中文标题:中文语境的否定与推断意图识别
英文标题:Negation and Speculation Identification in Chinese Language
发布平台:ACL
发布日期:2015-01-01
引用量(非实时):33
DOI:缺失
作者:Bowei Zou, Qiaoming Zhu, Guodong Zhou
文章类型:conferencePaper
品读时间:2022-08-24 17:15
1 文章萃取
1.1 核心观点
本文提出了一个用于否定与推断意图识别的标准标注流程,并基于此流程构建并分享了一个的中文语料库CNeSp。针对线索词检测问题,本文提出了跨语言的线索词扩展策略;针对范围解析问题,本文提出了一种借助句法树结构形成范围候选集的新框架。经过实验分析,语料、策略和框架都充分验证了有效性
1.2 综合评价
- 针对语料的来源与标注流程进行了详实而严谨的说明
- 特征工程、线索词扩展策略、句法树结构等方面的运用具备借鉴意义
- 实验阶段较为全面,但使用的模型较为普通、常见
- 分享的数据集全网都没找不到,对应的官方网址也挂掉了。。。
1.3 评分:⭐⭐⭐
2 精读笔记
2.1 背景知识
否定意图:通过各种方法推翻一个命题的正确性 否定示例:所有住客均表示【不会追究酒店的这次管理失职】
推断意图:表达对一个陈述的态度或观点,具备主观性和确定性 推断示例:尽管上周五沪指盘中还受创业板的下跌所拖累,但【后期仍有望反弹】
识别否定与推断意图主要分为两个任务:
- 线索词检测(cue detection):寻找表达否定或推测的线索词
- 范围解析(scope resolution):确定线索在语句中的适用范围
示例中,加粗表示线索词 cue,【】表示范围 scope
2.2 语料构建
本小节主要描述CNeSp(Chinese Negation and Speculation)语料库的构建
数据源(三个子语料库)
- 科学文献:《中国计算机学报》(Vol.35(11))的19篇文章
- 产品评论:携程网站的821条酒店服务评论(主观性检测对情感分析影响很大)
- 金融文章:2013年4月新浪网“股市及时雨”栏目的311篇文章,其中有22.3%的句子包含否定意图,40.2%的句子包含推测意图
标注原则(部分借鉴自Bioscope语料库)
- cue本身必须包含在scope内(不考虑cue偏离scope的情况)
- cue应该是表示否定或推测的最小单位(示例:该股极有可能再度出现涨停)
- cue的标注仅依赖于上下文中的实际语义
- scope应尽可能覆盖到cue所对应内容的主体
- scope应该是一个连续的语句片段
- 一个典型的否定/推测词可能不是cue(示例:早茶的种类之多不得不赞)
最终的标注语料分析:
| 项目 | 科学文献 | 金融文章 | 产品评价 |
|---|---|---|---|
| 文章数量 | 19 | 311 | 821 |
| 语句数量 | 4630 | 7213 | 4998 |
| 句平均长度 | 30.4 | 30.7 | 24.1 |
| 否定语句数量 | 13.2 | 17.5 | 52.9 |
| 否定句平均长度 | 9.1 | 7.2 | 5.1 |
| 推断语句数量 | 21.6 | 30.5 | 22.6 |
| 推断句平均长度 | 12.3 | 15.0 | 6.9 |
最终标注结果的一致性(Kappa值):
| 类型 | 科学文献 | 金融文章 | 产品评价 |
|---|---|---|---|
| 否定-Cue | 0.96 | 0.96 | 0.93 |
| 否定-Cue&Scope | 0.90 | 0.91 | 0.88 |
| 推断-Cue | 0.94 | 0.90 | 0.93 |
| 推断-Cue&Scope | 0.93 | 0.85 | 0.89 |
2.3 线索词检测
线索词检测是一个分类问题,字符的标注方法为BIO(开始,内部,外部)
本小节进行线索词检测的模型是条件随机场CRFs,输入特征包含以下三种:
- 基于字符级的N-gram类特征:滑动窗口为5,最多考虑到3-gram
- 词汇特征:借助第三方词典及其标注,将部分字符组合并替换为词语
- 语素特征:搜集与否定和推断相关的语素,最终为布尔型特征(0或1)
跨语言线索词拓展策略:由于训练语料有限,并且只有一部分包含否定/推断线索词,所以本文借助中英文词汇的对齐,增强了模型对于未收录词的泛化能力
- 基于已有语料,选择5个中文核心线索词作为锚点
- 借助第三方中英文对齐语料,寻找中文核心线索词对应的英文线索词
- 再次借助中英文对齐语料,反向寻找英文线索词对应的中文线索词
- 借助第三方语料捕捉到的中文线索词实现了对原有核心线索词的扩充
中英文单词对齐概率公式: $$P_{align}=\alpha P(w_E|w_C)+(1-\alpha) P(w_C|w_E)$$ 其中$\alpha$为超参数,调整两个方向的条件概率贡献度
2.4 范围解析
范围解析是一个针对语句的分块问题,也是一个针对字符的二分类问题
不同于传统方式对范围的直接预测,本文提出了借助句法依赖树的子结构来指导线索词的候选作用范围的方法:假设$X$表示树结构中线索词对应的节点或更上层节点,则最终线索词的作用范围应该由$X$或其兄弟节点决定
举例:所有住客均表示不会追究酒店的这次管理失职
生成句法依赖树和候选作用范围:
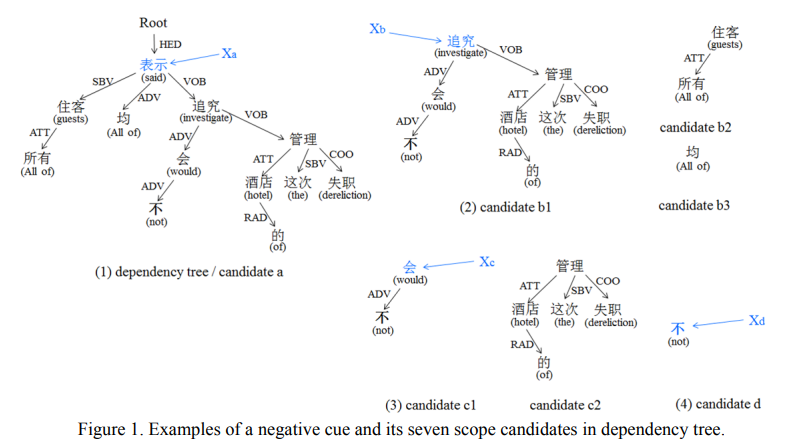
- 总共有7个作用范围的候选,其中候选$a$也用于展示完整的句法依赖树
- 7个作用范围候选中,包含否定线索词"不"的有四个,也对应了四种$X$
- $X_a$对应的作用范围是最大的(整个句子),$X_d$对应的作用范围是最小的(只有线索词)
- $X_b$对应的节点有两个兄弟节点,也因此衍生出了$b_2$和$b_3$这两个候选范围
除此之外,本文针对线索词和候选范围的词汇与句法特点,还构建了多个特征用于预测:
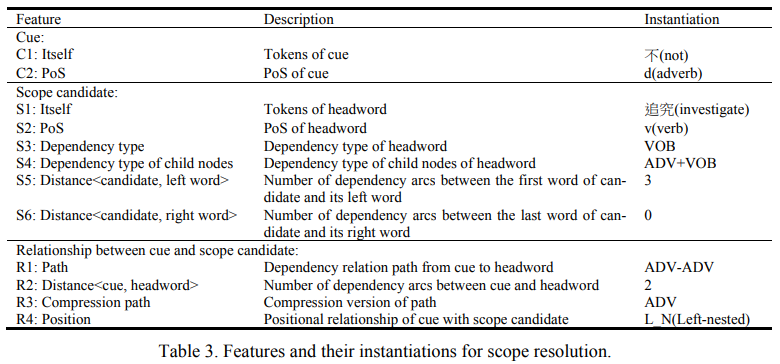
其中$R4:Position$描述了线索词与候选范围的关系,主要包括以下四种关系类型:

除此之外,本文还采用贪婪算法进行特征的筛选。实际预测与实验过程中,主要使用了SVM算法来处理范围解析转化来的二分类问题,并使用后处理方法将预测标签转化为范围。
2.5 线索词检测-实验
评价指标:召准率(P),召回率(R),F1值(F)
不同子语料的特征消融实验:
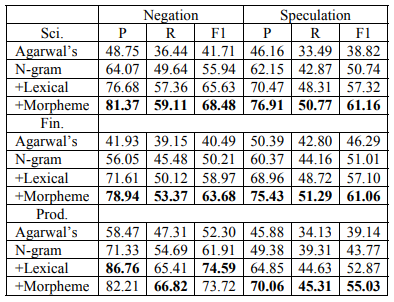
- 综合来看,三种特征的组合预测效果是最好的
- 产品评价语料中,加入语素特征导致召准率出现显著下降(-4.55%);经分析是因为"非常"包含了”非“这一否定语素,导致的模型误判
- 推断类型的线索词检测任务的召回率普遍偏低,经分析发现是由于线索词过于低频导致的,有83%(233/280)的推断线索词出现频次低于10
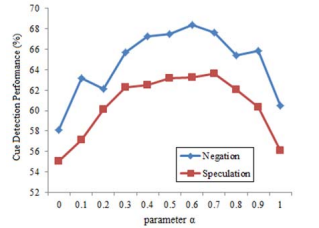
超参数$\alpha$的取值在0.6左右时,模型性能(准确率)较好:
跨语言线索词拓展策略对线索词检测的影响:
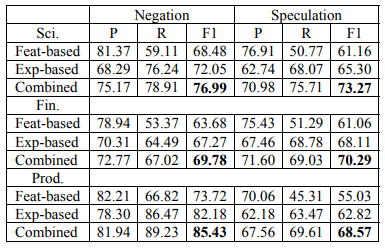
- 其中Feat-based表示只使用三类基础特征,Exp-based表示只使用跨语言线索词拓展策略获得的扩充线索词,Combined表示把以上两种方法结合起来
- 综合来看,跨语言线索词拓展策略对模型最终效果有显著提高
2.6 范围解析-实验
针对否定问题的范围解析,筛选出了7个特征:C1,C2,S4~S6,R1,R4 针对推断问题的范围解析,筛选出了9个特征:C2,S1,S3~S5,R1~R4
筛选特征对模型的效果改善:
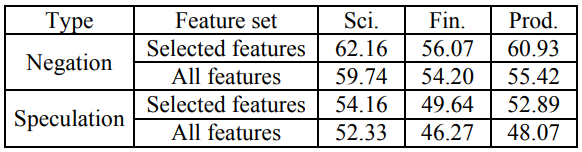
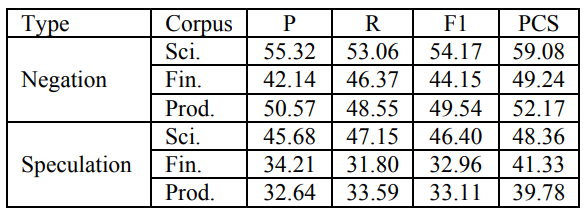
在线索词检测任务的评价指标基础上,引入了PCS(正确范围占比,Percentage of Correct Scopes)评价范围解析任务
上游任务(线索词检测)的误差会传递并影响到范围解析任务的表现:
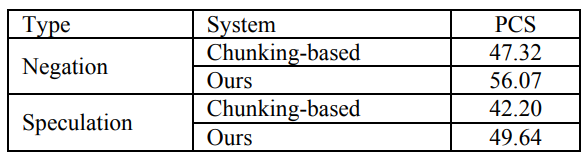
相比于传统分块预测,基于句法依赖树的方式对模型预测效果有显著改善:
2.7 后记补充
本文作者在后续基于CNeSp语料又进行了否定焦点的标注与baseline建立,并发表成论文。否定焦点指表述中最显著被否定的文本片段,从更细粒度上对文本中的肯定成分与否定成分进行了区分。
不同语境下的否定线索词所强调的语义是不同的,示例:
- 酒店不提供24小时热水,但出门左边有浴池提供
- 酒店不提供24小时热水,问了前台说要下午5点以后才有
- 酒店不提供24小时热水,仅能保证冷水供应
否定焦点的标注比CNeSp困难很多,最终的Kappa值(评价标注的一致性)在0.65~0.7之间,最终用BiLSTM-CRF构建baseline,整体准确率在61.21%左右。有关标注规范与模型结构的更多细节请参阅论文-汉语否定焦点识别研究:数据集与基线系统