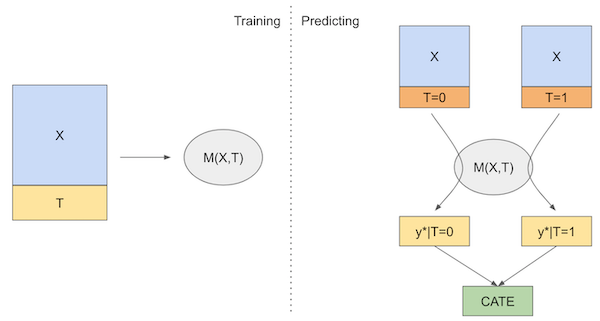
前置知识:随机森林、双重机器学习 DML、因果效应评估_异质性
广义随机森林 GRF
广义随机森林(Generalized Random Forests,GRF)
- 对随机森林的推广,将预测结果扩展为任意统计量
- 能够实现非参数分位数回归、异质性因果效应估计等
为简化理解,下文中均默认广义随机森林的预测目标为异质性因果效应值,此时广义随机森林等价于因果森林;对于其他场景
GRF 与传统随机森林的区别
- 样本使用:传统随机森林使用全部样本来进行叶子节点的分裂和结果预测;GRF 仅使用一部分样本来用于叶子节点分裂,另一部分样