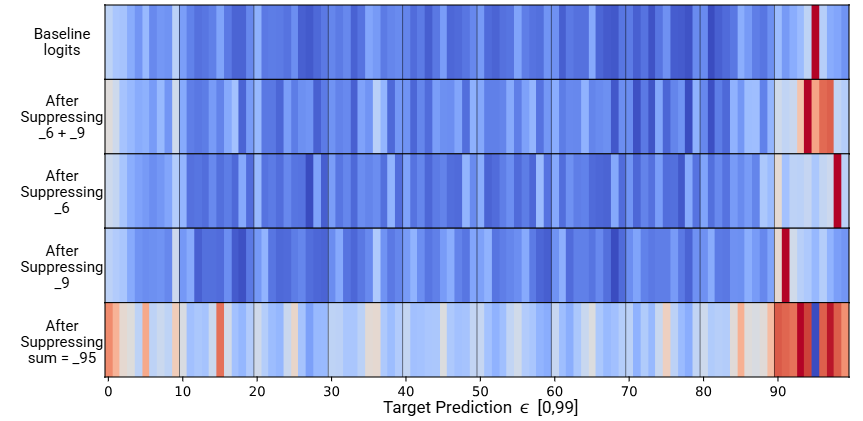
- 抑制输入 token 中的个位数特征,会导致整个右侧路径的抑制
- 当抑制 _ 6 时,模型会自信地输出 98 而不是正确答案 95
- 当抑制 _ 6 和 _ 9 时,模型的预测结果范围会变得模糊(±5)
2.2.7 归因图中的全局权重
全局权重:用于描述两个特征之间与上下文无关的相互作用
从虚拟权重到全局权重
- 虚拟权重是全局权重的一种,但存在大量没有因果影响的干扰项
- 归因图中的虚拟权重,会考虑每个特征与其他所有特征的连接,但其中的某些特征对这实际分布中从未共同激活过,因此在这种情况下,虚拟权重并不适合作为全局权重来解释模型行为
- 优化思路:考虑引入共激活统计量(co-activation statistics)来应对虚拟权重中的干扰
- 具体操作:假设源特征 $i$ 的激活值为 $a_{i}$,目标特征 $j$ 的激活值为 $a_{j}$,二者间的虚拟权重为 $V_{ij}$,可以定义目标加权预期残差归因(TWERA)作为最终的全局权重
$$ V_{ij}^{TWERA}=\frac{E[a_{j}a_{i}]}{E[a_{j}]}V_{ij} $$
- 修正后的 TWERA,用目标激活值对虚拟权重进行加权,规避了源特征容易存在的多义性问题,同时也排除了源特征未激活的情况(仅考虑在实际分布存在特征-特征共激活时的信息)
虚拟权重 VS 全局权重
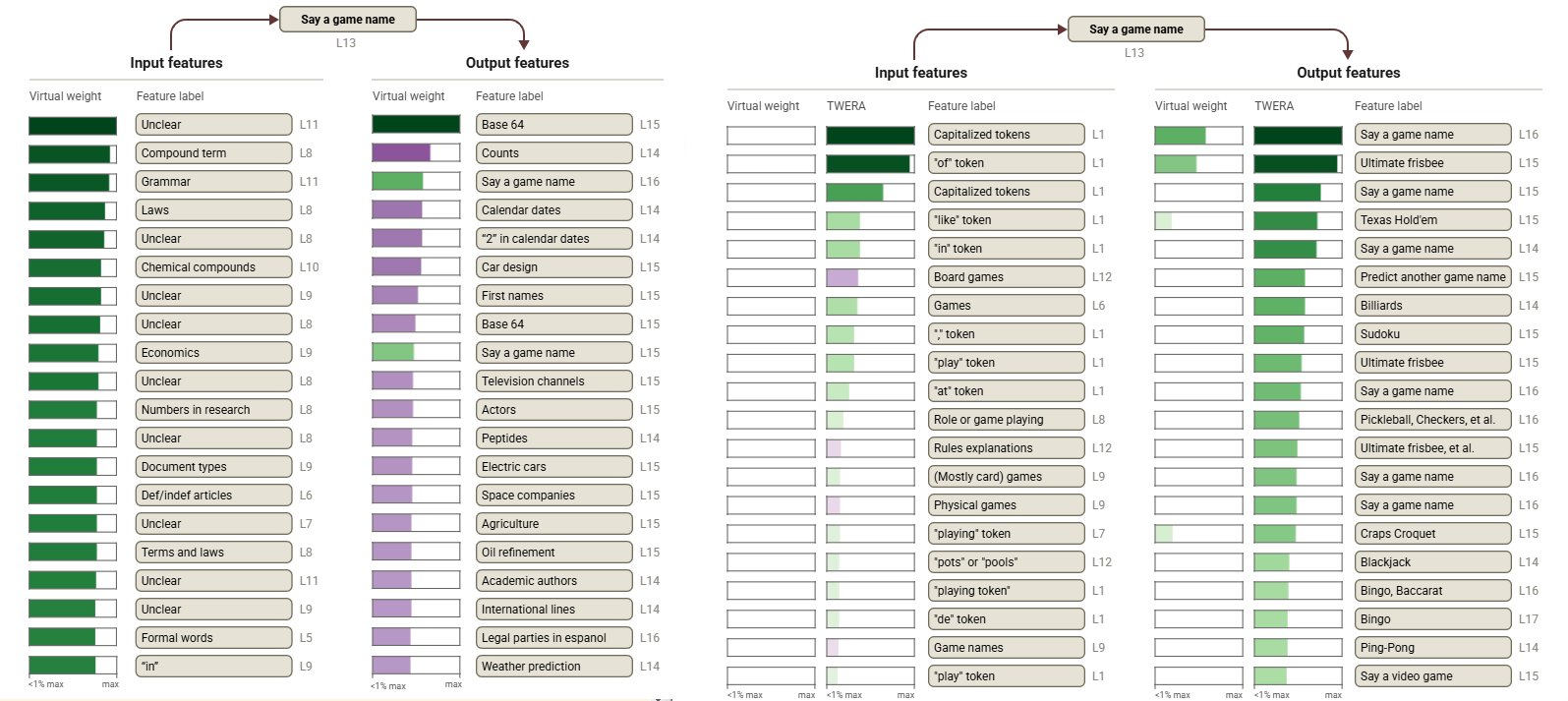
- 以“say a game name”作为提示文本,进行 TopN 虚拟权重的特征可视化
- 上图中,绿色表示存在正向连接,紫色表示存在负向连接
- 原始虚拟权重(左)较高的特征存在较多难以解释或无关的情况
- 修正后的全局权重(右)较高的特征则具备更强的相关性和可解释性
2.3 实验分析与评价
可解释性评估:主要通过多个具体案例的定性评估来说明归因图的有效性
- 多步推理:模型通过两步推理得出“达拉斯所在州的首府是...”,即“达拉斯→德克萨斯→奥斯汀”
- 诗歌创作:模型在每行诗歌创作前,会考虑潜在韵脚词并进行选择,进而影响整行的创作思路
- 多语言:模型会综合考虑语言特定的节点和语言无关的抽象概念节点
- 加法计算:加法计算归因图在不同语境中存在泛化,不同规模 LLMs 的归因图存在定性差异
- 医疗诊断:模型会根据症状来识别诊断候选,然后来引导出后续可用于证实诊断的症状
- 实体识别与幻觉:面对模型不熟悉的实体,模型可能触发特定的归因图,从而导致幻觉
- 拒绝有害请求:经过微调后的模型存在一个通用的特征节点,用于识别和聚合有害请求
- 越狱分析:诱导模型执行危险的指令,该情况是由于模型对句法和语法规则的遵从压力
- 思维链的忠诚性:通过归因图可区分出模型编造推理、虚假执行、谄媚讨好等不良行为
- 带有隐藏目标的模型:通过归因图可以暴露模型不愿公开表明的目标和深层“模型人格”
CLT 的定量评估:
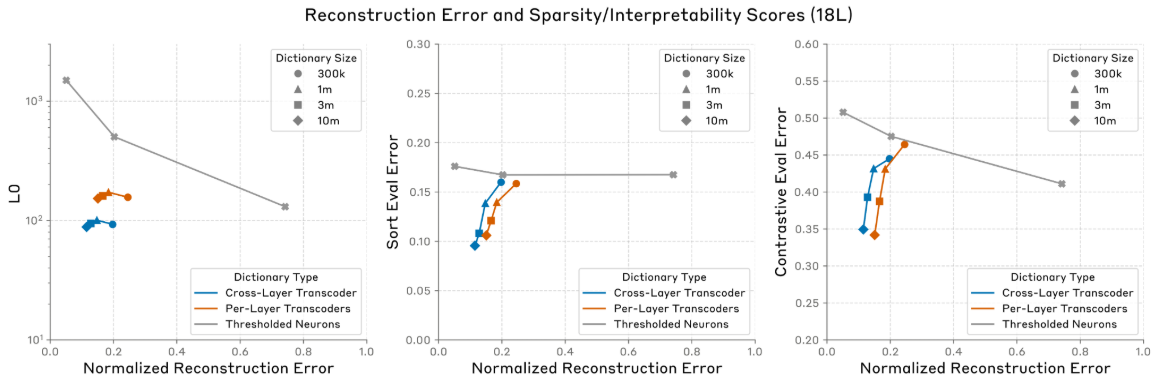
- 随着稀疏特征字典的规模增加,CLT 重建损失在下降,并且优于逐层转码器(PLT)
- L0 描述了特征稀疏性(每个 token 对应的平均稀疏激活特征数量),CLT 优于 PLT
- Sort Eval 是一种排序评估方法,通过随机抽取两个特征,然后对示例数据集进行排序,找到对特征的激活程度最高的 TopN 示例数据集;CLT 的排序评估损失,明显小于 PLT
- Contrastive Eval 是一种对比评估方法,给定两个结构相似但内容不同的提示对,让 Claude 通过分析特征的归因图可视化结果,来猜测归因图结果相对应的提示;CLT 的对比评估损失,明显小于 PLT
路径长度 VS 路径影响
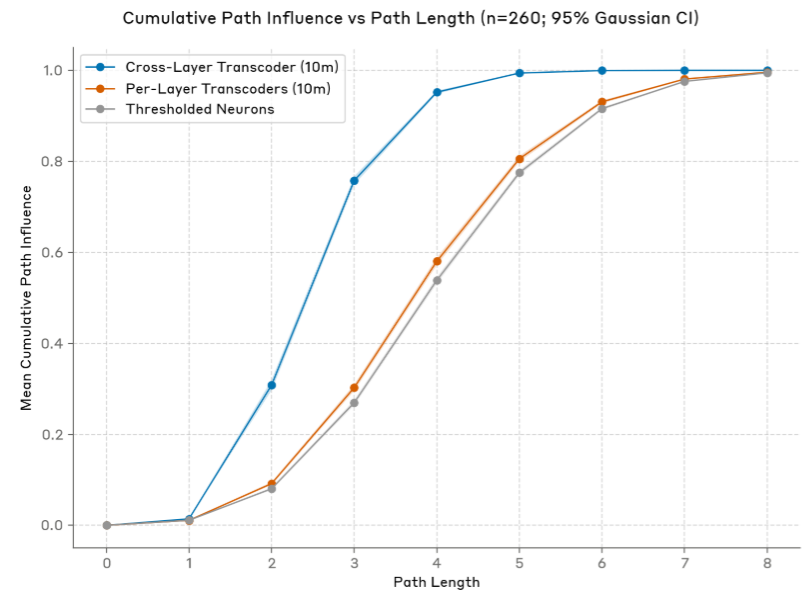
- CLT 的重要优势,就是在保留路径影响程度的情况下,显著减少了路径长度
- 该特性使得 CLT 能自动折叠特征,简化路径复杂度,降低可解释性的难度
归因图的综合评价
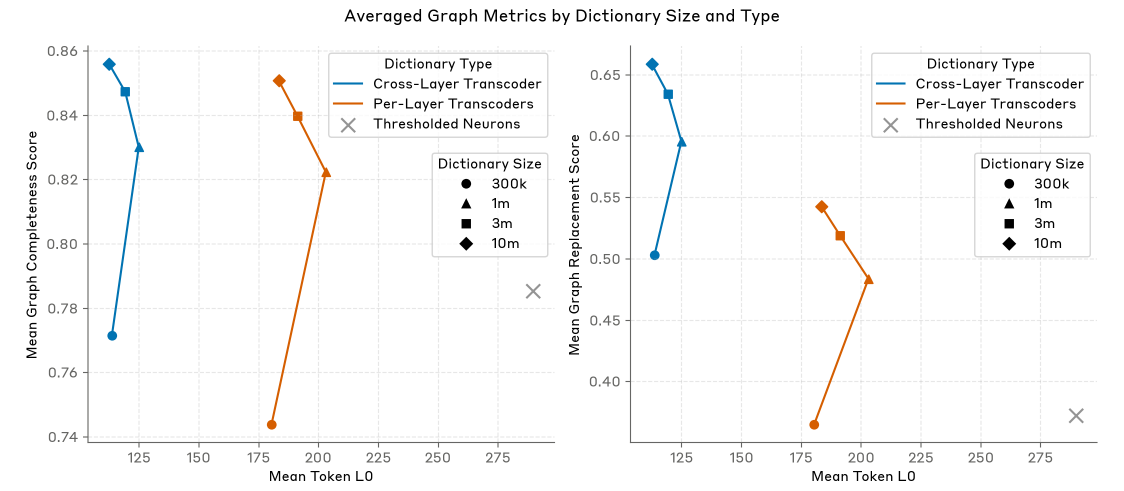
- 在不同字典规模的情况下,借助 CLT 构建的归因图的稀疏性均显著 PLT
- 图完备性得分(Graph completeness score),主要计算的是影响预测输出中输入节点或中间节点的加权占比,即误差节点对预测输出的影响越小,图完备性得分越高;CLT 归因图的图完备性得分高于 PLT
- 图替换得分(Graph replacement score),主要计算的是输入节点通过中间节点(而非误差节点)影响到预测输出的占比;CLT 归因图的替换得分高于 PLT
注意:本文默认的图剪枝策略,会导致 CLT 归因图的图完备性得分下降至 69%
局限性:
- 缺少对注意力机制的轨迹追踪,可能错过模型思考中的有趣部分
- 存在客观的重建误差,仅能实现模型的部分解释
- 某些未激活的特征节点,也具备继续深入挖掘的价值
- 特定情况下的归因图,可能过于复杂并难以理解
- 特征节点可能存在多层次的抽象,需要进一步的拆分或合并
- 依然很难从全局方式来理解模型,只是通过特定示例来归因
- 利用 CLT 的替换过程存在客观误差,可能导致对原始模型的误解
后记
Anthropic 官方推出的电路追踪案例解读文章
- 忽略技术细节,相比原始论文更浅显易懂