1 简介
本节课程将介绍如何使用LangChain和自有数据进行对话
LangChain的组件包括:
- 提示(Prompts): 使模型执行操作的方式。
- 模型(Models):大语言模型、对话模型,文本表示模型。目前包含多个模型的集成。
- 索引(Indexes): 获取数据的方式,可以与模型结合使用。
- 链(Chains): 端到端功能实现。
- 代理(Agents): 使用模型作为推理引擎
课程内容:
- 介绍如何使用LangChain文档加载器 (Document Loader)从不同数据源加载文档
- 学习如何将这些文档切割为具有语意的段落(不同的处理可能会影响颇大)
- 简要介绍语义搜索(Semantic search),以及信息检索的基础方法——如何根据用户输入的问题,获取最相关的信息。同时分析该方法的不适用场景以及解决方案
- 如何使用检索得到的文档,来让大语言模型(LLM)来回答关于文档的问题
2 文档加载
- 加载PDF文件
# !pip install -q pypdf
from langchain.document_loaders import PyPDFLoader
# 创建一个 PyPDFLoader Class 实例,输入为待加载的pdf文档路径
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
# 调用 PyPDFLoader Class 的函数 load对pdf文件进行加载
pages = loader.load()
print(type(pages), len(pages)) # List格式,长度为22
print(page.page_content[0:500]) # 文本内容
print(page.metadata) # 元数据
- 加载YouTube音频
# !pip -q install yt_dlp
# !pip -q install pydub
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
url="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
# 创建一个 GenericLoader Class 实例
loader = GenericLoader(
# 将链接url中的Youtube视频的音频下载下来,存在本地路径save_dir
YoutubeAudioLoader([url],save_dir),
# 使用OpenAIWhisperPaser解析器将音频转化为文本
OpenAIWhisperParser()
)
# 调用 GenericLoader Class 的函数 load对视频的音频文件进行加载
docs = loader.load()
docs中的每一元素为一个文档,变量类型为langchain.schema.document.Document, 文档变量类型包含两个属性:page_content包含该文档的内容,meta_data为文档相关的描述性数据。
- 加载网页文档
from langchain.document_loaders import WebBaseLoader
# 创建一个 WebBaseLoader Class 实例
url = "https://github.com/basecamp/handbook/blob/master/37signals-is-you.md"
header = {'User-Agent': 'python-requests/2.27.1',
'Accept-Encoding': 'gzip, deflate, br',
'Accept': '*/*',
'Connection': 'keep-alive'}
loader = WebBaseLoader(web_path=url,header_template=header)
# 调用 WebBaseLoader Class 的函数 load对文件进行加载
docs = loader.load()
import json
convert_to_json = json.loads(doc.page_content)
extracted_markdow = convert_to_json['payload']['blob']['richText']
print(extracted_markdow) # 后处理json格式的信息
- 加载Notion文档
- 点击Notion示例文档右上方复制按钮(Duplicate),复制文档到你的Notion空间
- 点击右上方
⋯按钮,选择导出为Mardown&CSV。导出的文件将为zip文件夹 - 解压并保存mardown文档到本地路径
docs/Notion_DB/
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("docs/Notion_DB")
docs = loader.load()
3 文档分割
将文档分割成较小的文本块,方便后续的工作展开(比如加载到向量数据库中)
Langchain中文本分割器都根据chunk_size(块大小,指每个块包含的字符或Token的数量)和chunk_overlap(块与块之间的重叠大小,指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息)进行分割
Langchain中常用的文档分割方式:基于字符/token/指定分隔符的分割
- 基于字符的分割
RecursiveCharacterTextSplitter:将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
chunk_size = 26 # 设置块大小
chunk_overlap = 4 # 设置块重叠大小
# 初始化文本分割器
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
# 使用递归字符文本分割器
text2 = "abcdefghijklmnopqrstuvwxyzabcdefg"
r_splitter.split_text(text2)
# 使用字符文本分割器(默认以换行符为分隔符)
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
c_splitter.split_text(text3)
# 设置空格分隔符
c_splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator=' '
)
c_splitter.split_text(text3)
更建议在通用文本中使用递归字符文本分割器
- 基于token的分割
很多LLM的上下文窗口长度限制是按照Token来计数的。因此,以LLM的视角,按照Token对文本进行分隔,通常可以得到更好的结果
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0)
text1 = "foo bar bazzyfoo"
text_splitter.split_text(text1)
- 分割Markdown文档
Markdown标题文本分割器会根据标题或子标题来分割一个Markdown文档,并将标题作为元数据添加到每个块中
from langchain.text_splitter import MarkdownHeaderTextSplitter # markdown分割器
markdown_document = """# Title\n\n \
## 第一章\n\n \
李白乘舟将欲行\n\n 忽然岸上踏歌声\n\n \
### Section \n\n \
桃花潭水深千尺 \n\n
## 第二章\n\n \
不及汪伦送我情"""
# 定义想要分割的标题列表和名称
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on) # 分割文档
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits[0] # 第一个块
4 向量数据库与词向量
检索增强生成(RAG)的整体工作流程:
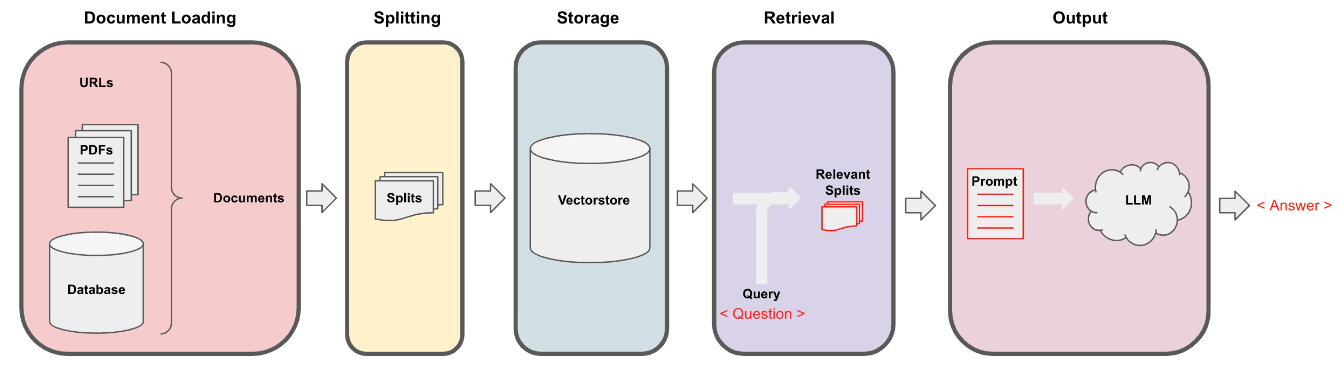
Embeddings(嵌入)是一种将类别数据,如单词、句子或者整个文档,转化为实数向量的技术
Langchain集成了超过30个不同的向量存储库,本教程默认使用Chroma(轻量级且数据存储在内存中,启动方便,容易上手),更多向量数据库细节 #待补充
import numpy as np
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyPDFLoader
# 加载 PDF(下载地址:https://see.stanford.edu/Course/CS229)
loaders = [
# 故意添加重复文档,使数据混乱
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf")
]
docs = []
for loader in loaders:
docs.extend(loader.load())
# 分割文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500, # 每个文本块的大小;切分文本时会尽量使每个块包含 1500 个字符
chunk_overlap = 150 # 每个文本块之间的重叠部分
)
splits = text_splitter.split_documents(docs)
sentence1 = "i like dogs"
sentence2 = "i like canines"
sentence3 = "the weather is ugly outside"
# Embedding处理
embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)
np.dot(embedding1, embedding2) # 查看相似度
np.dot(embedding1, embedding3)
np.dot(embedding2, embedding3)
# 配置向量数据库的存储路径
persist_directory = 'docs/chroma/cs229_lectures/'
# 删除旧的数据库文件(如果文件夹中有文件的话),window电脑请手动删除
!rm -rf './docs/chroma/cs229_lectures'
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 向量数据库实践:查询最相似的文本块
question = "is there an email i can ask for help"
docs = vectordb.similarity_search(question,k=3)
docs[0].page_content
vectordb.persist() # 持久化向量数据库
相似性搜索可能存在失败的情况,比如文本块重复或者错误匹配的问题
这些问题将会在下一小节中得到解决
5 检索 retrieval
检索是检索增强生成(RAG)流程的核心
最大边际相关性(Maximum marginal relevance,MMR):平衡查询的相关性和结果的多样性之间实现两全其美,以此避免查询结果的文本块重复问题
元数据(metadata):为每个嵌入的块(embedded chunk)提供上下文信息;很多向量数据库都支持metadata;根据元数据进行文本过滤,可以改善查询结果的错误匹配问题
SelfQueryRetriever:来自langchain的组件,可以根据LLM自动抽取元信息,并构建过滤器
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/cs229_lectures/'
embedding = OpenAIEmbeddings() # 加载上一节保存的向量数据库
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)
# 示例文本
texts = ["""The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).""",
"""A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.""",
"""A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms."""]
smalldb = Chroma.from_texts(texts, embedding=embedding)
question = "Tell me about all-white mushrooms with large fruiting bodies"
smalldb.similarity_search(question, k=2) # 根据问题搜索最相关的2份文档
# 方法1:使用MMR查询
smalldb.max_marginal_relevance_search(question,k=2, fetch_k=3)
# 方法2:手动添加基于元数据的过滤器
question = "what did they say about regression in the third lecture?"
docs = vectordb.similarity_search(
question, k=3,
filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"}
)
# 方法3:借助LLMs自动添加基于元数据的过滤器
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
llm = OpenAI(temperature=0)
metadata_field_info = [ # 定义元信息的结构
AttributeInfo(
name="source",
description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`",
type="string",
),
AttributeInfo(
name="page",
description="The page from the lecture",
type="integer",
),
]
document_content_description = "Lecture notes"
retriever = SelfQueryRetriever.from_llm(
llm,vectordb,
document_content_description,
metadata_field_info,verbose=True
)
question = "what did they say about regression in the third lecture?"
docs = retriever.get_relevant_documents(question)
另一种提高检索到的文档质量的方法是压缩(降低LLM调用和响应成本):
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
def pretty_print_docs(docs):
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm) # 压缩器
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever()
)
question = "what did they say about matlab?"
compressed_docs = compression_retriever.get_relevant_documents(question)
print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(compressed_docs)]))
LangChain检索器抽象包括其他检索文档的方式,如:TF-IDF或SVM
6 问答
一个简单的检索式问答示例:
# 加载在之前已经进行持久化的向量数据库
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/cs229_lectures/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA # 导入检索式问答链
llm = ChatOpenAI(model_name=llm_name, temperature=0)
qa_chain = RetrievalQA.from_chain_type( # 声明一个检索式问答链
llm,retriever=vectordb.as_retriever())
# 可以以该方式进行检索问答
question = "What are major topics for this class?"
result = qa_chain({"query": question})
result["result"]
如何在许多种不同类型的文本块上执行相同的问答?
- Map Reduce:将所有文本块与问题分别传递给LLMs获取回复,使用另一个LLMs对所有单独的回复汇总,总结成最终答案。该方法将所有文档视为独立的,对文档数量无限制,支持并行处理,但调用成本高
- Refine:在不同的文本块上循环迭代,每次的回复都建立在先前文档的答案之上,适合根据前后因果信息并随时间逐步构建答案,依赖于先前调用的结果。不支持并行,耗时更长,调用成本与Map Reduce一样高
- Map Re-rank:对每个文档单独调用单个LLMs,并要求它返回一个分数,选择最高分对应的回复。需要LLMs知道分数应该是什么(与Query越相关,则分数越高),需要精调和说明,支持并行处理,调用成本高
- Stuff:将所有内容组合成一个文档
进阶1:基于模板的检索式问答链(默认是Stuff)
from langchain.prompts import PromptTemplate
# Build prompt
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
# Run chain
qa_chain = RetrievalQA.from_chain_type(
llm, retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
上下文窗口长度有限,不适用于文档过多的情况
进阶2:基于MapReduce的检索式问答链
qa_chain_mr = RetrievalQA.from_chain_type(
llm, retriever=vectordb.as_retriever(),
chain_type="map_reduce"
)
MapReduce方法运行速度慢,效果也一般,没用到不同文档间的交叉信息
进阶3:基于Refine的检索式问答链
qa_chain_mr = RetrievalQA.from_chain_type(
llm, retriever=vectordb.as_retriever(),
chain_type="refine"
)
Refine方法更鼓励文档间的信息交流,一般效果会优于MapReduce
7 聊天
相比于检索式问答,聊天机器人会在尝试回答时考虑聊天历史的上下文
本小节将使用 ConversationBufferMemory保存聊天消息历史记录的列表,这些历史记录将在回答问题时与问题一起传递给聊天机器人,从而将它们添加到上下文中
对话检索链(ConversationalRetrievalChain)在 QA 检索链的基础上增加了一个新步骤,该步骤将历史记录和新问题浓缩为一个独立的问题,并将其传递给向量存储器以查找相关文档
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history", # 与 prompt 的输入变量保持一致。
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串
)
from langchain.chains import ConversationalRetrievalChain
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm, retriever=retriever, memory=memory)
question = "Is probability a class topic?"
result = qa({"question": question})
print(result['answer'])
最终的聊天机器人代码demo:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
def load_db(file, chain_type, k):
"""
该函数用于加载 PDF 文件,切分文档,生成文档的嵌入向量,创建向量数据库,定义检索器,并创建聊天机器人实例。
参数:
file (str): 要加载的 PDF 文件路径。
chain_type (str): 链类型,用于指定聊天机器人的类型。
k (int): 在检索过程中,返回最相似的 k 个结果。
返回:
qa (ConversationalRetrievalChain): 创建的聊天机器人实例。
"""
# 载入文档
loader = PyPDFLoader(file)
documents = loader.load()
# 切分文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# 定义 Embeddings
embeddings = OpenAIEmbeddings()
# 根据数据创建向量数据库
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# 定义检索器
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# 创建 chatbot 链,Memory 由外部管理
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(model_name=llm_name, temperature=0),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
)
return qa
import panel as pn
import param
# 用于存储聊天记录、回答、数据库查询和回复
class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([])
def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf"
self.qa = load_db(self.loaded_file,"stuff", 4)
# 将文档加载到聊天机器人中
def call_load_db(self, count):
"""
count: 数量
"""
if count == 0 or file_input.value is None: # 初始化或未指定文件 :
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
else:
file_input.save("temp.pdf") # 本地副本
self.loaded_file = file_input.filename
button_load.button_style="outline"
self.qa = load_db("temp.pdf", "stuff", 4)
button_load.button_style="solid"
self.clr_history()
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
# 处理对话链
def convchain(self, query):
"""
query: 用户的查询
"""
if not query:
return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.db_response = result["source_documents"]
self.answer = result['answer']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=600)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
])
inp.value = '' # 清除时清除装载指示器
return pn.WidgetBox(*self.panels,scroll=True)
# 获取最后发送到数据库的问题
@param.depends('db_query ', )
def get_lquest(self):
if not self.db_query :
return pn.Column(
pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),
pn.Row(pn.pane.Str("no DB accesses so far"))
)
return pn.Column(
pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),
pn.pane.Str(self.db_query )
)
# 获取数据库返回的源文件
@param.depends('db_response', )
def get_sources(self):
if not self.db_response:
return
rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]
for doc in self.db_response:
rlist.append(pn.Row(pn.pane.Str(doc)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
# 获取当前聊天记录
@param.depends('convchain', 'clr_history')
def get_chats(self):
if not self.chat_history:
return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)
rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]
for exchange in self.chat_history:
rlist.append(pn.Row(pn.pane.Str(exchange)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
# 清除聊天记录
def clr_history(self,count=0):
self.chat_history = []
return
# 初始化聊天机器人
cb = cbfs()
# 定义界面的小部件
file_input = pn.widgets.FileInput(accept='.pdf') # PDF 文件的文件输入小部件
button_load = pn.widgets.Button(name="Load DB", button_type='primary') # 加载数据库的按钮
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning') # 清除聊天记录的按钮
button_clearhistory.on_click(cb.clr_history) # 将清除历史记录功能绑定到按钮上
inp = pn.widgets.TextInput( placeholder='Enter text here…') # 用于用户查询的文本输入小部件
# 将加载数据库和对话的函数绑定到相应的部件上
bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp)
jpg_pane = pn.pane.Image( './img/convchain.jpg')
# 使用 Panel 定义界面布局
tab1 = pn.Column(
pn.Row(inp),
pn.layout.Divider(),
pn.panel(conversation, loading_indicator=True, height=300),
pn.layout.Divider(),
)
tab2= pn.Column(
pn.panel(cb.get_lquest),
pn.layout.Divider(),
pn.panel(cb.get_sources ),
)
tab3= pn.Column(
pn.panel(cb.get_chats),
pn.layout.Divider(),
)
tab4=pn.Column(
pn.Row( file_input, button_load, bound_button_load),
pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )),
pn.layout.Divider(),
pn.Row(jpg_pane.clone(width=400))
)
# 将所有选项卡合并为一个仪表盘
dashboard = pn.Column(
pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')),
pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4))
)
dashboard
其他补充:
8 总结
- 使用 LangChain 的 80 多种文档装载器从各种文档源中加载数据。
- 将这些文档分割成块,并讨论了其中的一些微妙之处。
- 为这些块创建了 Embedding,并将它们放入向量存储器中,并轻松实现语义搜索。
- 讨论了语义搜索的一些缺点,以及在某些边缘情况中可能会发生的搜索失败。
- 介绍了许多新的高级且有趣的检索算法,用于克服那些边缘情况。
- 与 LLMs 相结合,将检索到的文档,和用户问题传递给 LLM,生成对原始问题的答案。
- 对对话内容进行了补全,创建了一个完全功能的、端到端的聊天机器人。