任务目标
- 实战:python爬取金融数据
- 实战2: 利用python进行金融数据处理:数据清洗,数据可视化,特征提取,etc.
- 实战3:你的第一个基于机器学习的量化模型(yay)
1 数据
金融数据源
存储方式:csv、sql、nosql
数据格式
- 交易所信息
- 数据来源
- Ticker/symbol
- 价格
- 企业行为(stock splits/dividend adjustments)
- 国家假日
数据的注意点
- 企业行为
- 数据峰值
- 数据缺失
2 MySQL
四个基本表:
- Exchange 交易所基本信息表
CREATE TABLE `exchange` (
id int NOT NULL AUTO_INCREMENT,
abbrev varchar(32) NOT NULL,
name varchar(255) NOT NULL,
city varchar(255) NULL,
country varchar(255) NULL,
currency varchar(64) NULL,
timezone_offset time NULL,
created_date datetime NOT NULL,
last_updated_date datetime NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- DataVendor 数据来源表 ```sql CREATE TABLE `data_vendor` (
id int NOT NULL AUTO_INCREMENT,
name varchar(64) NOT NULL,
website_url varchar(255) NULL,
support_email varchar(255) NULL,
created_date datetime NOT NULL,
last_updated_date datetime NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- Symbol 股票代码与基本信息 ```SQL CREATE TABLE `symbol` (
id int NOT NULL AUTO_INCREMENT,
exchange_id int NULL,
ticker varchar(32) NOT NULL,
instrument varchar(64) NOT NULL,
name varchar(255) NULL,
sector varchar(255) NULL,
currency varchar(32) NULL,
created_date datetime NOT NULL,
last_updated_date datetime NOT NULL,
PRIMARY KEY (id),
KEY index_exchange_id (exchange_id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- DailyPrice 每日价格表 ```sql CREATE TABLE `daily_price` (
id int NOT NULL AUTO_INCREMENT,
data_vendor_id int NOT NULL,
symbol_id int NOT NULL,
price_date datetime NOT NULL,
created_date datetime NOT NULL,
last_updated_date datetime NOT NULL,
open_price decimal(19,4) NULL,
high_price decimal(19,4) NULL,
low_price decimal(19,4) NULL,
close_price decimal(19,4) NULL,
adj_close_price decimal(19,4) NULL,
volume bigint NULL,
PRIMARY KEY (id),
KEY index_data_vendor_id (data_vendor_id),
KEY index_symbol_id (symbol_id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
打通MySQL和python:
sudo apt-get install libmysqlclient-dev pip install mysqlclient
3 数据爬取
3.1 代码解析
- 前往wiki页面获取标普500的企业列表(
obtain_parse_wiki_snp500),并存储到mysql(insert_snp500_symbols)。
def obtain_parse_wiki_snp500():
# Download and parse the Wikipedia list of S&P500
# constituents using requests and BeautifulSoup.
# Returns a list of tuples for to add to MySQL.
# Stores the current time, for the created_at record
now = datetime.datetime.utcnow()
# Use requests and BeautifulSoup to download the
# list of S&P500 companies and obtain the symbol table
response = requests.get(
"http://en.wikipedia.org/wiki/List_of_S%26P_500_companies"
)
soup = bs4.BeautifulSoup(response.text)
# This selects the first table, using CSS Selector syntax
# and then ignores the header row ([1:])
symbolslist = soup.select('table')[0].select('tr')[1:]
# Obtain the symbol information for each
# row in the S&P500 constituent table
symbols = []
for i, symbol in enumerate(symbolslist):
tds = symbol.select('td')
symbols.append(
(
tds[0].select('a')[0].text, # Ticker
'stock',
tds[1].select('a')[0].text, # Name
tds[3].text, # Sector
'USD', now, now
)
)
return symbols
def insert_snp500_symbols(symbols):
"""
Insert the S&P500 symbols into the MySQL database.
"""
# Connect to the MySQL instance
db_host = 'localhost'
db_user = 'sec_user'
db_pass = 'password'
db_name = 'securities_master'
con = mdb.connect(
host=db_host, user=db_user, passwd=db_pass, db=db_name
)
# Create the insert strings
column_str = """ticker, instrument, name, sector,
currency, created_date, last_updated_date
"""
insert_str = ("%s, " * 7)[:-2]
final_str = "INSERT INTO symbol (%s) VALUES (%s)" % \
(column_str, insert_str)
# Using the MySQL connection, carry out
# an INSERT INTO for every symbol
with con:
cur = con.cursor()
cur.executemany(final_str, symbols)
- 根据读取得到的企业列表(
obtain_list_of_db_tickers),逐一前往爬取雅虎金融抓取每日数据(get_daily_historic_data_yahoo),并存储到MySQL中(insert_daily_data_into_db)。
def obtain_list_of_db_tickers():
"""
Obtains a list of the ticker symbols in the database.
"""
with con:
cur = con.cursor()
cur.execute("SELECT id, ticker FROM symbol")
data = cur.fetchall()
return [(d[0], d[1]) for d in data]
def get_daily_historic_data_yahoo(
ticker, start_date=(2000,1,1),
end_date=datetime.date.today().timetuple()[0:3]
):
"""
Obtains data from Yahoo Finance returns and a list of tuples.
ticker: Yahoo Finance ticker symbol, e.g. "GOOG" for Google, Inc.
start_date: Start date in (YYYY, M, D) format
end_date: End date in (YYYY, M, D) format
"""
# Construct the Yahoo URL with the correct integer query parameters
# for start and end dates. Note that some parameters are zero-based!
ticker_tup = (
ticker, start_date[1]-1, start_date[2],
start_date[0], end_date[1]-1, end_date[2],
end_date[0]
)
yahoo_url = "http://ichart.finance.yahoo.com/table.csv"
yahoo_url += "?s=%s&a=%s&b=%s&c=%s&d=%s&e=%s&f=%s"
yahoo_url = yahoo_url % ticker_tup
# Try connecting to Yahoo Finance and obtaining the data
# On failure, print an error message.
try:
yf_data = requests.get(yahoo_url).text.split("\n")[1:-1]
prices = []
for y in yf_data:
p = y.strip().split(',')
prices.append(
(datetime.datetime.strptime(p[0], '%Y-%m-%d'),
p[1], p[2], p[3], p[4], p[5], p[6])
)
except Exception as e:
print("Could not download Yahoo data: %s" % e)
return prices
def insert_daily_data_into_db(
data_vendor_id, symbol_id, daily_data
):
"""
Takes a list of tuples of daily data and adds it to the
MySQL database. Appends the vendor ID and symbol ID to the data.
daily_data: List of tuples of the OHLC data (with
adj_close and volume)
"""
# Create the time now
now = datetime.datetime.utcnow()
# Amend the data to include the vendor ID and symbol ID
daily_data = [
(data_vendor_id, symbol_id, d[0], now, now,
d[1], d[2], d[3], d[4], d[5], d[6])
for d in daily_data
]
# Create the insert strings
column_str = """data_vendor_id, symbol_id, price_date, created_date,
last_updated_date, open_price, high_price, low_price,
close_price, volume, adj_close_price"""
insert_str = ("%s, " * 11)[:-2]
final_str = "INSERT INTO daily_price (%s) VALUES (%s)" % \
(column_str, insert_str)
# Using the MySQL connection, carry out an INSERT INTO for every symbol
with con:
cur = con.cursor()
cur.executemany(final_str, daily_data)
3.2 其他注意点
pandas直接读取网页
- 有更丰富的宏微观数据
- 注册可以获取更多的api调用次数
- 相关代码可以查看第三课时对应的
quandl_data.py文件
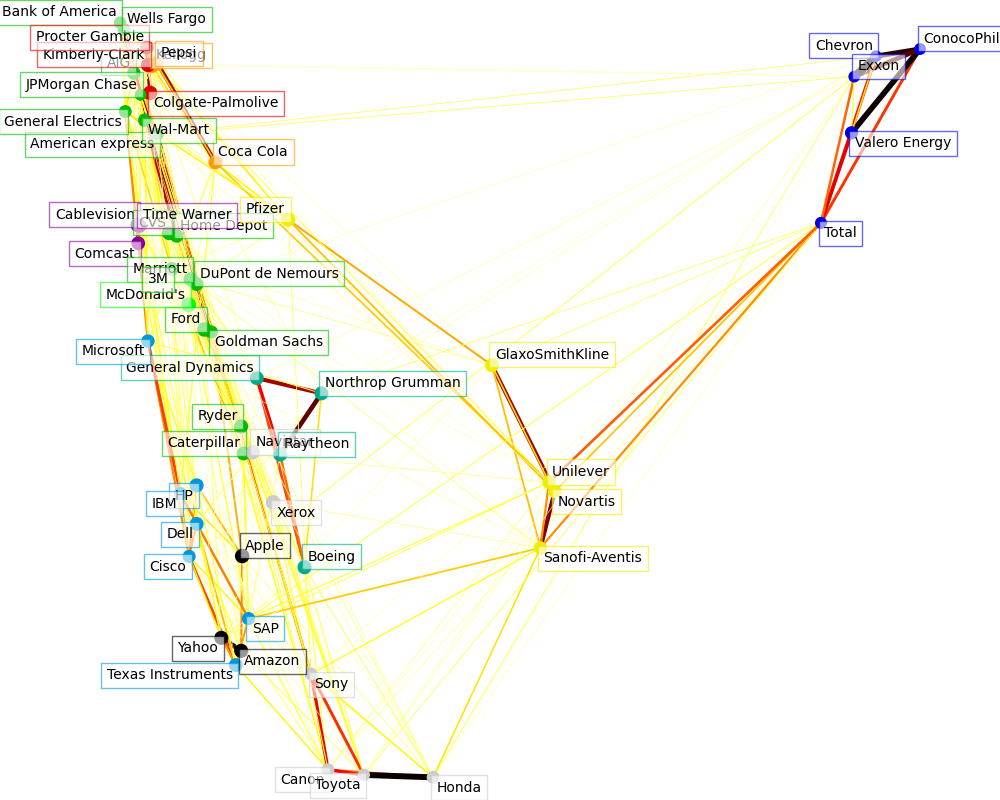
4 案例:沪深300聚类与降维可视化
Visualizing the stock market structure — scikit-learn 0.24.2 documentation
主要流程
- 读取存储在github上的示例数据,并计算开盘价与收盘价的差值
- 对数据进行标准化,并进行基于LARS(最小角回归)的Lasso回归建模
- 对结果通过1_study/algorithm/数据降维算法/局部线性嵌入 LLE进行算法降维
- 将降维后的数据以及聚类结果进行绘图展示
5 时间序列分析
OU(Ornstein-Uhlenbeck)过程(又被称为奥恩斯坦-乌伦贝克过程)
检验时间序列平稳性的常见两种方法,ADF Test 和 Hurst Exponent
平稳性检验方法实战:
- ADF检验直接采用statsmodels库中的现有函数来实现
import statsmodels.tsa.stattools as ts # Calculate and output the CADF test on the residuals cadf = ts.adfuller(df["res"])
- 赫斯特指数的计算比较简单,基础函数就能搞定
from numpy import cumsum, log, polyfit, sqrt, std, subtract from numpy.random import randn def hurst(ts): """Returns the Hurst Exponent of the time series vector ts""" # Create the range of lag values lags = range(2, 100) # Calculate the array of the variances of the lagged differences tau = [sqrt(std(subtract(ts[lag:], ts[:-lag]))) for lag in lags] # Use a linear fit to estimate the Hurst Exponent poly = polyfit(log(lags), log(tau), 1) # Return the Hurst exponent from the polyfit output return poly[0]*2.0