中文标题:DKPLM_知识增强分解式预训练模型
英文标题:DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding
发布平台:AAAI
Proceedings of the AAAI Conference on Artificial Intelligence
发布日期:2022-06-28
引用量(非实时):7
DOI:10.1609/aaai.v36i10.21425
作者:Taolin Zhang, Chengyu Wang, Nan Hu, Minghui Qiu, Chengguang Tang, Xiaofeng He, Jun Huang
文章类型:journalArticle
品读时间:2022-09-01 09:47
1 文章萃取
1.1 核心观点
DKPLM模型针对长尾实体进行知识注入,减少运算量的同时避免了冗余信息的加入。通过构建特殊的”伪实体嵌入表示“模块和”知识关系编码“模块,使得知识图谱和文本语料可以共用一套基础解码器,再配合额外的关系解码任务,显式约束模型在预训练阶段完成知识注入,所以模型在微调和应用阶段不再需要额外的知识图谱以及知识解码器,在加快了模型运算的同时还保证了较好的精度
1.2 综合评价
- DKPLM模型的最大特点是预训练好后的模型在微调和应用阶段不再需要额外的知识图谱以及知识解码器,同时在性能和效率上取得了更优秀的表现
- DKPLM模型仅筛选了长尾实体进行知识注入,同时为了应对实体过多的特点,在计算softmax损失和负采样过程中都进行了抽样策略,难免存在一定的信息损失
- 论文中的部分细节描述略有模糊,但实验分析阶段比较全面。团队在HuggingFace上开源了模型,但个人使用了其中一个医疗领域版本的预训练模型,在CBLUE(医学NLP基准模型)上的实测效果不太好。可能是因为医疗类知识图噪声太多了?
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
传统大规模预训练模型(PLM)能深入理解文本的内部知识,但很难理解外部知识或常识,通过注入外部知识构成的三元组能增强预训练模型的性能,这被称为知识增强预训练模型(KEPLM)
常见的知识注入方法可以分为知识嵌入和联合学习:
- 知识嵌入:通过算法(比如TransE)将知识三元组转化为嵌入表示,之后需要并借助特征融合模块转化为上下文表示
- 联合学习:在预训练阶段,联合学习知识的嵌入表示,无需额外的特征融合过程
传统知识注入的问题:
- 针对所有实体注入知识,可能引入冗余信息
- 需要知识编码器的输出,在微调和推理阶段也需要知识图谱的配合
过往的多项研究表明,目前的非知识增强型语义模型已经能够在预训练阶段捕捉并表达一部分(高频和通用的)知识三元组语义
本文提出的DKPLM框架在知识注入时会通过筛选长尾实体(低频和非通用的)的方式来更谨慎的选择需要知识注入的实体,并且通过构建”伪实体嵌入表示“模块和”知识关系编码“模块,使得模型在微调和推理阶段不需要额外的知识图谱以及知识编码器
2.2 模型细节
模型的输入词元:${w_1,w_2,...,w_n}$
模型的隐藏层输出(词元的嵌入表示):${h_1,...,h_n}$
知识图谱:$G=(E,R)$,其中$E$和$R$分别表示实体和实体间的关系
知识三元组:$(e_h,r,e_t)$,其中符号分别表示头实体、实体关系、尾实体
自注意力池化:使用self-attention的方法来替换原本的最大池化操作
- 自注意力池化机制最初是用于将词向量联合转化为句向量的方法
- 将词元的嵌入表示按顺序进行拼接,得到句子的矩阵形式表示$H=[h_1,..,h_n]$
- 通过以下变化计算句子中每个词元的权重:$A=softmax(W_2tanh(W_1H^T))$
- 最终的句子嵌入表示为词元的加权求和$M=AH$,更多细节可参阅论文原文
模型的整体结构如下所示:
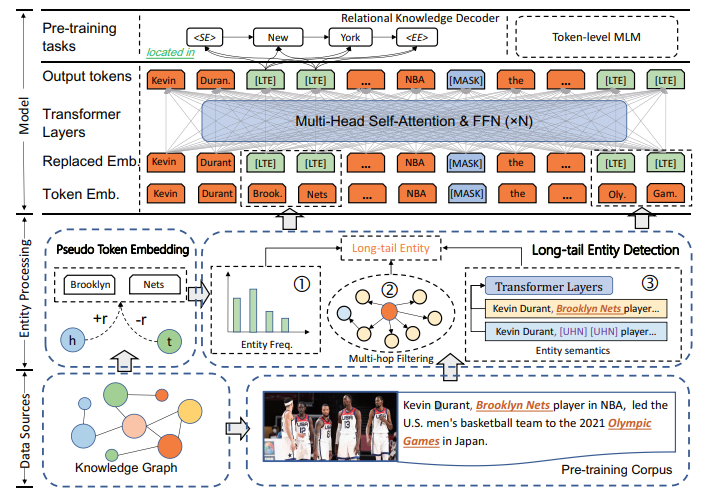
- 模型的输入主要包括知识图谱和预训练语料
- 模型训练前需要进行实体的预处理,主要包括“长尾实体检测”模块和“伪实体嵌入表示”模块,前者用于筛选出长尾实体,后者则是将长尾实体替换为包含知识信息的”伪实体“
- 模型的主要骨干可以是任意的成熟网络结构,本文采用RoBERTa作为backbone
- 在预训练过程中,除了传统BERT的MLM(随机遮盖预测)任务,还增加了”知识关系编码“模块,通过三元组的预测任务显式约束知识的注入过程
2.2.1 长尾实体检测
“长尾实体检测( Long-tail Entity Detection)”模块:
- 实体检测主要考虑三个指标:实体$e$的词频$Freq(e)$、实体$e$在句子中的重要性Semantic Importance,$SI(e)$、实体在知识图谱中的连通性 Knowledge Connectivity,$KC(e)$
- $SI(e)=\frac{|h_o^T|\cdot |h_{rep}|}{h_o^T\cdot h_{rep}}$,其中$h_o$表示原始的句子嵌入表示,$h_{rep}$表示用特殊词元
<UHN>替代实体后的句子嵌入表示。$SI(e)$其实描述的其实是两个句向量的余弦相似度的倒数,相似度越高,表明实体对于句子来说越不重要,$SI$值也就越低 - $KC(e)$对应的是实体在知识图谱的多跳相邻实体数
- 最终可以得到基于知识感知的实体长尾评估指标(knowledge-aware long-tailness)$KLT(e)=I_{{Freq(e)<R_{freq}}}\cdot SI(e) \cdot KC(e)$,其中$I$表示指示函数(元素在集合内返回1,否则返回0),$R_{freq}$是一个用于过滤高频实体的阈值
- 最终筛选的长尾实体是那些$KLT$值低于平均$KLT$值的实体
2.2.2 伪实体嵌入表示
“伪实体嵌入表示( Pseudo Token Embedding Injection)”模块:
- 原始语料和知识图谱将共用底层PLM模型的编码器作用,本模块主要的作用是将检测到的长尾实体替换为“伪实体“,”伪实体“主要由两部分组成。
- 首先,通过关系实体和尾实体的嵌入表示,得到头实体的嵌入表示:$h_{e_t}-h_r$
- 其次是根据实体的上下文描述$e_h^{des}$,得到头实体的另一种嵌入表示:$MLP(e_h^{des})$
- 汇总以上情况,得到"伪实体"的嵌入表示:$h_{eh}=tanh((h_{e_t}-h_r)\oplus MLP(e_h^{des}))W_{eh}$。其中$\oplus$表示拼接操作,$W_{eh}$为可训练参数
“伪实体嵌入表示”模块中以头实体为例进行了说明,其实尾实体也是适用的,只是需要将对关系实体的减法操作替换为加法操作。同时细心的读者可能注意到这里还遗留了两个问题,那就是”关系实体和尾实体的嵌入表示是怎么得出的?“以及”怎样确保编码器的输出能融合到注入的知识“,而这就引出了本模型的最后一个模块
2.2.3 知识关系编码
”知识关系编码(Relational Knowledge Decodin)“模块
- 本模块的结构是一个自注意力池化层+线性层+层归一化,本模块后面衔接了一个编码预测任务,显式约束模型在预训练阶段将注入知识融合到最终的嵌入表示中
- 关系实体和尾实体的嵌入表示计算过程如下:$h_r=LN(\sigma(f_{sp}(MLP(r))W_r))$,$h_{e_t}=LN(\sigma(f_{sp}(MLP(e_t))W_{e_t}))$。其中$LN$表示层归一化,$f_{sp}$表示自注意力池化
- 上一个模块得到的”伪实体“嵌入表示也会进行转化:$h^o_{e_h}=LN(\sigma(f_{sp}MLP(h_{e_h})W_r))$。需要注意的是$MLP$的原始输入是$e_h$,但在嵌入层会直接用$h_{e_h}$进行替换
- 以$e_h$为第一个头实体,对应的最终嵌入表示为$h^0_{d}=h^o_{e_h}$,以$r_0$为实体关系,对应的最终嵌入表示为$h_{r_0}$,则此时对应尾实体的推断嵌入表示为$tanh(\delta_d h_{r_0} h^0_d\cdot W_d)$,其中$\delta_d$为缩放因子,$W_d$为可训练参数
- 把推测得到的尾实体作为新的头实体,重复上一步$i$次,此时得到第$i$个尾实体的推断嵌入表示为:$h^i_d=tanh(\delta_d h_{r_i} h^{i-1}_d\cdot W_d)$。所以这是一个序列化的解码预测过程
- 假设第$i$次尾实体推断对应的真实嵌入表示是$y_i$,则第$i$次解码预测对应的损失函数:
$$L_{d_i}=\frac{exp(f_s(h^i_d,y_i))}{exp(f_s(h^i_d,y_i))+NE_{t_n\sim Q(y_n|y_t)}[exp(f_s(h^i_d,y_n))]}$$ 其中$f_s(h^i_d,y_i)=(h^i_d)^T\cdot y_i-log(Q(t|t_i))$,$Q$表示负采样过程,$y_n$是负样本,$N$为负采样数量,$E$表示均值。还需要注意以上公式计算的只是第$i$次预测的损失函数,最终解码预测任务的损失函数$L_{De}$会是序列化预测的损失的和。
由于实体数量过多,所以此处的softmax损失函数进行了采样优化,同时在负采样阶段,也会先通过PEPR排序算法(借鉴了PageRank的算法思想)筛选排序靠前的实体用于生成负采样 。关于Sampled SoftMax和PEPR排序的更多细节,可参阅该团队之前发表过的一篇论文的相关笔记——SMedBERT_医学语义知识增强型预训练模型
DKPLM模型最终的损失函数:$L_{total}=\lambda_1 L_{MLM}+(1-\lambda)L_{De}$,其中$\lambda_1$是超参数
2.3 实验分析
本文使用英文维基百科(2022-03-01版)作为语料数据,数据的下载和处理借助了第三方工具 WikiExtractor。知识图谱使用WikiData5M,一个拥有对齐语料库的百万级知识图数据集。并通过实体对齐工具TagMe将语料与知识图对齐。
最终数据的实体数约有208.5w个,关系类型822种,训练语料2600w条。模型训练使用8块V100-16G的显卡,训练时长约12小时
不进行微调的零样本(zero-shot)文本理解任务(类似于完形填空):
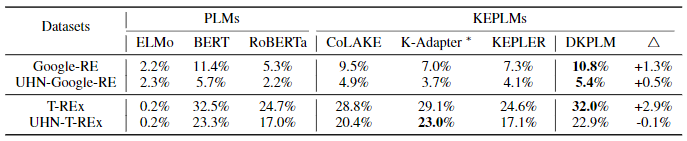
- 主要依赖的测试数据集为Google-RE和T-REx
- 前缀UHN表示去除部分易回答问题的版本
- K-Adapter训练集包含T-REx的子集,对比结果存在数据泄露问题
- DKPLM模型针对零样本任务存在显著优势(表中指标为平均准确率)
进行微调的命名实体识别(NER)任务:
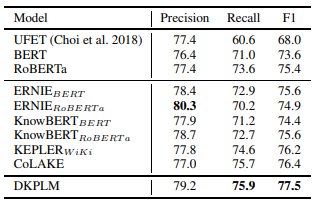
- 使用NER基准测试数据Open Entity作为测试集
- DKPLM模型结果综合来看略有优势
进行微调的关系抽取(RE)任务:
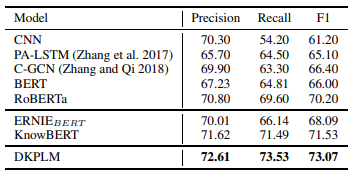
- 使用RE基准测试数据TACRED作为测试集
- DKPLM模型结果综合来看略有优势
不同模型的耗时对比:
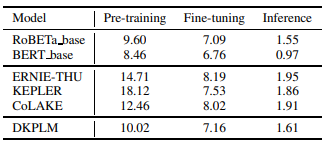
- 比非知识增强型模型慢,但比其他知识增强型模型快
注入不同类型实体的性能改善趋势(长尾VS高频VS混合方法):
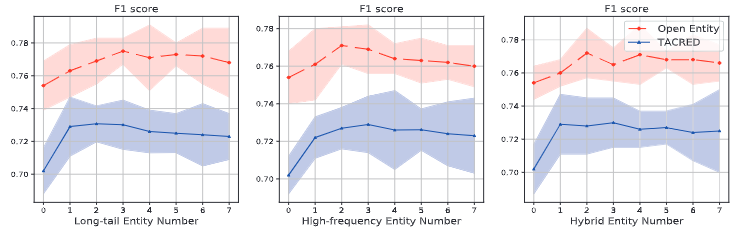
- 长尾实体的改善效果优于高频实体
- 随着实体数的增加,知识的冗余会导致模型效果降低
DKPLM消融实验:
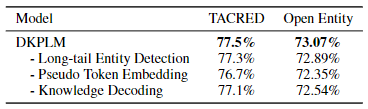
- 不同模块的提升效果比
相关资源
- 在线论文
- 预训练模型文件-医疗领域
- 预训练模型文件-金融领域
- 模型代码 :已集成在Pai团队开源的NLP工具库-EasyNLP中
- 本地文件地址:2022_DKPLM_Zhang et al.pdf
- 本地Zotero地址:2022_DKPLM_Zhang et al.pdf