1 深度卷积网络(AlexNet)
1.1 背景与蓄势
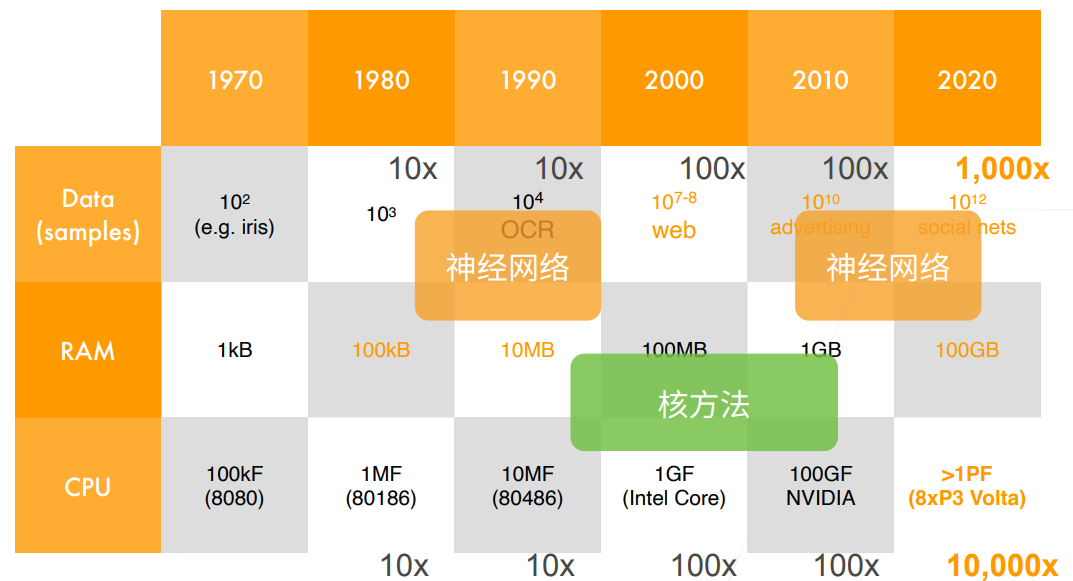
LeCun提出的卷积神经网络在计算机视觉和机器学习领域中很有名气,但大多数情况下仍打不过同期的优等生核技巧(SVM)。而在2012前,计算机视觉的手工图像特征提取方法红极一时,诞生了诸如SIFT算法、SURF(加速鲁棒特征)、HOG(定向梯度直方图)之类的优质特征提取方法
而另一组研究员(全明星阵容:Geoff Hinton、Yann LeCun、Yoshua Bengio、Andrew Ng、Shun ichi Amari和Juergen Schmidhuber(发明了LSTM)),则认为特征本身应该被学习,在合理地复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。
2012年深度学习兴起的两个铺垫
- 数据的完善:2009年,ImageNet数据集发布(120w样本,1000类别)
- 计算的支持:深度神经网络计算在GPU上的并行加速
1.2 AlexNet简述
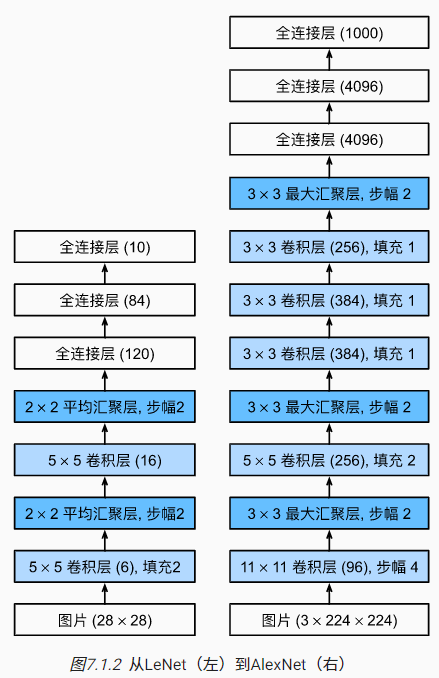
AlexNet由八层组成(五个卷积层、三个全连接层),使用ReLu作为激活函数(LeNet是Sigmoid),使用Dropout控制模型复杂度(LeNet只使用了权重衰减),还通过各种技巧(翻转、裁切和变色)进行了数据增强
两个4096维的全连接隐藏层拥有接近1GB的模型参数,受限于早期显存限制,原始模型还进行了跨GPU分解,上图对此进行了简化与忽略(毕竟现在显存够用了)
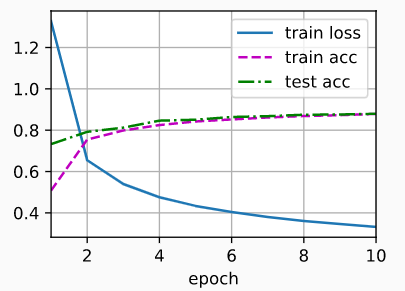
最终AlexNet参加2012年的ImageNet大赛,达到最低的15.3%的Top-5错误率,比第二名低10.8个百分点。最终成为计算机视觉领域最有影响力的模型之一,也在科研界掀起了对深度神经网络研究的热潮
1.3 代码实现与训练
PyTorch版本:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
#loss 0.327, train acc 0.881, test acc 0.882
#3910.3 examples/sec on cuda:0
Tensorflow版本:
import tensorflow as tf
from d2l import tensorflow as d2l
def net():
return tf.keras.models.Sequential([
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
tf.keras.layers.Conv2D(filters=96, kernel_size=11, strides=4,
activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
tf.keras.layers.Conv2D(filters=256, kernel_size=5, padding='same',
activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
tf.keras.layers.Conv2D(filters=384, kernel_size=3, padding='same',
activation='relu'),
tf.keras.layers.Conv2D(filters=384, kernel_size=3, padding='same',
activation='relu'),
tf.keras.layers.Conv2D(filters=256, kernel_size=3, padding='same',
activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
tf.keras.layers.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dropout(0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
tf.keras.layers.Dense(10)
])
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
#loss 0.332, train acc 0.879, test acc 0.880
#4114.8 examples/sec on /GPU:0
2 使用块的网络(VGG)
2.1 VGG简述
随着深度的增加,神经网络的层开始逐渐出现重复的情况。类似于面向对象编程的常见思想,研究人员自然而然地开始将重复层进行抽象与封装,形成了块的抽象。不同次数的重复块可以得到不同的架构,比如VGG-16或VGG-19
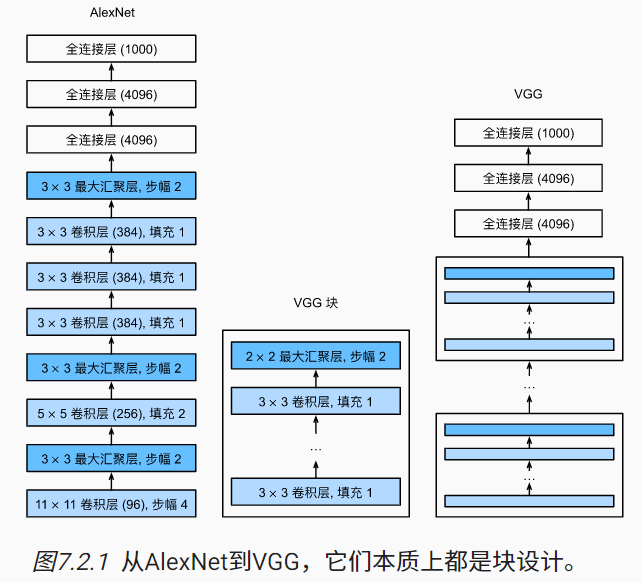
原始VGG网络有8个卷积层和3个全连接层,其中8个卷积层抽象成了5个卷积块(对应卷积层数分别为1,1,2,2,2,每个卷积块的输出通道分别为64,128,256,512,512),而全连接模块则与AlexNet中的相同。
在VGG论文中,Simonyan和Ziserman尝试了各种架构,并发现深层且窄的卷积(即3×3)比较浅层且宽的卷积更有效,所以用连续的$3\times3$的卷积核替代了AlexNet中较大的卷积核。
2.2 代码实现与训练
PyTorch版本:
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
ratio = 4
# 考虑到计算量,进行网络的简化
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
#loss 0.179, train acc 0.934, test acc 0.918
#2465.6 examples/sec on cuda:0
Tensorflow版本:
import tensorflow as tf
from d2l import tensorflow as d2l
def vgg_block(num_convs, num_channels):
blk = tf.keras.models.Sequential()
for _ in range(num_convs):
blk.add(tf.keras.layers.Conv2D(num_channels,kernel_size=3,
padding='same',activation='relu'))
blk.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))
return blk
def vgg(conv_arch):
net = tf.keras.models.Sequential()
# 卷积层部分
for (num_convs, num_channels) in conv_arch:
net.add(vgg_block(num_convs, num_channels))
# 全连接层部分
net.add(tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10)]))
return net
net = vgg(conv_arch)
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
# 回想一下,这必须是一个将被放入“d2l.train_ch6()”的函数,为了利用我们现有的CPU/GPU设备,这样模型构建/编译需要在strategy.scope()中
net = lambda: vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
#loss 0.177, train acc 0.934, test acc 0.921
#2614.6 examples/sec on /GPU:0
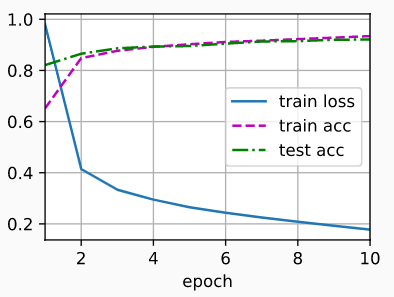
3 网络中的网络(NiN)
3.1 NiN简述
VGG、AlexNet的最后几个全连接层能无缝衔接卷积层,并且能对卷积层抽取到的特征实现更抽象的表示,但是这些全连接层参数量爆炸,并且容易过拟合。所以NiN网络提出了一种用多个1X1卷积层替代全连接层的新颖方法。
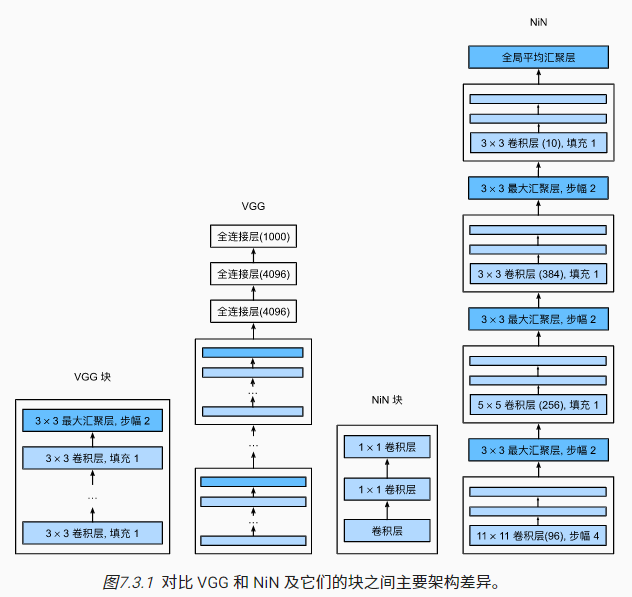
NiN网络用多个NiN块(原始论文中称之为MlPconv)替代了原始的卷积块+MLP(多层感知器)的结构,其中每个MlPconv其实就是在常规卷积后面加了N层1X1卷积
为什么1X1卷积能替代全连接层
- 二者从数学计算的角度都是加权求和的过程
- 每个1X1卷积相当于在每个像素的不同通道间建立全连接层
- 同一个1X1卷积在不同像素点计算时权重共享,所以参数量大幅减少
- 两个1X1卷积叠加相比于单个1X1卷积,非线性拟合能力会更强
1X1卷积的好处
- 增加模型的非线性拟合能力(特征抽象能力)
- 方便升维、降维(增加或减少1X1卷积的通道数)
- 实现跨通道特征融合/信息交流
NiN网络最后使用了全局平均池化层+softmax,将特征图与类别直接关联,模型的可解释性强,并且参数量少,不容易过拟合,但是收敛会较慢~
3.2 代码实现与训练
PyTorch版本:
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
#loss 0.369, train acc 0.861, test acc 0.869
#3079.7 examples/sec on cuda:0
Tensorflow版本:
import tensorflow as tf
from d2l import tensorflow as d2l
def nin_block(num_channels, kernel_size, strides, padding):
return tf.keras.models.Sequential([
tf.keras.layers.Conv2D(num_channels, kernel_size, strides=strides,
padding=padding, activation='relu'),
tf.keras.layers.Conv2D(num_channels, kernel_size=1,
activation='relu'),
tf.keras.layers.Conv2D(num_channels, kernel_size=1,
activation='relu')])
def net():
return tf.keras.models.Sequential([
nin_block(96, kernel_size=11, strides=4, padding='valid'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
nin_block(256, kernel_size=5, strides=1, padding='same'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
nin_block(384, kernel_size=3, strides=1, padding='same'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2),
tf.keras.layers.Dropout(0.5),
# 标签类别数是10
nin_block(10, kernel_size=3, strides=1, padding='same'),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Reshape((1, 1, 10)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
tf.keras.layers.Flatten(),
])
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
#loss 0.422, train acc 0.843, test acc 0.833
#3127.0 examples/sec on /GPU:0
4 含并行连结的网络(GoogLeNet)
4.1 GoogLeNet简述
第一个卷积层数超过100的网络,夺得了2014年ImageNet竞赛的冠军。GoogLeNet(又称Inception网络)吸收了之前网络的长处,并提出Inception块,用于组合不同大小的卷积核,以一种结构化的方式来捕捉不同尺寸的信息:
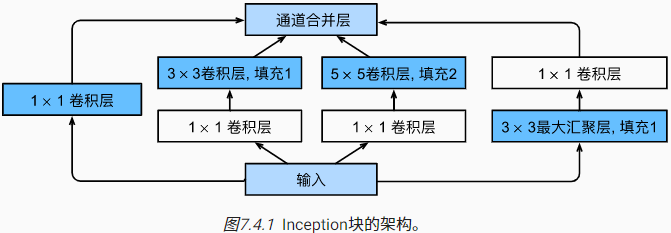
Inception 块特点:
- Inception 块由四条并行路径组成
- 不同路径间提取的信息尺寸不同
- 1X1卷积层通过控制通道数降低模型复杂度
- 不同大小的卷积核通过合适的填充保持输入输出维度一致
- 不同Inception 块直接通过最大池化层降低维度
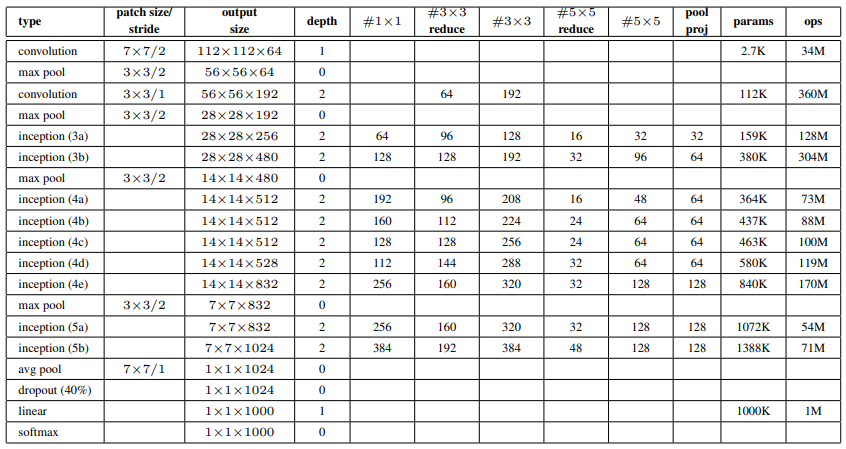
GoogLeNet由9个Inception块和其他常见层组成,为方便理解划分为以下五个部分:
- 由64通道7X7卷积层+3X3最大池化层组成
- 由64通道1X1卷积层+192通道3X3卷积层+3X3最大池化层组成
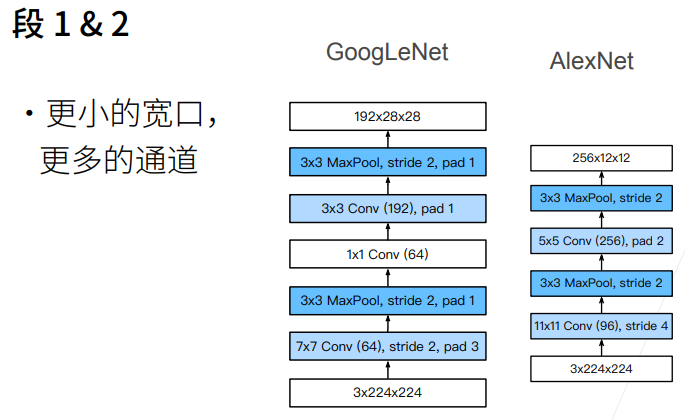 3. 由2个串联的Inception块+3X3最大池化层组成,两个Inception块的输出通道数分别为(64,128,32,32)和(128,192,96,64)
3. 由2个串联的Inception块+3X3最大池化层组成,两个Inception块的输出通道数分别为(64,128,32,32)和(128,192,96,64)
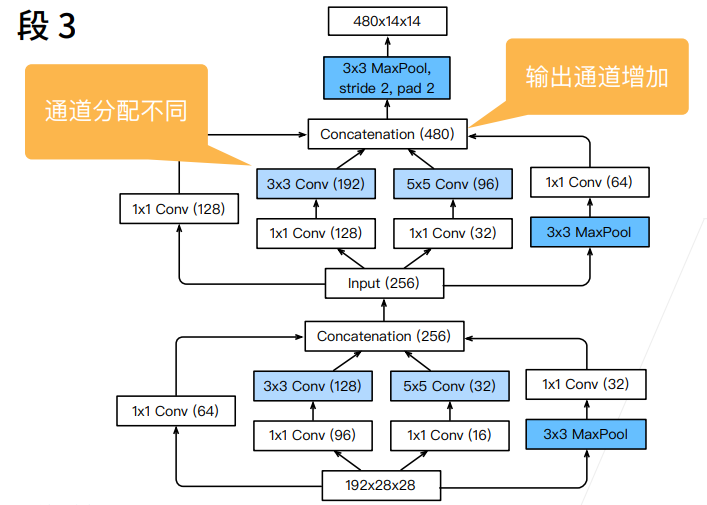 4. 由5个串联的Inception块+3X3池化层组成,五个Inception块的输出通道数分别为(192,208,48,64),(160,224,64,64),(128,256,64,64),(112,288,64,64)和(256,320,128,128)
5. 由2个串联的Inception块+7X7平均池化层+全连接层组成,两个Inception块的输出通道数分别为(256,320,128,128)和(384,384,128,128)
4. 由5个串联的Inception块+3X3池化层组成,五个Inception块的输出通道数分别为(192,208,48,64),(160,224,64,64),(128,256,64,64),(112,288,64,64)和(256,320,128,128)
5. 由2个串联的Inception块+7X7平均池化层+全连接层组成,两个Inception块的输出通道数分别为(256,320,128,128)和(384,384,128,128)
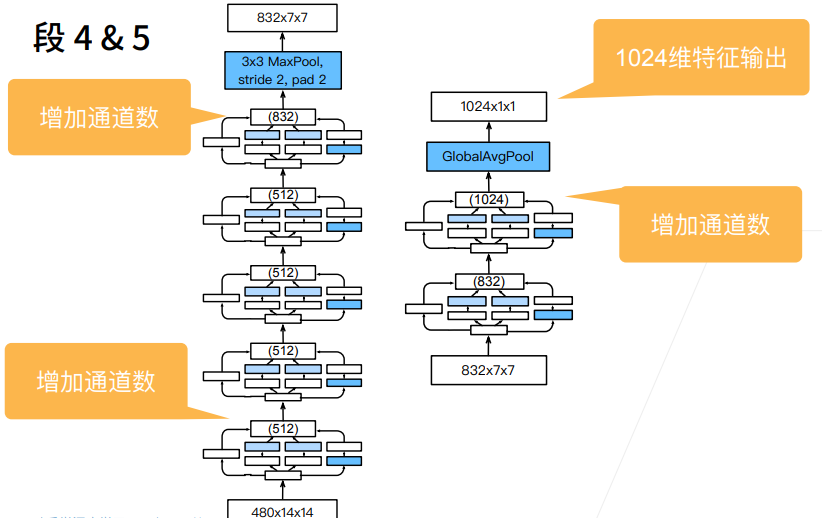
整体网络结构及其输入输出维度总结如下(图中遗漏了第二部分的1X1卷积层):
4.2 代码实现与训练
PyTorch版本:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# loss 0.246, train acc 0.905, test acc 0.895
# 3493.3 examples/sec on cuda:0
Tensorflow版本:
import tensorflow as tf
from d2l import tensorflow as d2l
class Inception(tf.keras.Model):
# c1--c4是每条路径的输出通道数
def __init__(self, c1, c2, c3, c4):
super().__init__()
# 线路1,单1x1卷积层
self.p1_1 = tf.keras.layers.Conv2D(c1, 1, activation='relu')
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = tf.keras.layers.Conv2D(c2[0], 1, activation='relu')
self.p2_2 = tf.keras.layers.Conv2D(c2[1], 3, padding='same',
activation='relu')
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = tf.keras.layers.Conv2D(c3[0], 1, activation='relu')
self.p3_2 = tf.keras.layers.Conv2D(c3[1], 5, padding='same',
activation='relu')
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = tf.keras.layers.MaxPool2D(3, 1, padding='same')
self.p4_2 = tf.keras.layers.Conv2D(c4, 1, activation='relu')
def call(self, x):
p1 = self.p1_1(x)
p2 = self.p2_2(self.p2_1(x))
p3 = self.p3_2(self.p3_1(x))
p4 = self.p4_2(self.p4_1(x))
# 在通道维度上连结输出
return tf.keras.layers.Concatenate()([p1, p2, p3, p4])
def b1():
return tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, 7, strides=2, padding='same',
activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')])
def b2():
return tf.keras.Sequential([
tf.keras.layers.Conv2D(64, 1, activation='relu'),
tf.keras.layers.Conv2D(192, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')])
def b3():
return tf.keras.models.Sequential([
Inception(64, (96, 128), (16, 32), 32),
Inception(128, (128, 192), (32, 96), 64),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')])
def b4():
return tf.keras.Sequential([
Inception(192, (96, 208), (16, 48), 64),
Inception(160, (112, 224), (24, 64), 64),
Inception(128, (128, 256), (24, 64), 64),
Inception(112, (144, 288), (32, 64), 64),
Inception(256, (160, 320), (32, 128), 128),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')])
def b5():
return tf.keras.Sequential([
Inception(256, (160, 320), (32, 128), 128),
Inception(384, (192, 384), (48, 128), 128),
tf.keras.layers.GlobalAvgPool2D(),
tf.keras.layers.Flatten()
])
# “net”必须是一个将被传递给“d2l.train_ch6()”的函数。
# 为了利用我们现有的CPU/GPU设备,这样模型构建/编译需要在“strategy.scope()”
def net():
return tf.keras.Sequential([b1(), b2(), b3(), b4(), b5(),
tf.keras.layers.Dense(10)])
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
#loss 0.231, train acc 0.912, test acc 0.876
#3526.7 examples/sec on /GPU:0
4.3 Inception网络后续
Inception-v2又称Inception-BN,使用了批量规范化(Batch Normalization)的技巧
Inception-v3修改了Inception块,用多个低维卷积层替代高维卷积层,牺牲一定的模型精度大幅降低计算量,同时可以增加深度
Inception-v4使用了残差连接的技巧,目前v3和v4比较常用,但是人工痕迹严重(模型设计复杂,多为规模调参的结果,网络设计不漂亮)
5 批量规范化(Batch Normalization)
5.1 批量规范化简述
深层网络难以训练的原因:
- 数据输入的略微改动会对最终结果产生巨大影响
- 随着时间的推移,模型参数的随着训练更新变幻莫测
- 复杂的深度网络容易过拟合,需要正则约束
数据标准化预处理是一种常见的数据规整方案,考虑到神经网络的特殊性,可以针对每个小批次数据进行数据标准化,也可以针对某一层单独进行批量规范化
用$x\in B$表示一个来自小批量$B$的输入,批量规范化$BN$可表示如下:$$BN(x)=\gamma \odot\frac{x-\hat{u}_B}{\hat{\sigma}_B}+\beta$$ 其中$\hat{u}_B$表示小批量$B$的样本均值,$\hat{\sigma}_B$表示小批量$B$的样本标准差(实际计算时,注意添加一个小常数$\epsilon$,确保分母大于0),$\gamma$和$\beta$分别表示拉伸参数(scale)和便宜参数(shift),为可训练的参数
对于卷积层,假设每个小批量包含$m$个样本,卷积层输出包含$n$个通道,每个通道高度为$p$,宽度为$q$,批量规范化过程会覆盖每个输出通道里的$m\cdot q\cdot q$个元素
批量规范化的好处:
- 调整神经网络的中间输出,使其更稳定,缓解过拟合,最终建模效果更好
- 存在很多有益的副作用,比如加快收敛,正则化(能替代Dropout的作用)
- 缺少底层理论支持,可以理解为是一种对参数搜索空间的合理约束
批量规范化的原理修正:
- 原始论文中推测批量规范化减少了内部协变量转移,但这一说法被后续文章否定
- 李沐老师指出,后续有论文(未指明)指出批量规范化相当于在小批量添加随机偏移与缩放(相当于一个线性层)来控制模型的复杂度
- 评论区也有同学提及论文《How Does Batch Normalization Help Optimization?》认为BN能使得目标函数更平滑,从而加快模型的收敛速度
5.2 代码实现与训练
PyTorch版本:
import torch
from torch import nn
from d2l import torch as d2l
# 添加BN层的LeNet
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.Linear(84, 10))
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
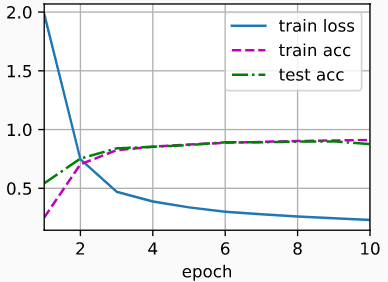
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# loss 0.265, train acc 0.902, test acc 0.876
# 56228.2 examples/sec on cuda:0
Tensorflow版本:
import tensorflow as tf
from d2l import tensorflow as d2l
# 添加BN层的LeNet
def net():
return tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6, kernel_size=5,
input_shape=(28, 28, 1)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('sigmoid'),
tf.keras.layers.AvgPool2D(pool_size=2, strides=2),
tf.keras.layers.Conv2D(filters=16, kernel_size=5),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('sigmoid'),
tf.keras.layers.AvgPool2D(pool_size=2, strides=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('sigmoid'),
tf.keras.layers.Dense(84),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('sigmoid'),
tf.keras.layers.Dense(10),
])
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# loss 0.271, train acc 0.899, test acc 0.850
# 41970.2 examples/sec on /GPU:0
以上代码为借助API的简明实现,自定义实现代码可参考书籍对应章节
6 残差网络(ResNet)
6.1 ResNet简述
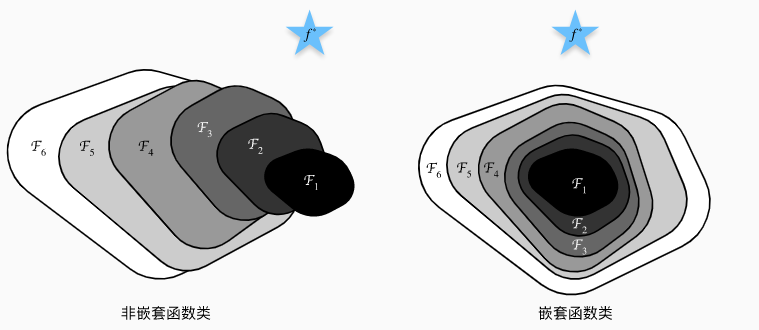
非嵌套函数类VS嵌套函数类
- 设最优理想模型为$f^*$,即图中蓝色五角星所示未知
- 模型的复杂度用面积表示,则从模型$F_1$到模型$F_6$,复杂度与面积依次递大
- 用面积内距离$f^*$最近的点描述模型的最优拟合结果
- 对于非嵌套函数类来说,模型$F_6$的最优拟合结果可能比模型$F_1$更差
- 对于嵌套函数类来说,模型$F_6$的最优拟合结果不可能比模型$F_1$更差
而残差网络(ResNet)的设计初衷就是尽可能地约束神经网络接近嵌套函数类,这样能保证随着层数的增加,神经网络的最优拟合结果不会更差。凭借这一思想构建出的残差块(residual block),ResNet赢得了2015年ImageNet大规模视觉识别挑战赛
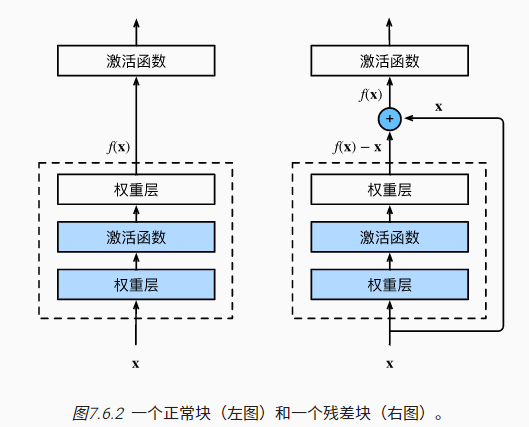
具体来说,ResNet沿用了VGG完整的3×3卷积层设计,并通过参数use_1x1conv控制,额外引入一个跨层数据通路,并借助1×1卷积层调整输出形状:
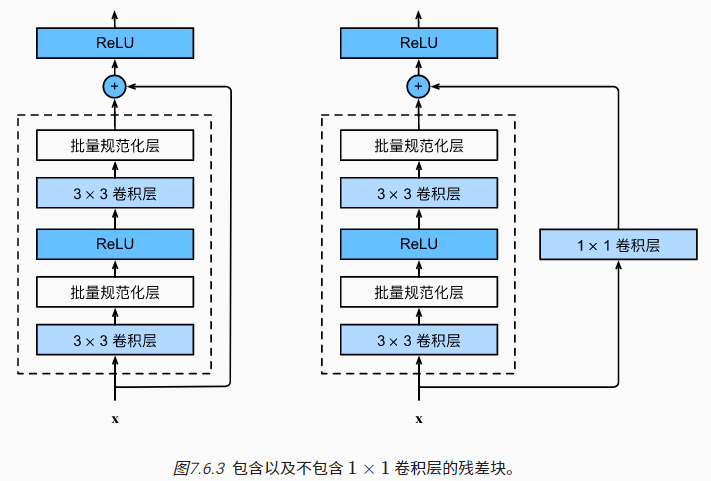
ResNet网络的前两层与之前介绍的GoogLeNet一致,之后的结构则是从四个Inception块组成的模块改为四个残差块组成的模块,这就是经典的ResNet-18。
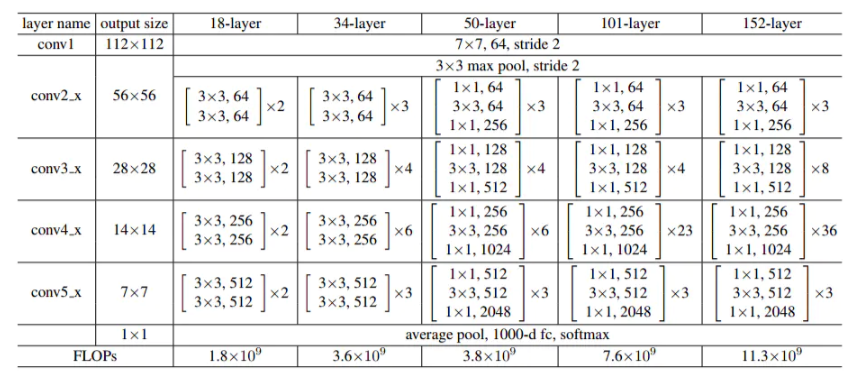
ResNet架构更简单,修改也更方便,通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如ResNet-50,甚至更深的含152层的ResNet-152:
6.2 代码实现与训练
PyTorch版本:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
# 前两层与之前介绍的GoogLeNet一致
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 设计残差块
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# loss 0.010, train acc 0.998, test acc 0.909
# 4619.4 examples/sec on cuda:0
Tensorflow版本:
import tensorflow as tf
from d2l import tensorflow as d2l
class Residual(tf.keras.Model): #@save
def __init__(self, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
num_channels, padding='same', kernel_size=3, strides=strides)
self.conv2 = tf.keras.layers.Conv2D(
num_channels, kernel_size=3, padding='same')
self.conv3 = None
if use_1x1conv:
self.conv3 = tf.keras.layers.Conv2D(
num_channels, kernel_size=1, strides=strides)
self.bn1 = tf.keras.layers.BatchNormalization()
self.bn2 = tf.keras.layers.BatchNormalization()
def call(self, X):
Y = tf.keras.activations.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3 is not None:
X = self.conv3(X)
Y += X
return tf.keras.activations.relu(Y)
# 前两层与之前介绍的GoogLeNet一致
b1 = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')])
# 设计残差块
class ResnetBlock(tf.keras.layers.Layer):
def __init__(self, num_channels, num_residuals, first_block=False,
**kwargs):
super(ResnetBlock, self).__init__(**kwargs)
self.residual_layers = []
for i in range(num_residuals):
if i == 0 and not first_block:
self.residual_layers.append(
Residual(num_channels, use_1x1conv=True, strides=2))
else:
self.residual_layers.append(Residual(num_channels))
def call(self, X):
for layer in self.residual_layers.layers:
X = layer(X)
return X
def net():
return tf.keras.Sequential([
# Thefollowinglayersarethesameasb1thatwecreatedearlier
tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same'),
# Thefollowinglayersarethesameasb2,b3,b4,andb5thatwe
# createdearlier
ResnetBlock(64, 2, first_block=True),
ResnetBlock(128, 2),
ResnetBlock(256, 2),
ResnetBlock(512, 2),
tf.keras.layers.GlobalAvgPool2D(),
tf.keras.layers.Dense(units=10)])
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# loss 0.014, train acc 0.996, test acc 0.915
# 4937.1 examples/sec on /GPU:0
6.3 英文版补充-ResNeXt
ResNeXt网络是ResNet的增强版,融合了ResNet和Inception的特性。
- 在Inception基础上,取消了各种人为设计的卷积核组合
- 不同块之间使用相同的卷积核组合,并增加残差连接的机制
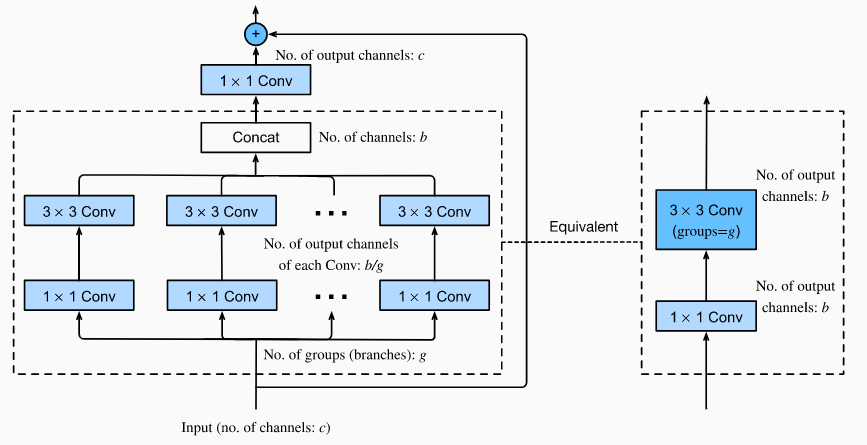
ResNeXt的计算过程:
- 假设最初的输入通道数为$c$,将输入按照通道数划分为$g$组
- 每组卷积核的输出通道数为$b/g$,并联后的通道数为$b$
- 在经过一个$1\times 1$的卷积核,将通道数转化为$c$,并添加残差连接
ResNeXt的优势:
- 减少了大量的人为设计与雕琢
- 相比于Inception类模型超参数少,运行效率高
7 稠密连接网络(DenseNet)
7.1 DenseNet简述
稠密连接网络(DenseNet)在某种程度上是ResNet的逻辑扩展。ResNet使用的是跨单层的简单加法连接,而DenseNet使用的是跨多层的复杂连结:
$$x\rightarrow[x,f_1(x),f_2([x,f_1(x)]),f_3([x,f_1(x),f_2([x,f_1(x)])])]$$
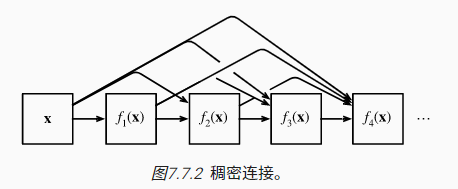
在DenseNet中,一个稠密块(dense block,定义多层之间的连接)由多个卷积块组成,每个卷积块输出通道相同,并且每个卷积块输入和输出在通道维上连结
DenseNet的网络结构和ResNet基本一致,只不过用稠密块替换了残差块,并且使用过渡层(transition layer)来减半高、宽和通道数(因为稠密块的输出维度过高)
7.2 代码实现与训练
PyTorch版本:
import torch
from torch import nn
from d2l import torch as d2l
# 卷积块
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
# 稠密块
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X
# 过渡层
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# num_channels为当前的通道数
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
# 上一个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加一个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
net = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10))
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# loss 0.141, train acc 0.950, test acc 0.901
# 5485.1 examples/sec on cuda:0
Tensorflow版本:
import tensorflow as tf
from d2l import tensorflow as d2l
# 卷积块
class ConvBlock(tf.keras.layers.Layer):
def __init__(self, num_channels):
super(ConvBlock, self).__init__()
self.bn = tf.keras.layers.BatchNormalization()
self.relu = tf.keras.layers.ReLU()
self.conv = tf.keras.layers.Conv2D(
filters=num_channels, kernel_size=(3, 3), padding='same')
self.listLayers = [self.bn, self.relu, self.conv]
def call(self, x):
y = x
for layer in self.listLayers.layers:
y = layer(y)
y = tf.keras.layers.concatenate([x,y], axis=-1)
return y
# 稠密块
class DenseBlock(tf.keras.layers.Layer):
def __init__(self, num_convs, num_channels):
super(DenseBlock, self).__init__()
self.listLayers = []
for _ in range(num_convs):
self.listLayers.append(ConvBlock(num_channels))
def call(self, x):
for layer in self.listLayers.layers:
x = layer(x)
return x
# 过渡层
class TransitionBlock(tf.keras.layers.Layer):
def __init__(self, num_channels, **kwargs):
super(TransitionBlock, self).__init__(**kwargs)
self.batch_norm = tf.keras.layers.BatchNormalization()
self.relu = tf.keras.layers.ReLU()
self.conv = tf.keras.layers.Conv2D(num_channels, kernel_size=1)
self.avg_pool = tf.keras.layers.AvgPool2D(pool_size=2, strides=2)
def call(self, x):
x = self.batch_norm(x)
x = self.relu(x)
x = self.conv(x)
return self.avg_pool(x)
def block_1():
return tf.keras.Sequential([
tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.ReLU(),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')])
def block_2():
net = block_1()
# num_channels为当前的通道数
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
for i, num_convs in enumerate(num_convs_in_dense_blocks):
net.add(DenseBlock(num_convs, growth_rate))
# 上一个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加一个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
num_channels //= 2
net.add(TransitionBlock(num_channels))
return net
def net():
net = block_2()
net.add(tf.keras.layers.BatchNormalization())
net.add(tf.keras.layers.ReLU())
net.add(tf.keras.layers.GlobalAvgPool2D())
net.add(tf.keras.layers.Flatten())
net.add(tf.keras.layers.Dense(10))
return net
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# loss 0.140, train acc 0.950, test acc 0.869
# 5879.0 examples/sec on /GPU:0

8 英文版补充-卷积网络架构设计
整个2010年代,计算机视觉实现了从特征工程到网络工程的转变:
- AlexNet和VGG通过对卷积层的堆叠验证了神经网络深度的重要性
- NiN借助$1\times 1$卷积核和全局池化层实现了对信息更全面的理解与抽象
- GoogLeNet设计了多尺度的卷积核组合,并借助串联并行策略实现有效整合
- ResNets和DenseNets借助残差连接让神经网络具备了更强的信息表达能力
- 除此之外,还有MobileNets、SENets和EfficientNets等优质的神经网络结构范本
神经架构搜索(NAS)是一个自动化设计神经网络架构的过程。给定一个固定的搜索空间,NAS将使用搜索策略,在搜索空间内自动寻找一个性能表现相对最优的网络结构另一个半自动化的思路是,通过借鉴已有的经典神经网络结构大幅减少搜索成本。
在不断采样搜索的过程中,还需要通过误差评估对搜索空间进行逐步约束。假设采样得到了$n$个模型,其中第$i$个模型的错误率为$e_i$,则用于评估采样的误差经验分布函数如下: $$F(e)=\frac{1}{n}\Sigma_{i=1}^n1(e_i<e)$$ 其他空间搜索技巧:
- 相同精度的模型优先选择结构更简单的(奥卡姆剃刀原则)
- 随着网络深度的增开,可以适当的等比增大层的宽度(二者存在一定线性关系)
- 假设第$i$轮搜索后,神经网络中块的宽度为$w_i$,块的深度为$d_i$,在下一轮搜索中增加约束条件:$w_i \leq w_{i+1}, d_i \leq d_{i+1}$,能改善搜索过程(经验性总结)
- 假设第$i$轮搜索后,神经网络中块内部的参数(比如分组卷积的组数$g_i$)可在之后的搜索过程中继承甚至固定,通过约束$g_i=g$能限制搜索空间,减少后期的搜索成本
后记:伴随着Attention机制的出现,Transformer类模型取得了更优质的性能表现,呈现出逐渐取代卷积网络,而2022年的ConvNeXt则验证了卷积层在保持其特有的简单高效的同时,还具备不逊色于Transformer的精度和可拓展性