1 基本信息
1.1 书籍名称:《Approaching (Almost) Any Machine Learning Problem》
1.2 撰写作者:Abhishek Thakur
1.3 出版日期:在线书籍
1.4 品读时间:2023年8月下旬
1.5 整体耗时:约6h
1.6 摘要
本文围绕不同赛题/示例,对机器学习相关内容有较为完整的代码实战展示
主要内容:环境配置、机器学习基本概念、模型的交叉验证与基本评估指标、常见的数据的清洗和预处理方法、常用特征工程的构建思路、特征选择与超参优化、深度学习入门(处理图像/文本问题)、集成学习入门、模型部署(docker与flask)
1.7 特点
- 本书内容较为基础,并包含很多实用的细节技巧
- 本书包含很多Kaggle比赛的代码实战和解题思路
- 适合作为有一定理论基础的学习者进行实践入门
1.8 评分:⭐⭐⭐⭐
2 大纲
2.1 环境配置
本书环境为Ubuntu 18.04 + Python 3.7.6
本书推荐使用Anaconda3或Minicanda3来配置Python环境
阅读本书前需要具备一定的机器学习和深度学习的基础知识
注意:本笔记仅对其中核心内容和部分细节进行记录,忽略了较多代码的实现
2.2 算法分类
有监督学习 vs 无监督学习
- 有监督学习的数据一般包含与学习目标相关的变量;比如根据历史房价预测未来房价,根据已标注的图像来区分猫狗;目标变量可以是数值或类别
- 无监督学习的数据一般不包含目标变量;一般比有监督学习更难;比如从海量的交易流水中识别到存在欺诈问题的情况;聚类算法(如 t-SNE)常用于解决无监督问题
分类问题 vs 回归问题
- 分类问题的预测目标是类别型,比如区分猫狗
- 回归问题的预测目标是数值型,比如预测房价
2.3 交叉验证
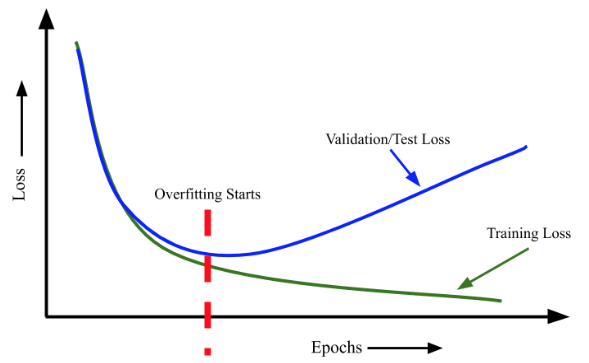
过拟合:
- 表现:随着训练损失的改善,模型在验证集的损失逐渐恶化
- 过拟合问题在神经网络的训练过程中很常见
- 当验证损失达到最小值时,应该提前停止训练(early-stopping)
奥卡姆剃刀原理:如无必要,勿增实体
交叉验证的作用:通过额外构建验证集,确保模型的训练不会发生过拟合
常见的交叉验证方法
- k折交叉验证(sklearn.model_selection.KFold):将数据划分为k个不同的互斥集合,每次使用其中的k-1份进行训练,剩下的1份用来验证(有时还会额外保留1份作为最终的测试集);最常见
- 分层k折交叉验证(sklearn.model_selection.StratifiedKFold):对于存在偏斜样本(比如90%的正样本+10%的负样本),可确保k折交叉验证中的每1份集合中样本也是偏斜的
- 基于保留的交叉验证:当数据量较大时(比如100w样本),k折交叉验证的计算成本会很高;该方法会单独划分验证集,再针对剩余不同训练集得到的模型进行统一评价;该方法也常用于时序数据(比如原始数据是2015~2019年商店每日销售额,可考虑将2019年每日销售额作为验证集)
- k样本交叉验证:当数据量较小并且模型计算成本不高时可考虑该方法;每次随机抽取其中的k个样本作为验证集,其他所有样本作为训练集(尽可能多的保留原始数据的信息)
- 分组k折交叉验证:考虑分组情况的k折交叉验证,比如一个患者对应多个样本,那该患者的所有样本只应该存在于训练集或验证集,而不能在两种集合中交叉出现
更多交叉验证方法及其实现可参阅sklearn官方文档-model_selection
问:如何将分层k折交叉验证应用于回归问题? 答:可考虑先分箱,再使用分层k折交叉验证
斯特奇法则(Sturge's Rule)常用于估计分箱数:$Number_{bins}=1+log_2(N)$
2.4 评估指标
常见模型评价指标的实现:sklearn官方文档-metrics
2.5 机器学习项目
本小节主要实现了一个基础版的机器学习项目
机器学习项目的文件夹框架:
- input:此文件夹包含机器学习项目的所有输入文件和数据
- src:保存与该项目相关的所有 python 脚本
- models:该文件夹保存所有经过训练的模型
- notebooks:所有 jupyter 笔记(即 .ipynb 文件)都存储在这个文件夹中
- README.md:markdown 文件,对项目、运行环境、模型(训练/部署)进行说明
- LICENSE:这文本文件,包含项目的许可证,例如 MIT、Apache 等
数据探索和数据校验的脚本,使用jupyter会更方便
src 文件夹的常用 python 脚本
- create_folds.py:将数据进行k折交叉处理
- train.py:读取已处理的数据并进行建模训练
- inference.py:部署模型服务时的对外接口
- models.py:定义基础模型
- config.py:存储配置信息(数据/模型文件位置)
- model_dispatcher.py:定义模型字典及其关键参数以方便模型的管理
其他细节:
- 使用
argparse包进行终端输入参数的解析 - 使用调度器(dispatcher)来获取给定名称的模型
- 避免使用
import *,影响程序的调试和问题追溯
2.6 分类变量处理
分类变量包括无序分类变量和有序(ordinal)分类变量两种
常见分类变量的处理逻辑:
- 首先一定要先提前处理缺失值(删除 or 将缺失情况看作单独的一类)
- 对于包含级别信息的文本(冷/温暖/热),可直接字典映射为有序值(0/1/2)
- 一般可考虑使用
scikit-learn包中的LabelEncoder类来处理分类变量(注意) - 使用
scikit-learn包中的OneHotEncoder类来对分类变量进行二值化处理(one-hot) - 使用
sparse.csr_matrix方法将one-hot编码变量转为稀疏矩阵,可减少内存占用
有时会存在部分分类变量,在训练集中不常见但在测试集中常见;此时可考虑将测试数据添加到训练中以更好地了解给定分类变量的特征;这可能导致过拟合,也可能不会;但只要这种特征信息在实际预测之前是可知的(比如分类变量的聚合特征),那这种设计应该是合理的
其他分类变量的处理细节:
- 不同分类变量之间的组合,可能会产生有用的衍生分类变量
- 使用分组聚合的方式,能获得分类变量的聚合特征(计数、均值、方差等)
- 引入"未知"这一类型,可以更好地兼容未来新引入的类型,从而避免模型预测失败
- 引入“稀有”(类型计数小于某一阈值)这一类型,也可以更好地兼容低频或未见过的类型
- 部分算法(如随机森林)在处理one-hot编码变量会耗时较长,此时可考虑使用奇异值分解(SVD)、主成分分析(PCA)等方法来对one-hot编码矩阵进行降维
- 还可以使用神经网络技术可以对分类变量进行嵌入式(embedding)编码
谨慎使用目标变量构建分类变量的聚合特征(比如对于预测房价任务,假设分类变量是城市分级,则可考虑将不同城市分级的房价均值/方差作为补充的聚合特征,但这很可能导致过拟合);
因此在使用此方法时需要严格限制训练集,避免验证集和测试集的信息泄露;即使是在使用k-折交叉验证的时候,也要确保每折训练时目标变量的聚合都没有验证集样本参与
2.7 特征工程
2.8 特征选择
2.9 超参数优化
网格搜索(model_selection.GridSearchCV):计算成本高,尤其是在超参数较多的情况下
随机搜索(model_selection.RandomizedSearchCV):效率高,但最终效果得不到保障
其他超参优化算法:下山单纯形算法(downhill simplex,也叫 Nelder-Mead)、 基于贝叶斯优化的高斯过程、遗传算法。相关代码实现可参阅 scikit-optimize (skopt) 库
另一个值得推荐的超参优化库是hyperopt-超参优化
2.10 图像分类和分割
本小节基于X光图像数据集来训练模型识别是否存在气胸的问题
- X光图像数据集包含10675张图片,其中有2379张存在气胸问题
- 原始图像为1024x1024尺寸的灰度图像,考虑调整为256x256的尺寸
- 先将图像转化为一维数组,使用随机森林构建baseline(AUC=0.72)
- 之后考虑深度学习,使用AlexNet从零开始训练,但AUC=0.66(低于baseline)
- 在考虑使用已经过预训练的resnet18进行微调,最终AUC=0.80(目前最优)
- 针对识别到气胸的图像,可以继续使用U-Net模型进行图像的分割
其他技术细节:
- ReLU、Padding、卷积/膨胀卷积、池化(最大池化检测边缘,平均池化平滑图像)
albumentations是一个图像增强库,可实现多种常见的图像增强方法- RLE 编码:节省标签的存储空间,实际使用时需要转换为mask格式来展示分割效果
- PyTorch集成了NVIDIA推出的amp模块,可实现混合精度的训练加速
其他常见神经网络架构:DenseNet、NASNet、PNASNet、VGG、Xception、ResNeXt、EfficientNet
PyTorch 的 torchvision 提供了许多模型的实现,例如 AlexNet。需要注意的是,Torchvision 中 AlexNet 的实现不是原始版本,而是参考的另一篇论文-基于特殊技巧实现的并发化卷积神经网络 #待补充
2.11 文本分类和回归
本小节基于IMDB电影评论数据集来训练模型区分评论中的正/负面情绪
- 一个简单的方式是制作两份单词列表(积极词 vs 消极词)
- 然后通过计算句子中积极词和消极词的数量来进行情绪区分
- 处理NLP问题的一个基础模型的词袋法(构建系数矩阵存储所有单词的词频)
from sklearn.feature_extraction.text import CountVectorizer
from nltk.tokenize import word_tokenize
corpus = [
"hello, how are you?",
"im getting bored at home. And you? What do you think?",
"did you know about counts",
"let's see if this works!",
"YES!!!!"] # create a corpus of sentences
# initialize CountVectorizer with word_tokenize from nltk as the tokenizer
ctv = CountVectorizer(tokenizer=word_tokenize, token_pattern=None)
ctv.fit(corpus) # fit the vectorizer on corpus
corpus_transformed = ctv.transform(corpus)
print(ctv.vocabulary_)
# {'hello': 14, ',': 2, 'how': 16, 'are': 7, 'you': 27, '?': 4, 'im': 18,
# 'getting': 13, 'bored': 9, 'at': 8, 'home': 15, '.': 3, 'and': 6, 'what':
# 24, 'do': 12, 'think': 22, 'did': 11, 'know': 19, 'about': 5, 'counts':
# 10, 'let': 20, "'s": 1, 'see': 21, 'if': 17, 'this': 23, 'works': 25,
# '!': 0, 'yes': 26}
- 考虑使用逻辑回归构建baseline,最终准确率达到了89%
- 尝试其他模型:朴素贝叶斯分类器的准确率85%(但训练速度会快很多)
- 尝试使用TFIDF处理文本,再使用逻辑回归,最终准确率90%
- 引入n-gram来丰富TFIDF抽取的文本信息,逻辑回归的准确率89%
- 借助FastText构建词向量并用于逻辑回归,准确率86%
- 借助预训练的词向量并配合BiLSTM,结果准确率90%
- 基于预训练的BERT模型进行微调,最终准确率93%(最优)
其他技术细节:
- NLTK是一个常用的自然语言工具包,可以用于文本处理(如分词,统计词频等)
- 词干提取和词形还原(stemming and lemmatization)可以将单词简化为最小形式
- 主题提取可以使用非负矩阵分解 (NMF) 或潜在语义分析 (LSA,SVD) 来完成
- 对文本进行清洗是合理的,但也要慎重(删除停止词可能丢失上下文信息)
- 常见的词向量方法:Word2Vec(CBoW/skip-gram)、FastText、GloVe
2.12 模型集成和堆栈
集成算法:平均法、投票法、学习法
2.13 代码规范和模型服务
使用 Python 构建 API 的最常见方法是使用 Flask(微型 Web 服务框架)