本文对谷歌年度盘点博客进行总结(在原文的基础上进行了一定拓展)
1 生成式模型
1.1 成本效益改善
前置知识:推测编码 speculative decoding
基于块验证来加速推测编码(原始文章 20250410)
- 假设原始大模型为 $\mathcal{M}_{b}$,用于推测加速的小模型为 $\mathcal{M}_{s}$,推测的最大长度为 $\gamma$,历史上下文为 $c$
- 当针对后续文本进行推理时,推测模型 $\mathcal{M}_{s}$ 会先生成一个长度为 $\gamma$ 的草稿序列 ${ X_{1},...,X_{\gamma}}$,并记录每个 token 的概率分布,其中位置 $i$ 对应的推测概率分布为 $\mathcal{M}_{s}(X_{i}|c,X^{i-1})$
- 调用原始大模型 $\mathcal{M}_{b}$,并行计算出每个 token 的概率分布,其中位置 $i$ 对应的原始概率分布为 $\mathcal{M}_{b}(X_{i}|c,X^{i-1})$,则位置 $i$ 对应的累积概率 $p_{i}$ 迭代计算公式如下(累积概率 $p_{i}$ 描述了前 $i$ 个推测 token,作为一个整体被接受的理论最大概率): $$p_{i} = min(p_{i-1} \frac{\mathcal{M}_b(X_i|c,X^{i-1)}}{\mathcal{M}_s(X_i|c,X^{i-1})}, 1)$$
- 针对前 $i$ 个推测 token,其作为一个推测整体被接受的概率 $h_i^{block}$ 计算公式如下(其中分子描述了当前推测结果与最优结果的累积残差,而分母则是在分子加上 $(1-p_i)$,$(1-p_i)$ 则描述了不接受推测整体的理论最小概率,二者的组合描述了停止推测概率,即接受概率):
$$ h_{i}^{\mathrm{block}}=\frac{\sum_{x^{\prime}\in\mathcal{X}}\max{p_{i}\cdot\mathcal{M}_{b}(x^{\prime}\mid\boldsymbol{c},X^{i})-\mathcal{M}_{s}(x^{\prime}\mid\boldsymbol{c},X^{i}),0}}{\sum_{x^{\prime}\in\mathcal{X}}\max{p_{i}\cdot\mathcal{M}_{b}(x^{\prime}\mid\boldsymbol{c},X^{i})-\mathcal{M}_{s}(x^{\prime}\mid\boldsymbol{c},X^{i}),0}+1-p_{i}} $$
- 在每次迭代时,生成满足均匀分布的随机阈值 $\eta_{i}$,当 $\eta_{i} \leq h_i^{block}$ 时,算法判定通过并记录合格块,但算法不会停止,而是继续探索其他可能的合格块
- 在遍历所有可能后,当完整草稿序列属于合格块时,直接返回完整草稿序列;否则按照不同块对应的累积残差分布,来选出最终的合格块(在理论上确保最终结果与 token 级推测结果的分布一致性)
- 基于块验证的推测编码加速能实现更全局的决策,并倾向于接受更长的推测结果;该算法不会增加算法复杂度,还能改善推测编码的实际表现,实现稳定的推理加速(5%~8%);
关于停止推测概率的补充说明,当 $p_{i}=1$ 时,表示推测整体完美匹配真实分布,则停止推测/接受概率为 1;当 $p_{i}=0$ 时,表示推测整体完美不匹配真实分布,则停止推测/接受概率为 0,算法将继续推测
块验证这篇文章首发是 24 年,因此在去年的年度盘点中也提到过,只不过当时的论文是 v1 版本,正文也没仔细看;而在 2025 年 4 月份该文章更新至 v3 版本,本文也在此基础上进行了更完整的描述
LAVA:用于虚拟机集群资源效率优化的调用算法(原始文章 251017)
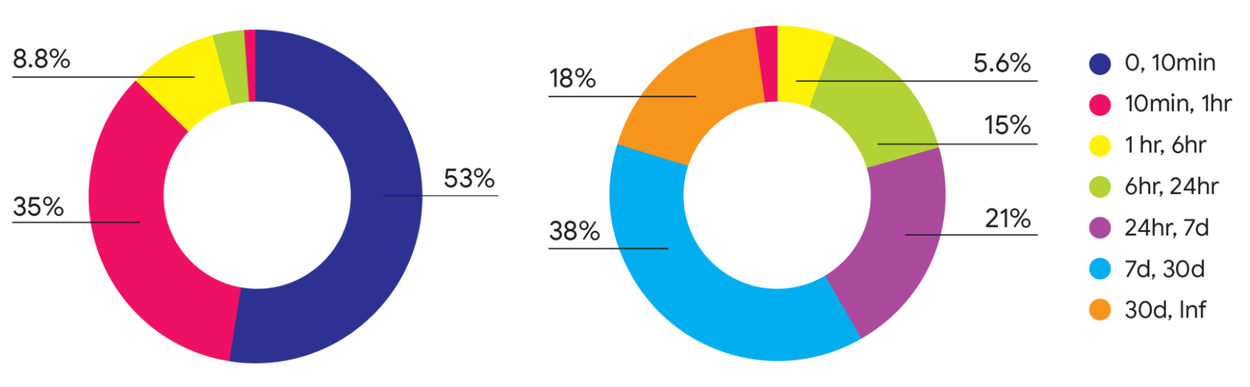
- 当前虚拟机的生命周期(左)与资源消耗(右)分布呈现明显的长尾(long-tailed)现象:短生命周期(0~10 分钟,深蓝色)的虚拟机数量占比高达 53%,但对资源的占用非常小;长生命周期(30 天以上,橙色)的资源消耗占比为 18%,但对应的虚拟机数量占比非常小
- LAVA 主要通过三个核心模块(NILAS/LAVA/LARS)来实现虚拟机集群资源的效率优化
- Non-Invasive Lifetime Aware Scheduling(NILAS),基于生存分析算法对每个主机的生命周期(退出时间)进行预测,然后将预测结果融入评分函数并对潜在主机进行排序,以提高新增虚拟机的分配效率
- Lifetime-Aware VM Allocation (LAVA),将生命周期较短的虚拟机部署在已经运行一个或多个生命周期较长虚拟机的宿主机上,其目标是利用生命周期较短的虚拟机来填补资源空缺
- Lifetime-Aware Rescheduling (LARS),当需要对主机进行碎片整理时,根据预测剩余生命周期对虚拟机进行排序,优先迁移生命周期最长的虚拟机,这样短生命周期的虚拟机会在迁移前自然退出
- LAVA 算法自 2024 年初就部署在谷歌生产数据中心,其表现如下:(1)空置主机数增加 2.3%~9.2%(2)CPU 闲置减少了约 3%,内存闲置减少了 2%(3)性能提升 0.4%,迁移次数减少 4.5%
1.2 LLM 事实性研究
谷歌发布的 Gemini3 模型是目前(251224)事实性基准测试最优的 LLM
- Gemini3 Pro Preview 在 SimpleQA 的 F1 得分为 72.1%,比 GPT5 模型高 20%
- Gemini3 Pro Preview 在 FACTS 的综合得分为 68.8%,比 GPT5 模型高 7%
MetaFaith:评估和改善 LLMs 的不确定性(原始文章 250530)
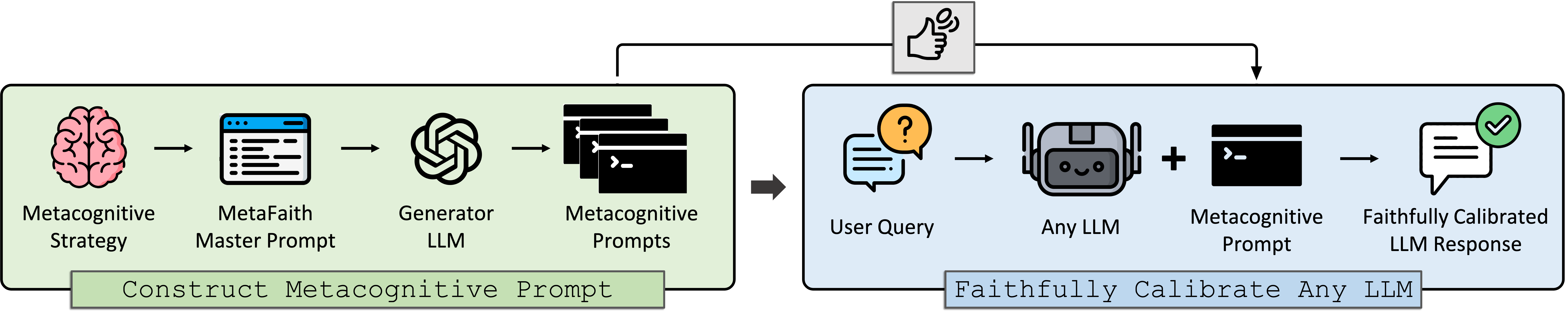
- 给定文本输入 $Q$ 和模型 $M$ 的一系列输出 $Q={A_{1},...,A_{N}}$,本文希望用 $F_{M}(Q,R)$ 来表示内在置信度 $conf_{M}$ 和表达不确定性 $dec$ 之间的一致性:$F_{M}(Q,R)=1-\frac{1}{N}\Sigma_{n=1}^N|dec(A_{n})-conf_{M}(A_{n})|$
- 对于第 $n$ 个断言 $A_{n}$,其内在置信度 $conf_{M}(A_{n})$ 通过计算模型多次输出的一致性来得出;而表达不确定性 $dec(A_{n})$ 则采用 LLM 作为评估器,配合少样本提示来进行评分;根据人工标注结果来进行评价,发现以上得分与人类判断高度一致(相关系数为 0.68)
- MetaFaith 通过元认知提示来改善 LLMs 的表达不确定性(让模型内部在觉得不确定时,忠实得将其表达出来),最终主流 LLM 模型在不同领域的回答忠实度均得到显著改善(最高提升 61%)
所谓的元认知提示就是对提示文本进行提示,针对每个输入的提示文本,元认知提示会提供提示的优化意见,从而确保 LLM 在面对不同的提示文本,都能在底层保持相同的基本认知 除了计算模型多次输出的一致性,内在置信度还有很多评估方法,比如 token 分布、熵值、表征探测、辅助模型预测等方法,具体可参阅原文的背景资料
Inside-Out:评估 LLMs 参数中编码的隐藏事实知识(原始文章 250319)
- LLMs 的知识量化:给定问题的回答中正确答案排名高于错误答案的比例
- LLMs 的内部知识与外部知识:外部知识是基于模型可观察信号(输出 token 概率分布)计算得到的知识,内部知识是基于模型内部不可观察信号(中间层的嵌入表示)计算得到的知识
- LLMs 的隐藏知识:LLMs 的内部知识中超过外部知识的部分
- 核心结论:(1)LLM 始终在其内部编码的事实性知识多于其外部表达的知识,平均相对差距为 40%(2)有些知识隐藏得很深,以至于模型内部完全知道某个答案,即使重复采样 1000 次也不会生成该答案,这说明了 LLM 的生成能力存在局限性(3)更好地利用和表达隐藏知识有助于提升 LLM 性能
ECLeKTic:一个用于评估跨语言知识迁移的数据集(原始文章 250402)
- 语言知识迁移问题:用不同语言询问 LLM 得到的回答差异较大
- ECLeKTic 一个问答(QA)数据集,其通过可能仅从单一语言中观察到的知识,来对 LLM 进行跨语言知识迁移能力的测试,目前已在 kaggle 上开源并且支持 12 种语言
1.3 LLM 检索增强
前置知识:检索增强 RAG
探究充分上下文对 RAG 的影响(原始文章 250514)
- 充分上下文: LLM 拥有足够的上下文信息来回答问题
- 上下文评分器:(1)请人类专家分析了 115 个样本,来确定上下文是否足以回答问题,构成“金标准”(2)基于样本提示、思维链等多种提示策略,来改进 LLM 的评分效果(3)最终用 LLM 输出二分类结果,评估上下文是否充分
- RAG 的关键发现(1)主流大模型在提供足够上下文的情况下都能较好地回答问题(2)即使提供的上下文不够充分,也能弥补模型知识不足或查询歧义等问题(3)较小的开源模型,即使有充分上下文,也存在较高的幻觉和回避率(4)引入额外的上下文会增强模型的信息,反而容易导致更多的幻觉或回避率
- RAG 的改进建议:选择性生成以减少幻觉(1)自我评估置信度,通过提示工程让大模型自我评估其回复的正确率(2)上下文充分性评分信号,来自上下文评分器(3)训练一个逻辑回归模型,来预测幻觉的概率(4)通过权衡覆盖率和准确率来确定阈值,用于决定模型是否应该放弃回答(不同模型的覆盖率和准确率的结果如下)
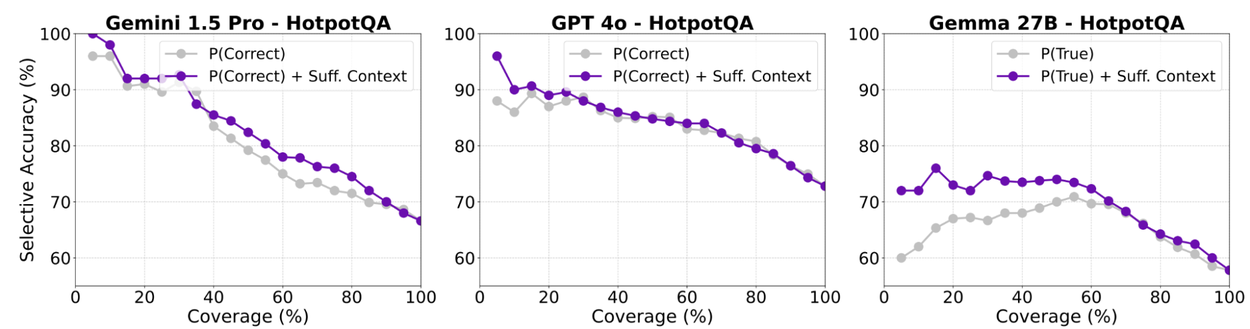
谷歌利用该理念在 Vertex AI RAG 引擎中推出了 LLM 重排序器,用于提高检索性能和 RAG 准确率
1.4 多模态 LLM
25 年 5 月,Google I/O 大会发布最新图像生成模型 Imagen4 和视频生成模型 Veo3
25 年 8 月,Gemini 的图像编辑功能迎来重大升级,集成当前最先进的图像编辑模型 Nano banana;实现风格迁移、图片混搭、多轮编辑、场景迁移等丰富功能
每个 Gemini 创建或编辑的图像,都将包含可见水印和不可见的 SynthID 数字水印
REFVNLI:用于主体驱动的文本到图像生成(T2I)任务的自动评估(原始文章 250424)
- 主体驱动的 T2I:根据给定的文本描述生成图像,同时保留参考主体图像的视觉身份
- 数据构建:利用视频数据集(如 Mementos 和 TVQA+),通过识别视频帧中的主体,创建正样本对(同一主体的不同帧)和负样本对(不同主体的帧),最后用 Gemini 来生成图像描述和标注
- 模型训练:基于 PaliGemma(一个 3B 的 VLM)进行微调,输入为多图像,训练目标是两个二分类任务,分别是文本对齐与主体保留的概率得分
- 自动评估:应用 PaliGemma 对不同基准测试进行评估,评估指标为两个 AUROC 的调和均值
- 评估结果:优于当前的评估方式,文本对齐评估改进 6.4%,主题保留改进了 5.9%
VNLI-Critique:针对图像描述生成结果的事实性评估(原始文章 250609)
- 数据构建:从 DOCCI 数据集中选取了100张多样化的高分辨率图像,然后用 14 种最先进 VLM 是生成详细的段落描述(共 1400 条),最后针对每条描述进行 5 次独立人工标注,标注每个句子的事实正确性分级(4 分类)和非事实内容批注,并确保标准结果的多样性和准确性
- 模型训练:基于 PaliGemma-2(一个 10B 的 VLM)进行微调,输入为图像-文本对,第一个训练目标是分类任务(事实正确性分级),要求模型判断给定句子是否与图像一致,而第二个任务是文本生成(非事实内容批注)任务,要求模型对特定句子不符合事实的原因进行解释
- 实验结果:(1)在多项基准测试中实现 SOTA(2)评估结果与人类判断高度一致,相关系数为 98%(3)利用非事实内容批注对 LLM 进行指导,可显著提高图像描述生成结果的真实性
3DLLM-MEM:具有动态记忆管理的 3D 具身 LLM(原始文章 250528)
- 3DMEM-BENCH 包含三个核心任务基准测试:(1)具身任务,利用长期记忆在多房间环境中执行复杂任务(2)长期记忆具身问答,评估 Agent 对空间关系和时间变化的理解(3)场景描述,用 Agent 对过往经历进行总结,以便在当前任务背景下进行更明智的决策
- 3DLLM-MEM 核心模块(1)基于LLaVA-3D模型构建,通过多视图图像和3D位置嵌入来构建3D感知能力(2)工作记忆/短期记忆,存储当前观察结果;情景记忆/长期记忆,存储过去的观察结果和交互(3)记忆融合机制,用工作记忆中的特征作为查询,在情景记忆中检索和融合最相关的空间和时间特征(4)记忆更新,随着 Agent 与环境的交互,进行短期记忆的更新和长期记忆的转化
- 实验结果:在多项任务中实现 SOTA,体现出模型强大的泛化性和长期记忆管理能力
以上论文显示,谷歌的 AI 技术路径是“先构建不同类型的基准测试,再反向评估和优化 LLM”
1.5 多语言与多文化
谷歌的 Gemma 扩展至 140 多种语言,是成为当今最佳的多语言开源模型
TUNA:基于实证的用户需求与行为分类法(原始文章 251010)
- 分类方法(1)汇总 1193 条人类-AI 对话,并进行迭代式定性分析(2)辅以理论回顾和跨不同情境的验证(3)最终将用户行为组织成一个 6-14-57 的三级层级结构
- 结果与评价(1)最顶层的行为分类包括信息检索、综合、程序指导、内容创作、社交互动和元对话(2)用新增对话验证分类结构,覆盖全面、全部可映射(3)可用于跨产品的政策协调和多尺寸评估,并为构建特定领域的分类体系提供基础框架,减少工作的隐藏成本
Amplify Initiative:用于新型数据收集和验证的数据开发平台(原始文章 250502)
- 撒哈拉以南非洲试点项目:该研究通过一款安卓应用程序实现,与 155 位领域专家共同编写,最终生成了一个涵盖七种语言、包含 8,091 个对抗性查询的标注数据集
- 后续计划:在巴西和印度进行推广,探索获取网络不可得知识的创新方法
看来网络数据确实是不够用了,不过目前来看主要是希望促进多文化发展~
增强 LLM 的多元文化感知(原始文章 250716)
- 两个知识来源:聚合多文化知识并向量化为可检索知识库,谷歌的搜索 API
- 搜索增强:有选择性的筛选最多 5 篇相关文档,并作为提示文本来增强 LLM
- 实验结论:LLM 能正确回答很多文化类命题,但结果的刻板印象也明显增加
2 科学前沿与发现
2.1 量子计算
Willow 量子芯片在硬件上实现 Quantum Echoes 算法(原始文章,251022)
- 该研究首次证明了量子计算机可以在硬件上成功运行一个可验证量子回声(Quantum Echoes)算法,甚至超越了最快的经典超级计算机(速度快了 13,000 倍)
- “量子回声”机制类似于声学中的回声,但基于量子干涉原理。研究人员在 Willow 芯片的 105 个量子比特上,先正向运行量子操作,扰动一个量子比特,再精确反向运行,捕捉由此产生的“量子回声”
- 该算法在计算分子结构方面展现出 13,000 倍于当前最快经典算法的速度优势。它通过模拟物理实验,精确测量系统中扰动的传播过程,能够揭示分子、磁体甚至黑洞等复杂系统的内部结构
- 这是历史上首次有量子计算机成功运行了超过超级计算机能力的可验证算法;量子可验证性意味着,该算法可以在任意同等性能的量子计算机上重复运行,并得到相同的结果
量子计算的发展在逐渐走向实际应用,目前可用于推动药物设计和聚变能源
量子计算走向应用的六个里程碑阶段(roadmap)

- 里程碑 1:发现并分析能够超越古典算法的量子算法,确定量子优越性(2019 年)
- 里程碑 2:实现量子纠错,通过增加量子比特的规模来指数级减少错误(2023 年)
- 里程碑 3:构建一个长寿命逻辑量子比特,实现长期纠错,增加量子计算的稳定
- 里程碑 4:创建逻辑门/逻辑晶体管,维持逻辑量子比特的存储和高保真逻辑运算
- 里程碑 5:工程规模化,扩展逻辑量子比特和逻辑门数量,解决控制和冷却等工程挑战
- 里程碑 6:大型纠错量子计算机,能够运行复杂的量子算法,解决复杂的实际应用问题
目前谷歌的量子计算团队在专注于实现里程碑 3
2.2 加速科学发现
AI co-scientist:用于辅助科学发现的多 Agents 系统(原始文章 250226)
- 系统设计(1)Agent 分工,包括生成假设、比较和排名、审查假设、改进假设等(2)生成假设,通过文献探索、模拟科学辩论和识别中间假设来生成初始假设(3)比较和排名,通过模拟科学辩论对假设进行比较和排名(4)审查和改进,根据审查反馈进行学习和改进,提高假设质量(5)专家参与,科学家可以通过自然语言与系统互动,提供反馈和建议
- 系统评价(1)针对急性髓系白血病(AML)的药物再利用候选药物,并在体外实验中实现药物的抗肿瘤活性验证(2)提出针对肝纤维化的新表观遗传靶点,并在人体肝细胞类器官中得到验证(3)提出了一个关于细菌基因转移的新机制,并在实验中得到验证
基于 AI 系统帮助科学家编写专家级实证软件(原始文章 250909)
- 该系统基于 Gemini 构建,能够以明确的问题定义和评估方法为输入,提出具体的实现方法和软件架构,并转化为可执行代码,最后通过实证方法进行性能验证
- 创新点:融合树搜索技术(灵感来自 AlphaZero)搜索并迭代数千个代码变体,以优化性能
- 实验阶段,使用涵盖基因组学、公共卫生、地理空间分析、神经科学、时间序列预测和数值分析等六个不同学科领域的基准测试对系统进行了测试,最终结果均达到专家级水准
3 生物与神经科学
3.1 基因组学
AlphaGenome:利用人工智能更好地理解基因组(原始文章 250625)
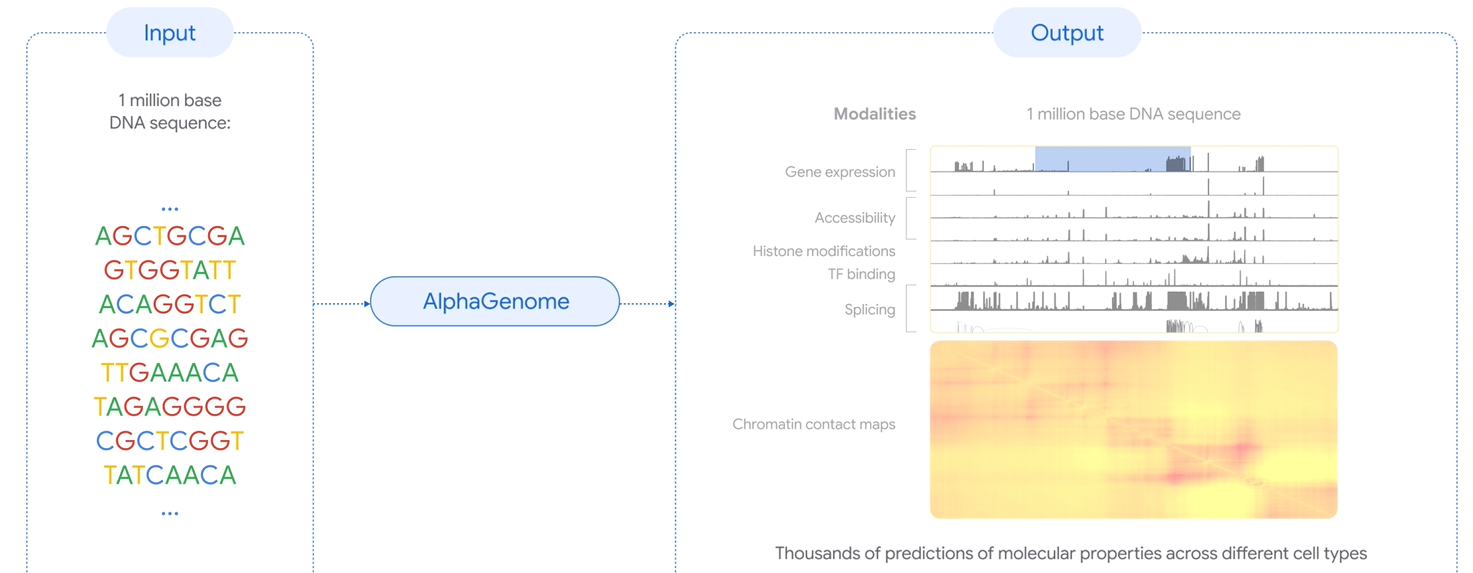
- 基本特性:AlphaGenome 模型以长 DNA 序列为输入(百万级碱基对),预测其调控活性的数千种分子特性;它还可以通过比较突变序列与未突变序列的预测结果来评分遗传变异或突变的影响
- 模型架构:用卷积层来最初检测基因组序列中的短模式,用 Transformer 在序列的所有位置之间传递信息;最后使用一系列的预测头将检测到的模式信息转换为不同模态的预测
- 实验结果:AlphaGenome 在单个 DNA 序列分子特性预测的 24 项评估中取得了 22 项 SOTA;在预测变异的调控效应的 26 项评估中取得了 24 项 SOTA;AlphaGenome 目前暂未开源,但提供了用于非商业研究的 AlphaGenome API
- 应用方向:(1)有助于疾病的理解和潜在原因定位,从而可能发现新的治疗靶点(2)有助于指定具备特定调控功能的 DNA 合成设计(3)协助绘制基因组的关键作用,识别和调节 DNA 指令,提高基因组理解的基础建设
DeepSomatic:识别癌细胞相关的基因序列变异(原始文章 251016)
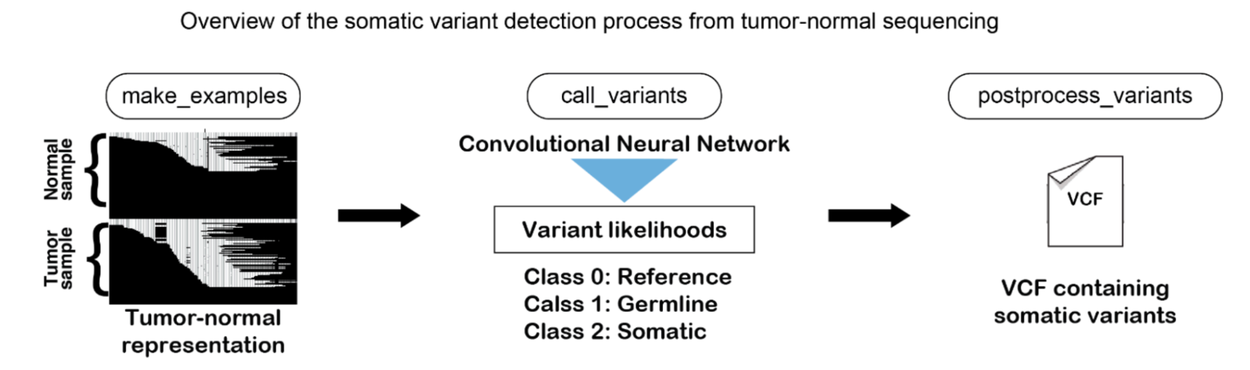
- 模型原理:(1)将基因测序数据转换一组包含测序数据、染色体比对结果等信息的图像(2)利用卷积神经网络学习并区分由癌症引起的体细胞变异 Somatic(3)剔除测序过程中微小误差导致的变异,并最终输出一个包含与癌症相关突变基因列表的 VCF 文件
- 实验结论:在多个基准测试中取得 SOTA,并且模型可推广到其他癌症类型
- DeepSomatic 的相关代码和高质量训练数据已开源
C2S-Scale:270 亿参数的单细胞分析基础模型(原始文章 251015)
- 基于 Gemma 系列开源模型,经过大量转录组数据、生物学文本等语料库进行训练,其预测和生成能力均得到显著提升,并支持需要跨多细胞环境信息整合的高级下游任务
- C2S-Scale 对单细胞的分析效果超越了专用单细胞模型和通用 LLM;其发现一种新的潜在癌症治疗途径,随后谷歌团队与耶鲁大学合作,通过活细胞实验验证了该假设
3.2 神经与脑科学
LICONN:一种基于光学显微镜的连接组学方法(原始文章 250507)

- 图像说明:(a)小鼠初级体感皮层局部重建的 79 个示例细胞(b)对锥体神经元的细胞内结构和初级纤毛的局部放大(c)树突棘和细胞核的局部放大(d)神经突起周缘的周期性结构(e)轴突追踪的“金标准”验证,重建后的轴突和真实情况高度吻合(f)树突与树突棘追踪的验证(g)不同视角下 658 个细胞结构的人工彩色标记和完整三维渲染图
- 文章总结:(1)首次用光学显微镜,全面绘制哺乳动物脑组织中所有神经元及其连接(2)LICONN 能够利用光学显微镜采集图像,实现复杂分子机制与神经元结构可视化(3)传统光学显微镜的分辨率通常为250—300纳米,LICONN 能将有效分辨率提高了16倍,达到了20纳米以下
斑马鱼活动预测基准数据(ZAPBench):该基准数据记录了超过 7 万个斑马鱼幼体大脑神经元的活动,将使科学家能够首次研究整个脊椎动物大脑的结构连接与动态神经活动之间的关系
通过 LLM 表征破译人脑语言处理过程(原始文章 250321)
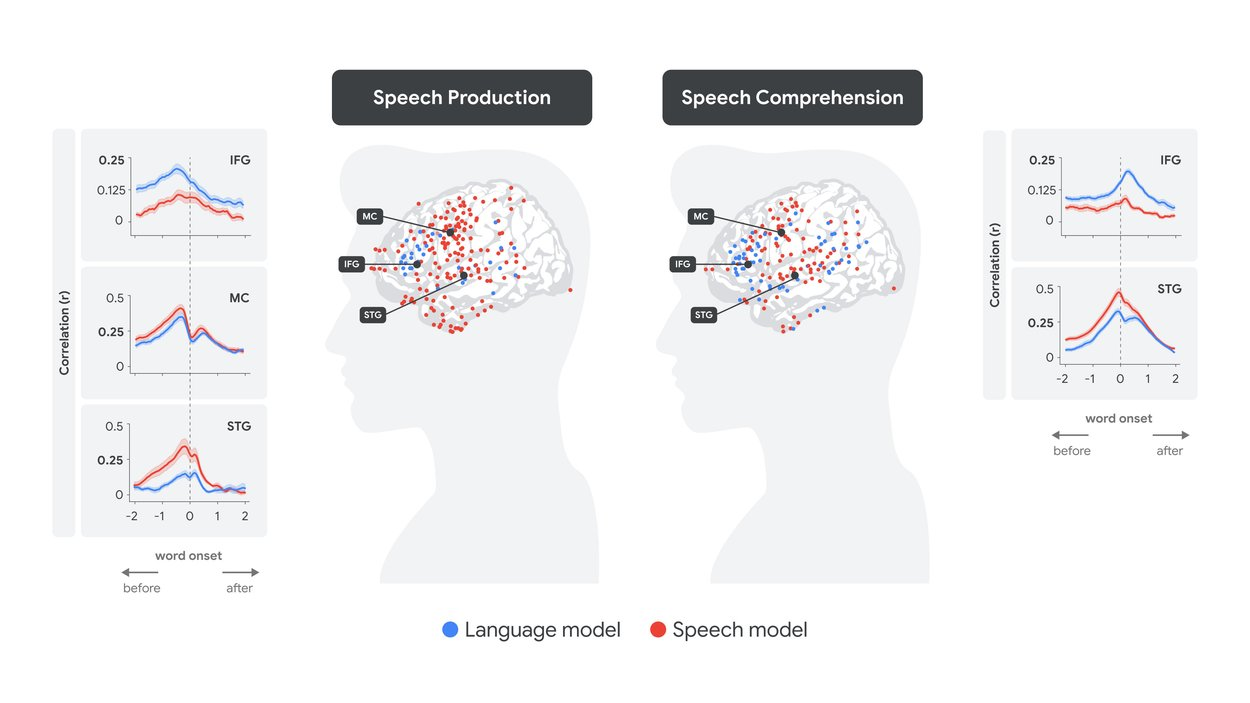
- 从 Whisper 语音转文本的模型中提取两类嵌入向量:语音嵌入和文本嵌入(红)
- 对两类嵌入表示进行线性变换,预测每次对话中单词对应的大脑神经信号
- 在发音前约 500 毫秒(受试者准备发音下一个词时),文本嵌入(蓝)预测了布罗卡区(IFG)的皮层活动;几百毫秒后(仍在词语出现之前),语音嵌入(红)预测了运动皮层 (MC)的神经活动;说话者发音之后,语音嵌入预测了颞上回(STG)听觉区域的神经活动
- 以上现象表明,嵌入向量与神经信号之间存在对应关系;模型内部的处理层级与语音和语言处理的皮层层级相一致,其中语音嵌入对应感觉和运动区域,而文本嵌入对应高级语言区域
对于以上场景来说,布罗卡区(IFG)对应语言规划和语法处理能力,运动皮层 (MC)对应发音器官运动能力,颞上回(STG)听觉区域对应声音的感知和分析能力
大脑语言处理的时间结构对应 LLM 层级结构(原始文章 251126)
- 原理:利用 LLM 的上下文嵌入,来拟合预测不同时间分辨率的脑电图信号
- 结论:LLM 不同层级的嵌入表示能够映射到不同延迟下的大脑高级语言区域
4 行星智能与气候
Earth AI:整合了 Google 的众多地理空间模型和技术,例如遥感图像、天气 、空气质量、洪水、人口动态、AlphaEarth 基础、移动性、地图等等
AlphaEarth:地球观测数据的统一嵌入表示(原始文章 250730)
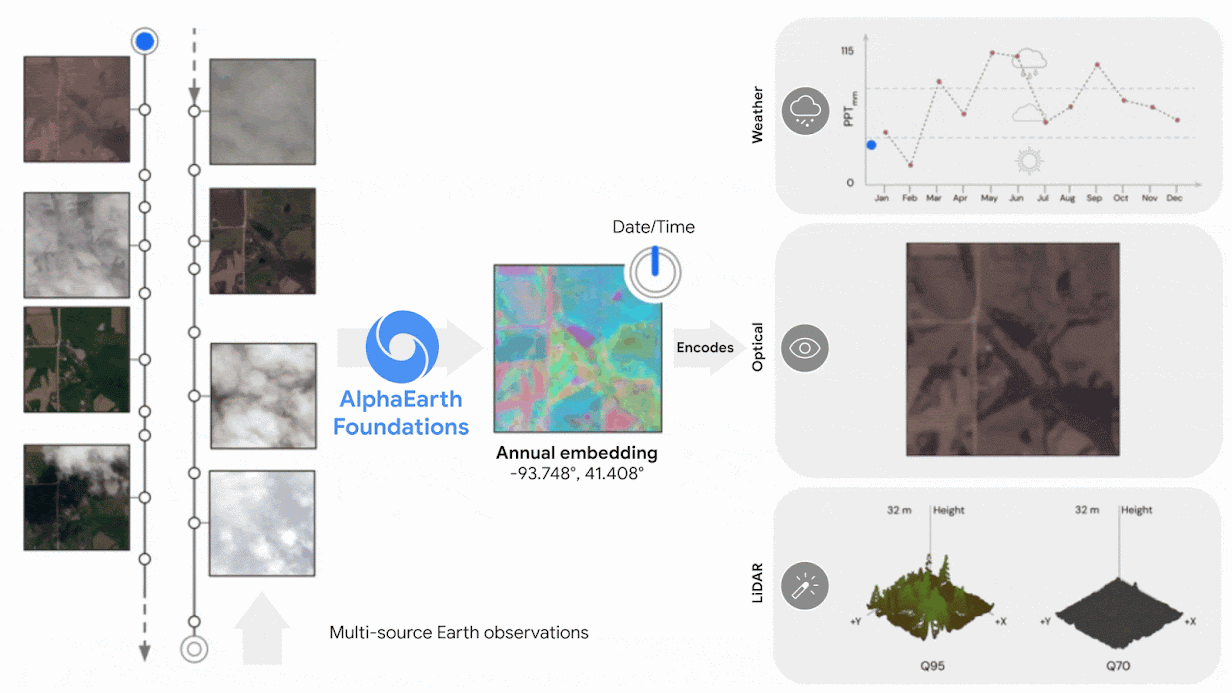
- AlphaEarth 整合了来自数十个不同公共来源的大量信息——光学卫星图像、雷达、三维激光测绘、气候模拟等。它将这些信息编织在一起,并针对 10x10 米的地理区域信息形成的统一嵌入表示
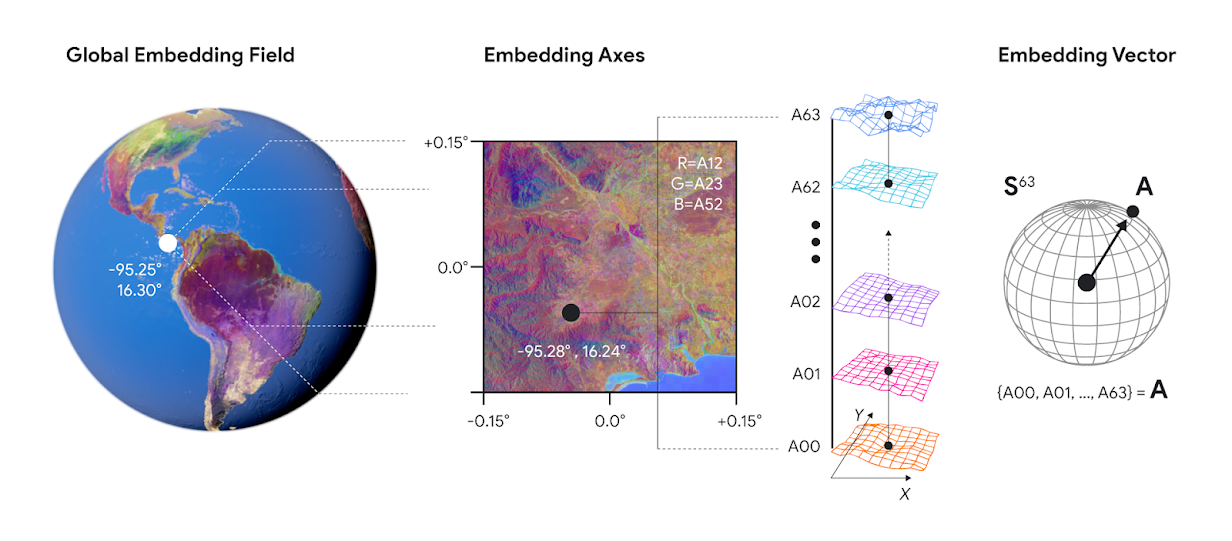
- 上图展示了地理信息嵌入表示的结果,每个嵌入表示包含 64 个嵌入表示分量
- AlphaEarth 能从视频序列中获取非均匀采样的帧来索引任意时间位置,并能够以惊人的精度追踪全球陆地和沿海水域随时间的变化情况,从而绘制地理信息的连续时间视图
- AlphaEarth 相比其他制图方法,错误率降低 24%,存储空间减少 16 倍;可用于监测作物健康状况、追踪建筑变迁和森林砍伐;在环境保护和治理、生物多样性恢复等方面也有重要意义;数据集已开源
FireSat 卫星:利用 AI 进行小型野火近实时探测,捕捉到了一场其他系统未发现的小型火灾
洪水预测模型:覆盖 150 个国家/地区的 20 多亿人口,能够预测严重的河流洪水事件
气旋预测:利用随机神经网络的实验性模型,可帮助气象机构提前 15 天预测气旋路径
WeatherNext 2 :迄今为止最精准的中程 AI 天气预报
- 能够高精度地预测包括风速和风向、降水和气压在内的关键天气变量
- 预测速度提高了八倍,能够覆盖更多场景,更有效地预测低概率但灾难性的天气事件
- 每天生成四次六小时天气预报,这些小时级的天气及时预报,有助于更好地进行决策
Weather Lab 人工智能(AI)天气模型互动网站(原始文章 250612)
- 谷歌 DeepMind 与谷歌研究(Google Research)联合推出了名为 Weather Lab 的网站,展示其基于 AI 的实验性天气模型。该平台能提前 15 天预测气旋的形成、路径及强度,并生成 50 种可能的情景
- 该模型已获得美国国家飓风中心(NHC)的科学验证,并向其提供实时预测数据,旨在辅助预报员做出更精准的判断。 内部测试显示,其 5 日路径预测精度比现有领先的物理模型高出 140 公里,相当于将预测水平提升了 1.5 天
MetNet:在搜索平台提供的全球天气实时预测模型,能够为非洲用户提供高精度短期降水预报
NeuralGCM 模型:为 3800 万农民提供更长期的季风预报,帮助作物种植类型和时机的关键决策
5 健康与教育
5.1 健康人工智能
AMIE 多模态对话式医疗 Agent(原始文章 250409)
- AMIE 是谷歌在 24 年推出的诊疗 Agent,具备自我进化和链式推理能力
- 本文通过一项随机、双盲交叉研究,用经过验证的 159 例模拟患者案例,比较了 20 位初级保健医生和 AMIE 的对话场景下诊断结果,并由专科医生进行评估
- 最终结果显示,AMIE 能提供与初级保健医生同等甚至更优的长期疾病管理支持
g-AMIE 以医生为中心的诊疗 Agent (原始文章 250812)
- AMIE 不再提供个性化医疗建议,而是采集并生成用于主治医生审核的病史摘要
- 由审核医生负责诊断和治疗方案的鉴别和修订,以确保患者安全和责任落实
g-AMIE 的最终输出形式为 SOAP 格式医疗记录
MedGemma 多模态医学理解开源模型(原始文章 250709)
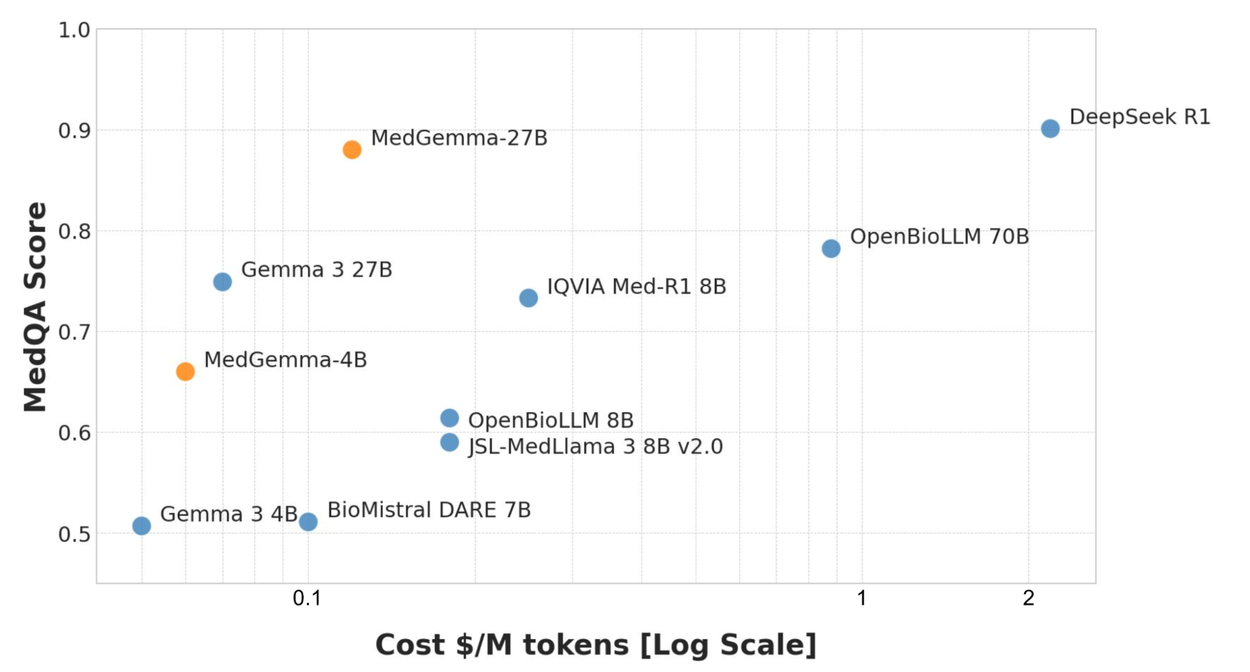
- MedGemma 模型支持分类、报告生成或解读复杂电子健康记录等任务
- 在 MedQA 平台上,MedGemma 4B 和 27B 是同等规模中性能最佳的模型
- 81% 的 MedGemma 4B 生成的胸部 X 光片报告的准确性与原始放射科医师相似
- MedGemma 27B 模型在 MedQA 医学知识和推理基准测试中表现优异,是小型开源模型(<50B)中表现最佳的模型, 可以与主流 LLM 相媲美
5.2 学习和教育
Learn Your Way:用于革新教育的实验性项目
- 将静态教科书转化为为每位学生量身定制的主动学习体验
- 提供交互式测验,实现实时评估、反馈和内容个性化
- 记忆力测试中的得分比使用标准电子阅读器的学生高出 11 个百分点
AI and the Future of Learning,人工智能与未来教育的报告
- 人工智能改变未来教育(1)将学习科学的过程融入日常生活,拓展学习的边界(2)实现个性化教学和辅导的大规模落地(3)降低学习和理解事物的成本,提高知识的覆盖面(4)减少语言、信息壁垒等学习障碍,促进教育公平(5)作为教学助手,释放教师的真实价值
- 人工智能在教育领域的挑战(1)确保准确性和客观性,避免“幻觉”导致的虚假或误导性信息(2)重视内容分级,保护年轻用户的身心健康(3)引导和激发学生的深度思考能力,避免对 AI 的过度依赖(4)警惕 AI 作弊行为,重新设计学习和教育的评估体系(5)确保 AI 教育的广泛普及,提高 AI 的公平性和语言/文化多元性
- 人工智能在教育领域的最新进展(1)构建用于教育目的的 LLM,Gemini 2.5 Pro(2)积极探索新型教育模式,利用 NotebookLM 等工具实现更个性化、更高效的学习体验(3)与教育界积极合作,发挥人工智能在教育领域的潜能
“人工智能探索之旅”(AI Quests)项目:鼓励学生运用 AI 解决洪水预报和眼病检测等问题
6 基础算法研究
TimesFM 时序预测
Jax Privacy 1.0 用于机器学习的差分隐私库
嵌套学习 全新的机器学习范式
MUVERA 新型检索算法
7 合作与展望
机构合作、全球团队、会议研讨(略)
科研的黄金时代:
- magic cycle:技术突破和科学进步从未如此迅速地转化为具有深远影响的实际解决方案,而这些解决方案反过来又会催生新的数据和问题,从而激发新的基础研究方向
- 人工智能将会成为人类创造力的放大器;在更强大的模型、支持科学发现的新型智能工具以及开放平台和工具的推动下,整个科研转化再投入的循环正在加速!