OpenRouter 作为流行大模型 API 路由平台
- 覆盖了 60 多个供应商的 300+多个活跃模型,服务数百万开发者和终端用户
- 积累了大量 AI 模型的消耗记录,其局限性在于其中超过 50%的使用源自美国境
本文内容主要参考自:基于 OpenRouter 百万亿 token 消耗的 AI 现状研究报告
开源模型与闭源模型
开源模型与闭源模型的绝对市场占比:
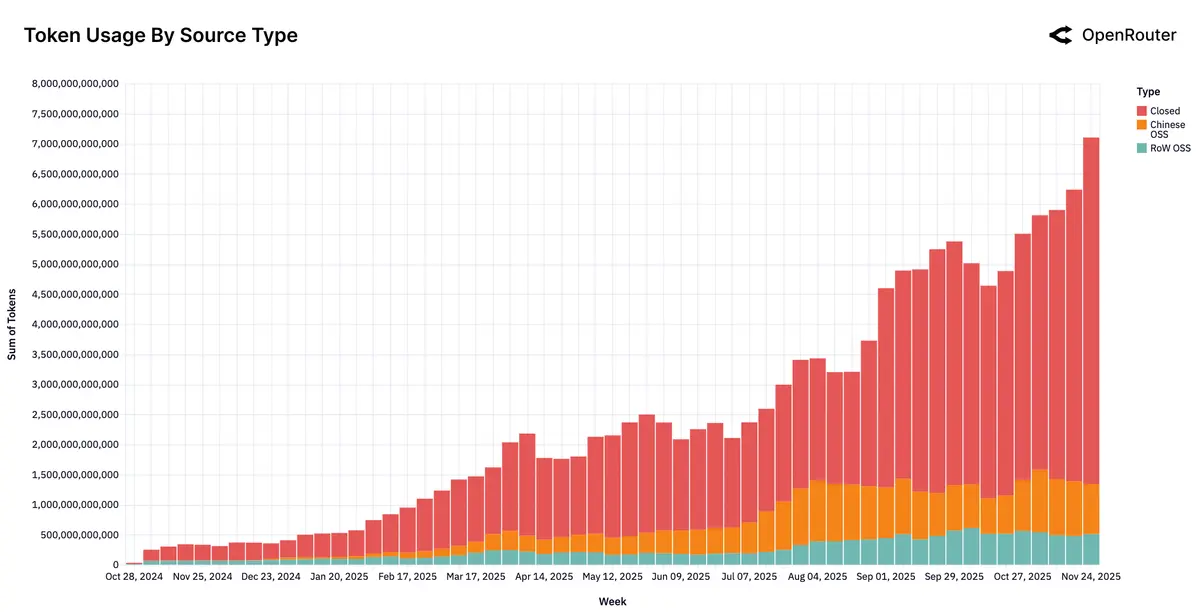
- 深红色表示闭源模型(Closed),橙色表示中国开源模型(Chines OSS),青绿色表示其他开源模型(RoW OSS)
- 整个市场的总 token 消耗量呈现出明显上涨趋势,展示了 AI 在社会各个领域的渗透,其中闭源模型占比仍保持优势
开源模型与闭源模型的相对市场占比:
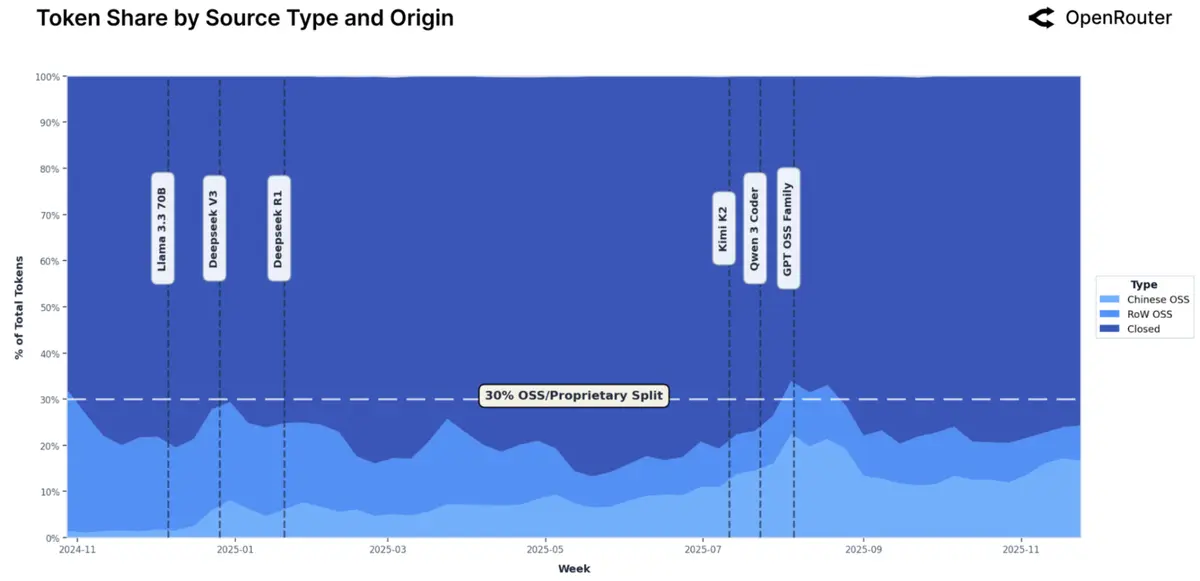
- 开源模型的 token 消耗占比始终保持在总消耗量 30% 以内,开源与闭源模型在市场上维持着微妙平衡
- 得益于 DeepSeekV3 和 KIMI2 等开源模型,中国开源模型(chinese OSS)的占比呈现明显的上涨趋势
不同厂商的开源模型相对占比:
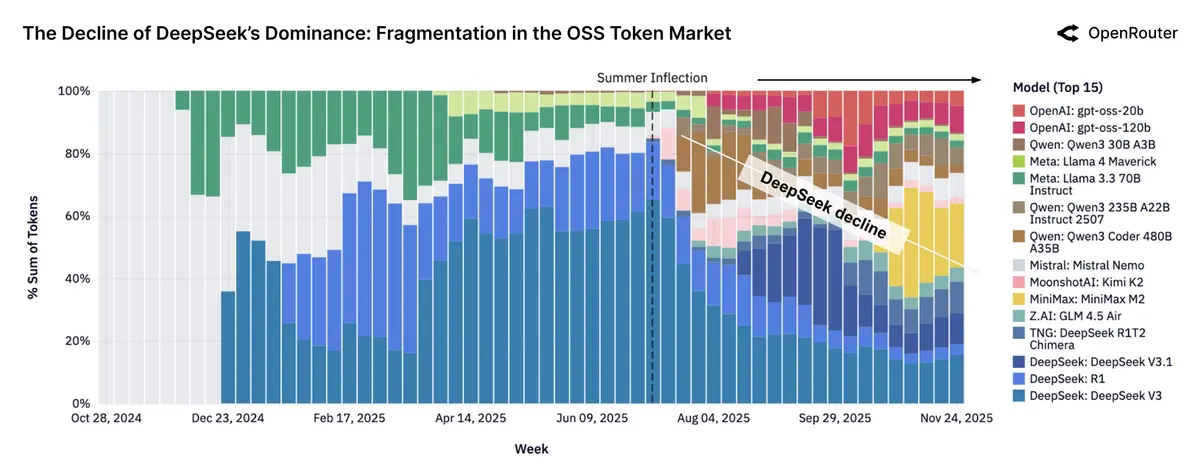
- 开源模型市场明显保持日益激烈的竞争关系,不存在长期保持占比优势的单一开源模型
- 在 2025 年上半年,DeepSeek 系列开源模型在市场上保持绝对优势(三个 DeepSeek 开源模型的占比>50%),这一垄断地位在 2025 年下半年被打破,开源模型市场呈现更明显的百花齐放的状态(gpt-oss、Kimi、MiniMax);而在 2025 年末,已经不存在单一开源模型的市场占比超过 25%的情况
不同尺寸的开源模型相对占比:
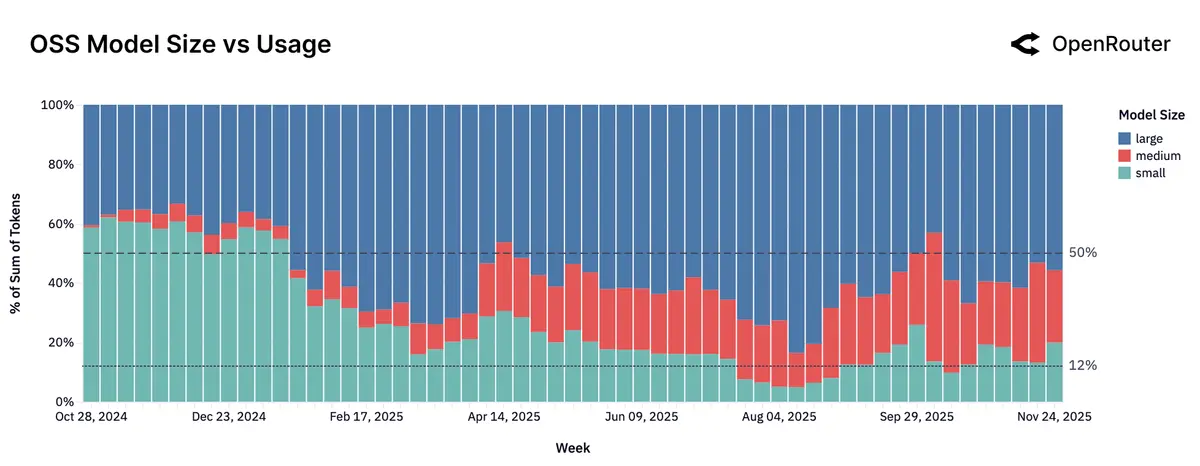
- 小尺寸(参数量<15 billion)开源模型的市场占比逐渐萎靡,而中尺寸(参数量在 15~70 billion)开源模型的市场占比逐渐扩展,大尺寸(参数量>70 billion)开源模型的市场占比依然保持相对优势(>50%)
开源模型的用途类型相对占比:
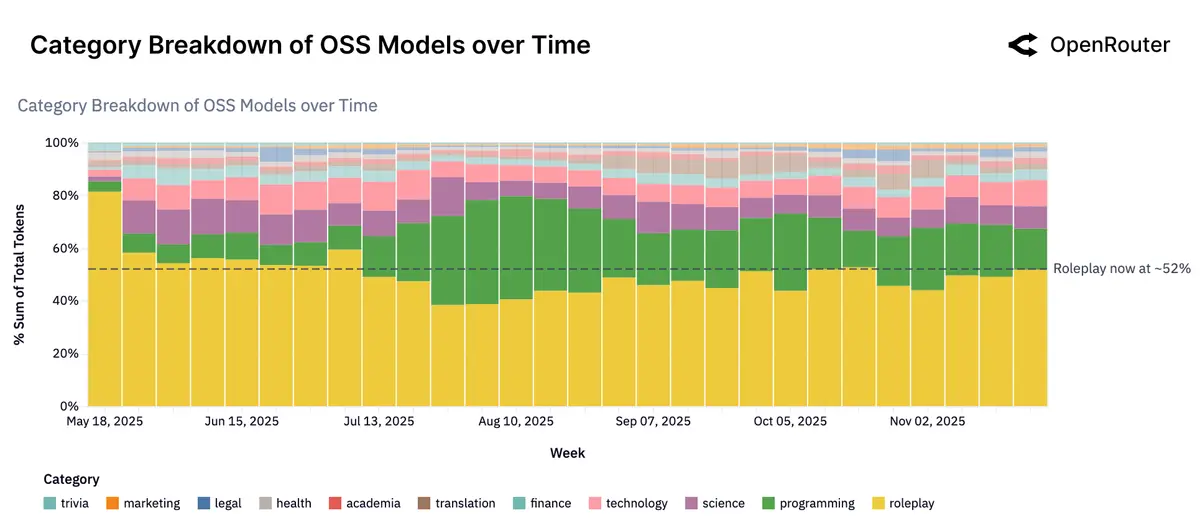
- 50%的开源模型 token 消耗用于角色扮演(rolepaley) ,其次是编程(programming)
推理 Agent 的兴起
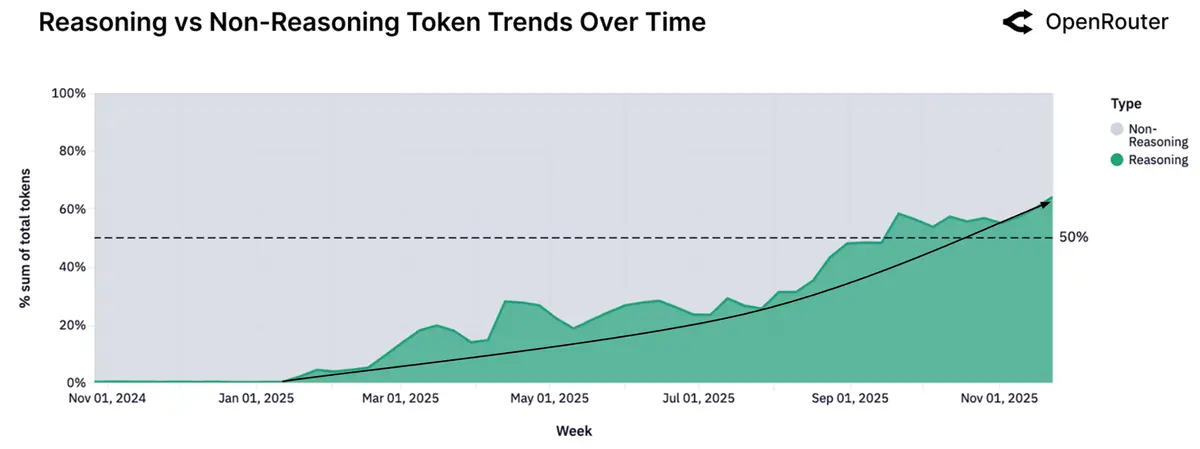
推理模型的 token 消耗占比从 2025 年初从零开始,快速增长到如今的 50% 以上:
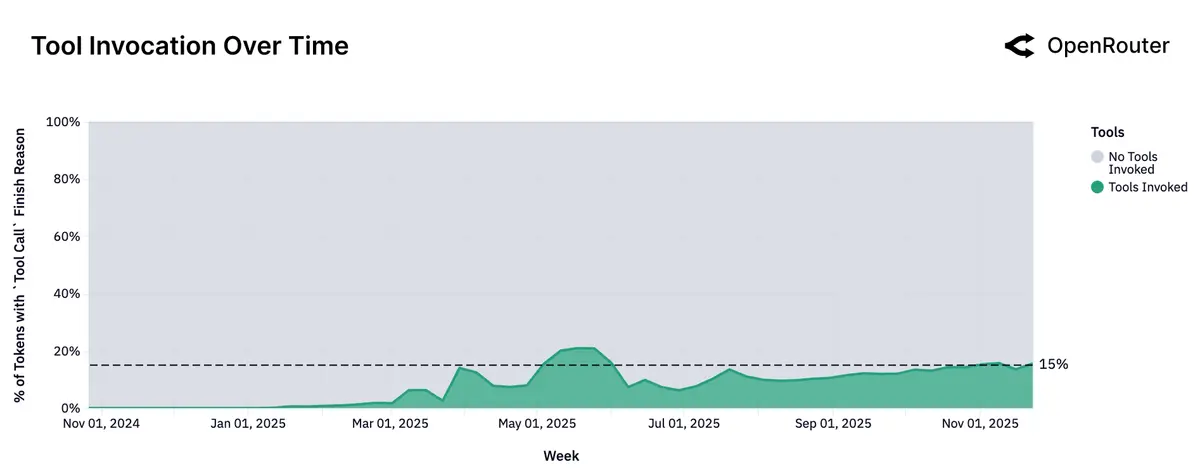
 Agent 的工具调用需求也日益增长,目前在总 token 消耗的占比约为 15%:
Agent 的工具调用需求也日益增长,目前在总 token 消耗的占比约为 15%:
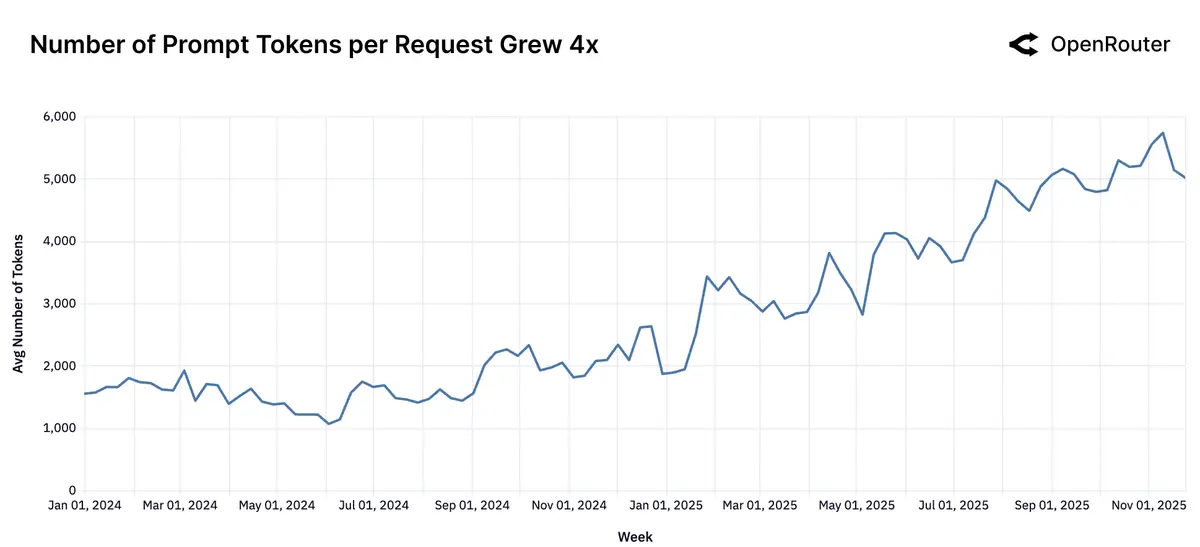
受推理模型的普及影响,提示消耗的 token 量增加了约 4 倍,而输出消耗的 token 量增加了约 3 倍(进一步分析可发现,编程相关推理任务的增加,是导致 token 量消耗增加的重要原因):
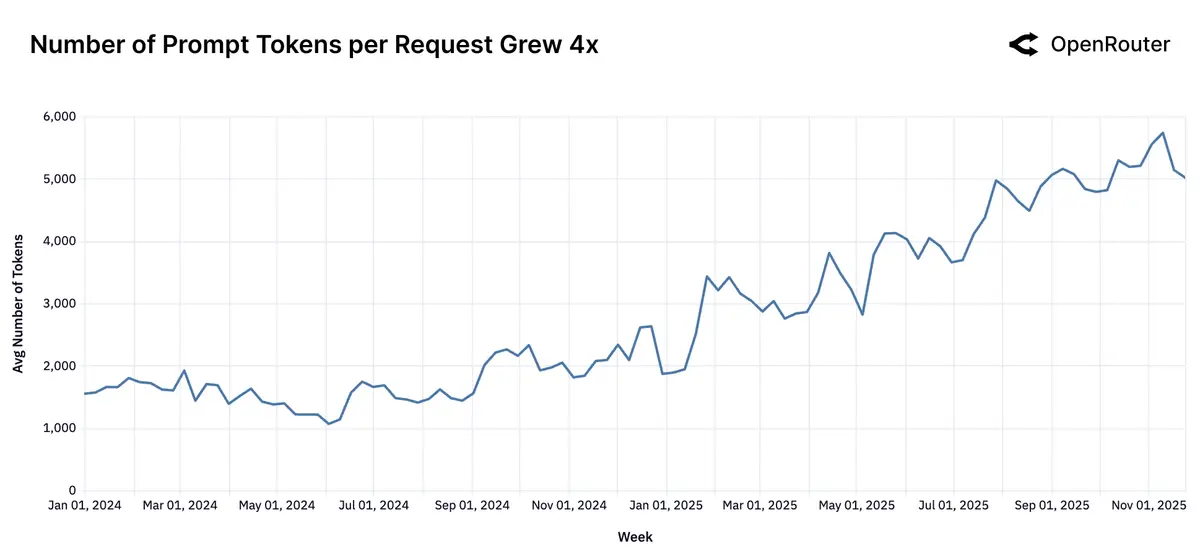
AI 模型的主要用途
所有模型(开源+闭源)的用途类型相对占比:
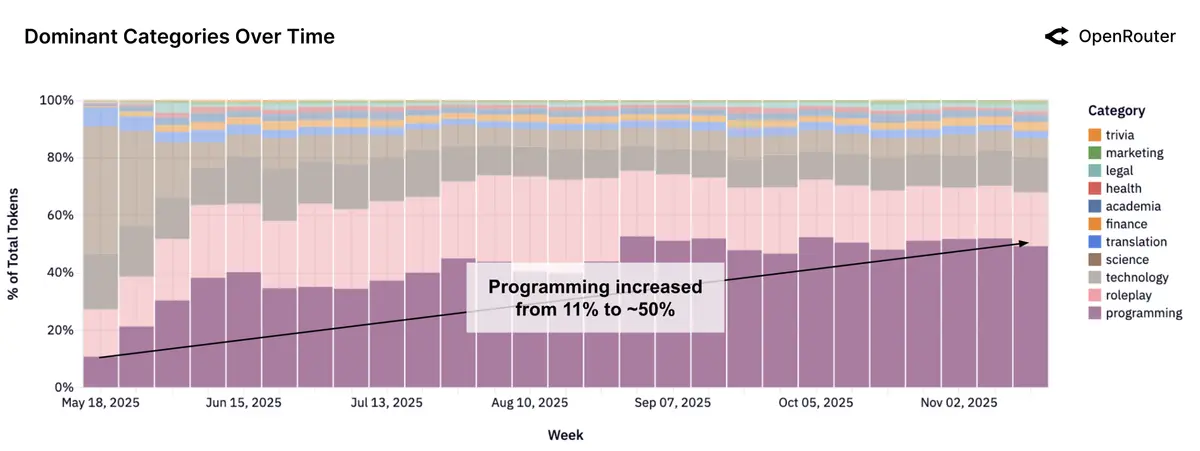
- 用于编程(programming)的 token 消耗占比从 11%逐渐增长到 50%,反映了 AI 辅助编程的兴起
用于编程任务的不同模型相对占比:
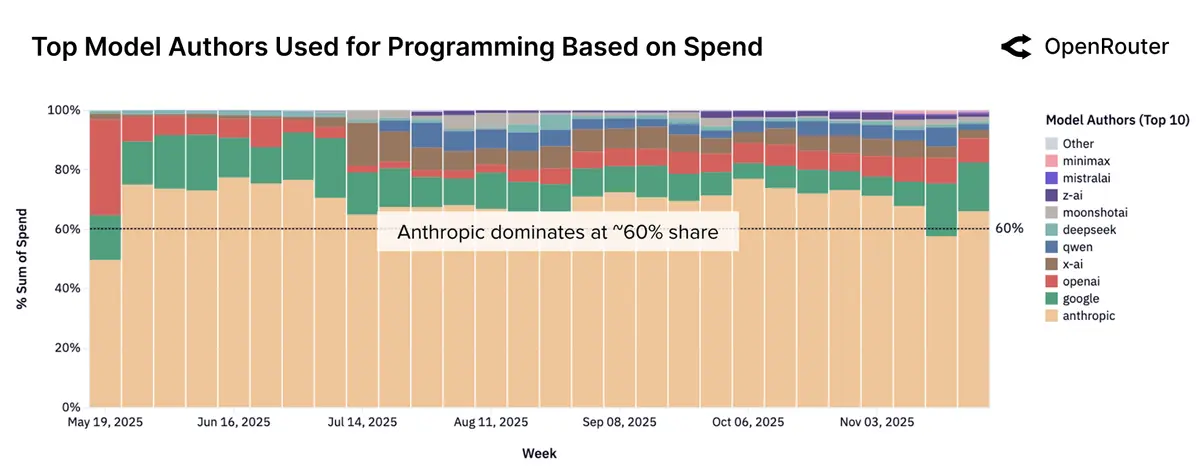
- Anthropic 是编程用途的主力模型(占比>60%),其次是 OpenAI 和 Google
Top6 用途的次级分类/标签分布分析:
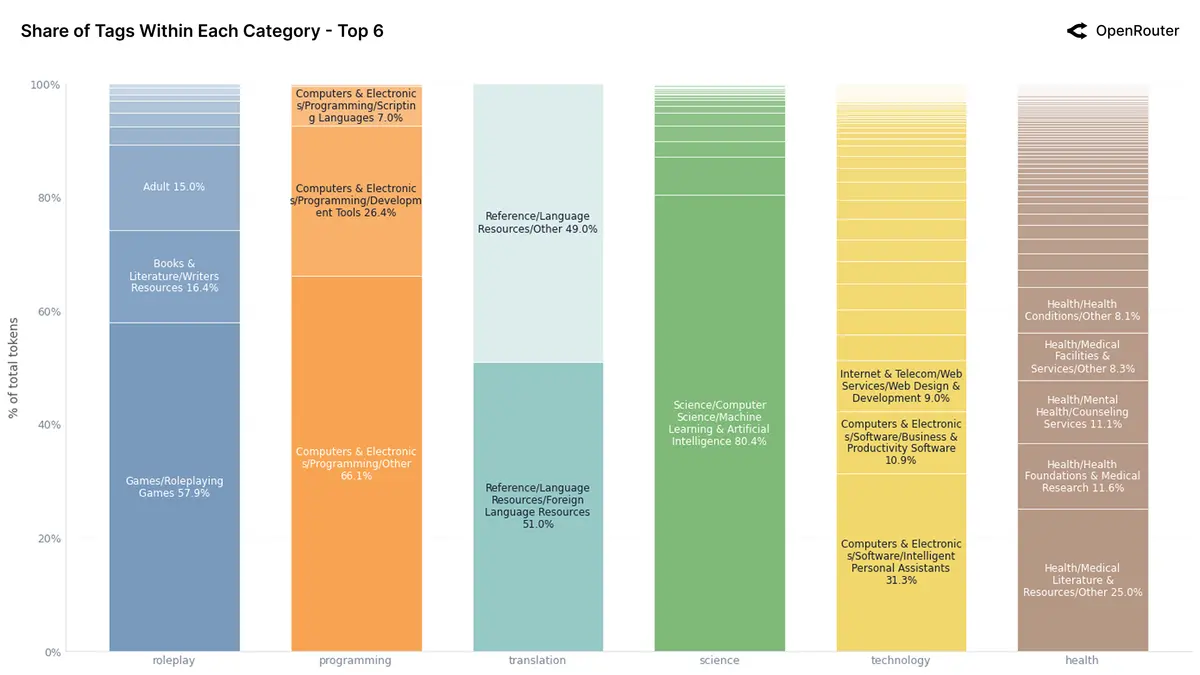
- 当 AI 用于角色扮演(roleplay)时,主要涉及游戏领域(57.9%)、文学创作(16.4%)和成人内容(15.0%)
- 当 AI 用于辅助编程(programming)时,主要涉及通用编程(66.1%)和工具开发(26.4%)
不同厂商模型的用途差异:
- Anthropic 的模型主要用于编程和技术任务(超过 80%),角色扮演使用极少
- Google 的模型用途广泛/偏向通用信息引擎,覆盖法律、科学、技术及部分常识问题
- xAI 的模型主要集中在编程领域,25 年 11 月底调整开发免费策略,导致用途明显多元化
- OpenAI 的模型主逐渐侧重于编程和技术任务,角色扮演和休闲聊天任务显著减少
- DeepSeek 的模型以角色扮演(占比大约在 80%)和随意互动为主
- Qwen 的模型更专注于编程任务,其次也会覆盖到角色扮演和学术领域
AI 模型的区域差异
不同区域的 token 消耗量相对占比:
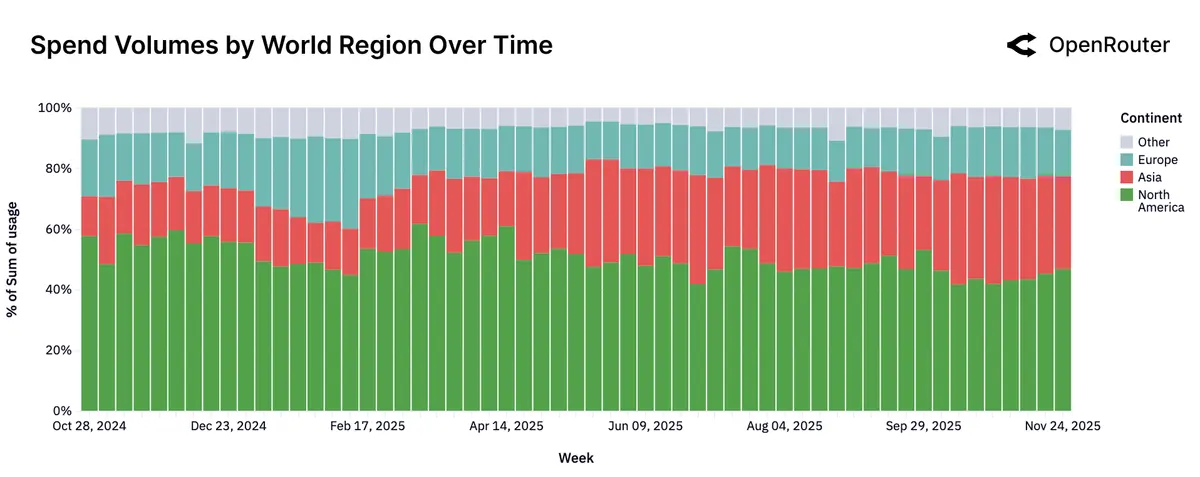
- 北美地区总 token 消耗略有下降,但占比依然最大(约 50%);欧洲地区总 token 消耗占比相对稳定;亚洲地区总 token 消耗占比增长明显,从最初的 13%逐步增加到最近的 31%
从国家来看,美国总 token 消耗占比很高(47.17%), 其次是新加坡(9.21%)、德国(7.51%)和中国(6.01%,失真)
从语言来看,英语总 token 消耗占比极高(82.87%), 其次是简体中文(4.96%,失真)和俄语(2.47%)
AI 用户的留存分析
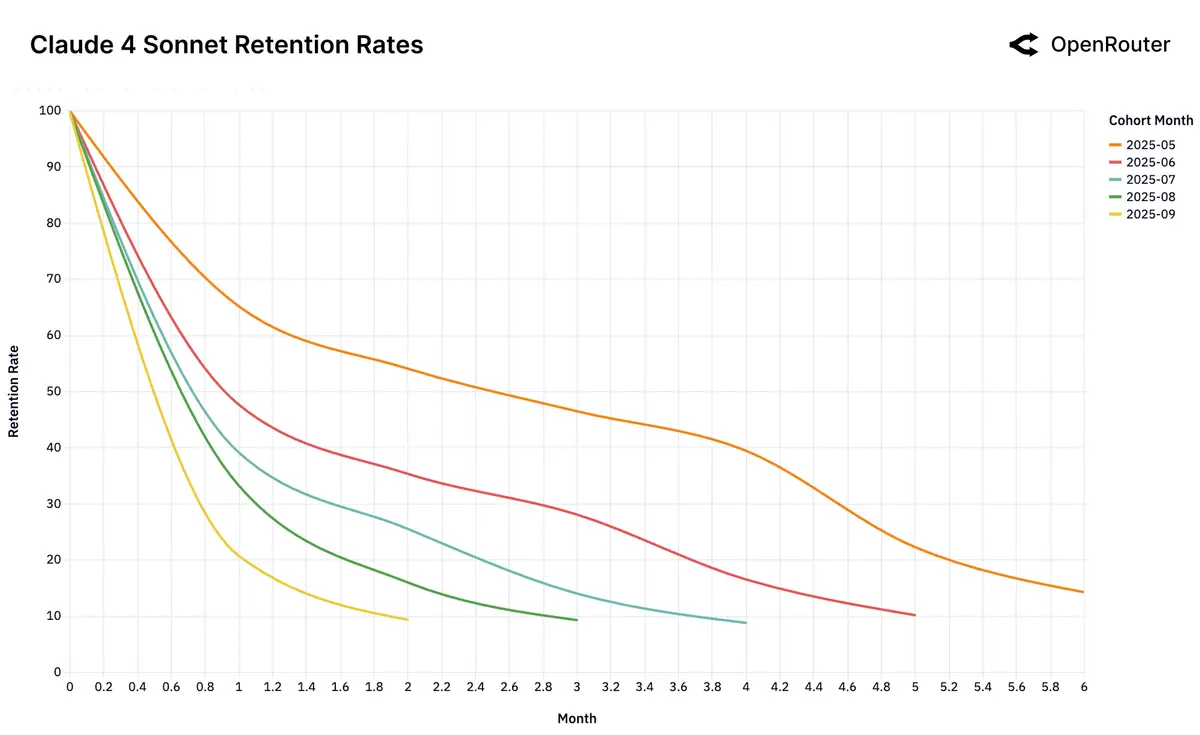
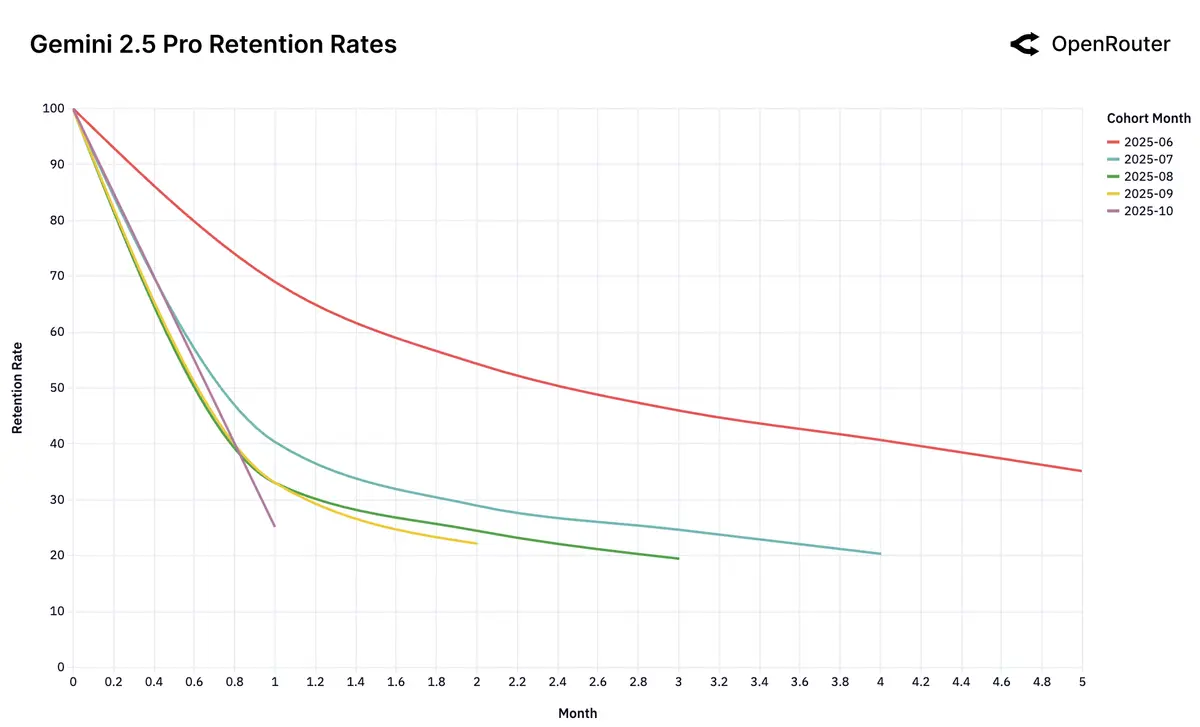
2025 年 6 月的 Gemini 2.5 Pro 和 2025 年 5 月的 Claude 4 Sonnet ,其对应的用户群体在第 4 个月约有 40% 的留存率,远高于其他模型,表明这两个模型具备先进性优势和独特用户价值:
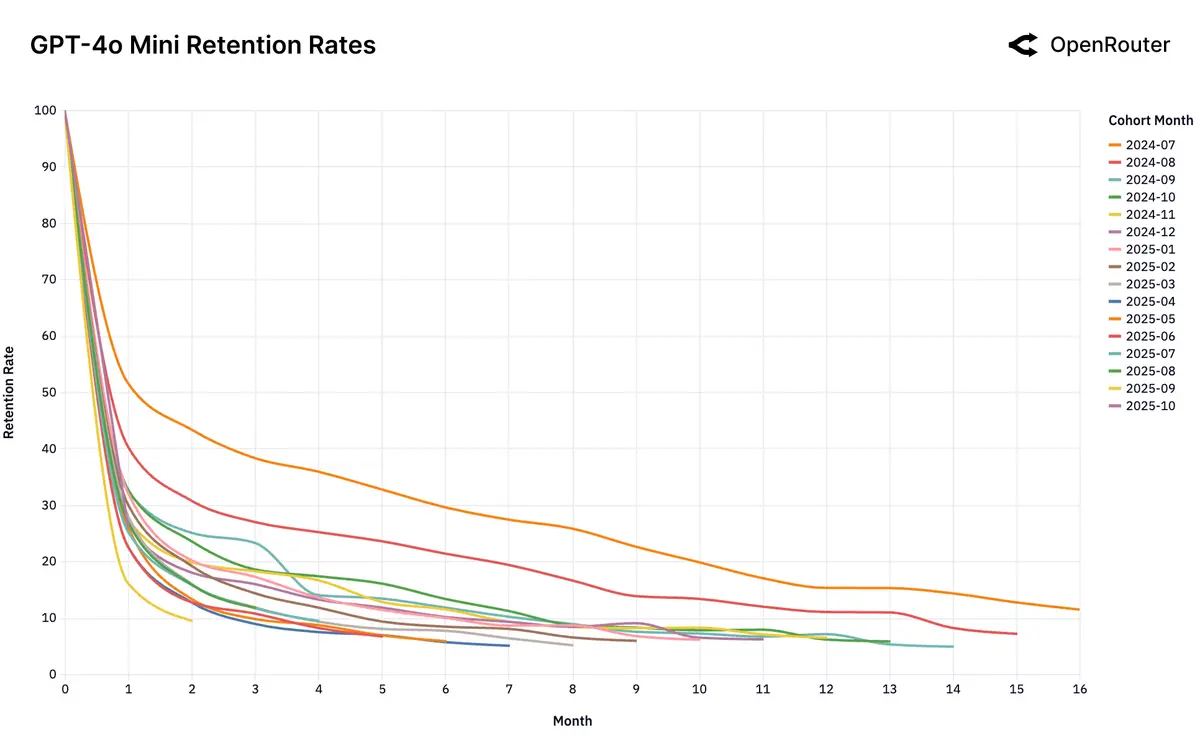
 而 GPT-4o Mini 就是特殊案例,靠着 OpenAI 早期积累的口碑,其早期的用户呈现较强的粘性(认可模型的“先进性”),但中后期加入的用户则逐月流失明显(模型的“先进性”认知逐渐褪去):
而 GPT-4o Mini 就是特殊案例,靠着 OpenAI 早期积累的口碑,其早期的用户呈现较强的粘性(认可模型的“先进性”),但中后期加入的用户则逐月流失明显(模型的“先进性”认知逐渐褪去):
Gemini 2.0 Flash 和 Llama 4 Maverick 作为反例,则是完全不具备先进性,因此用户流失一直很严重:
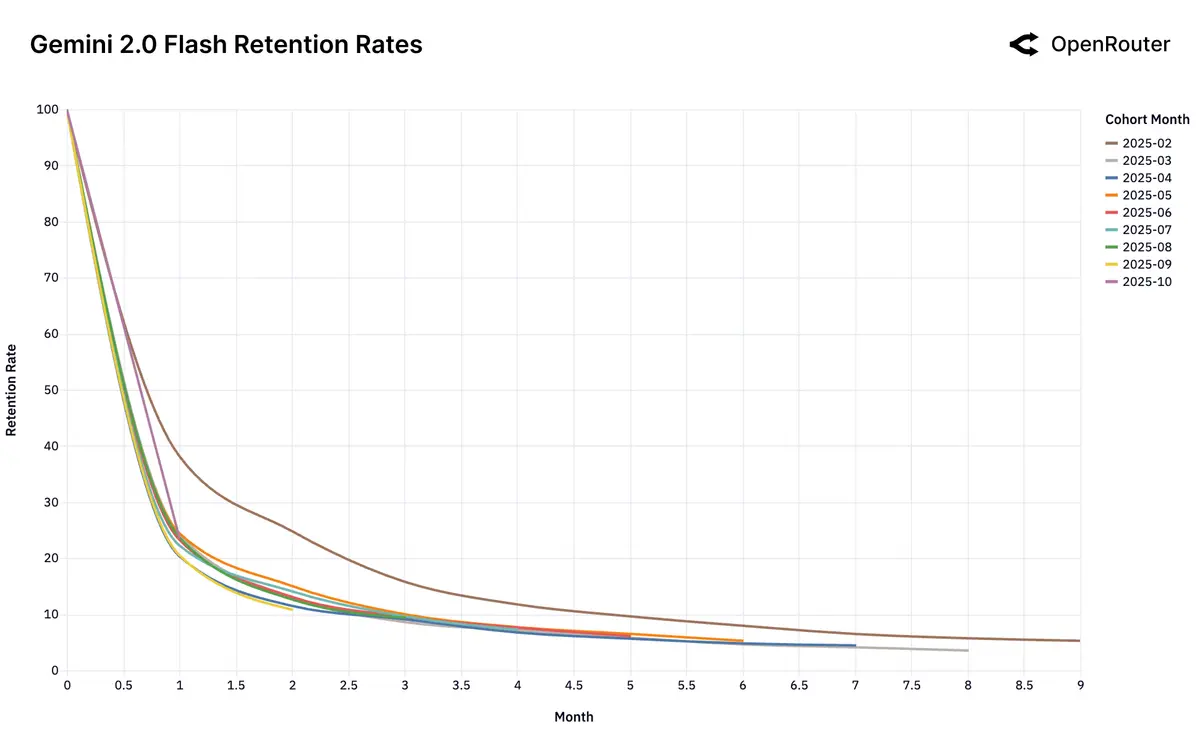
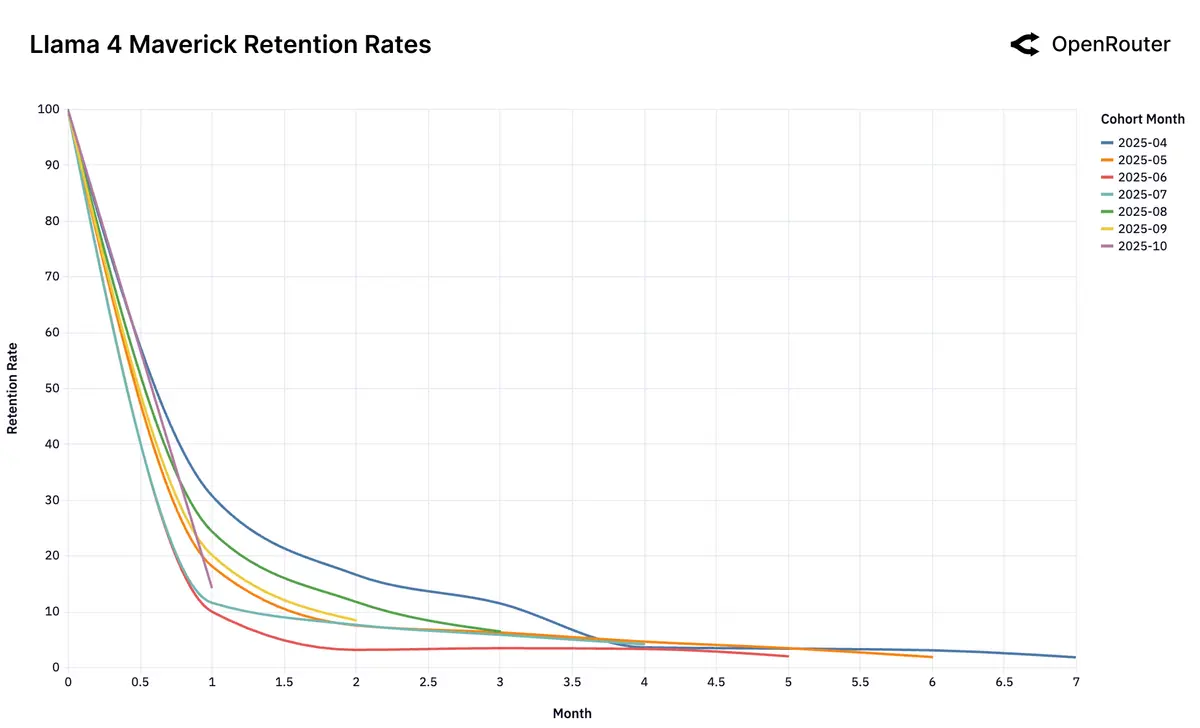
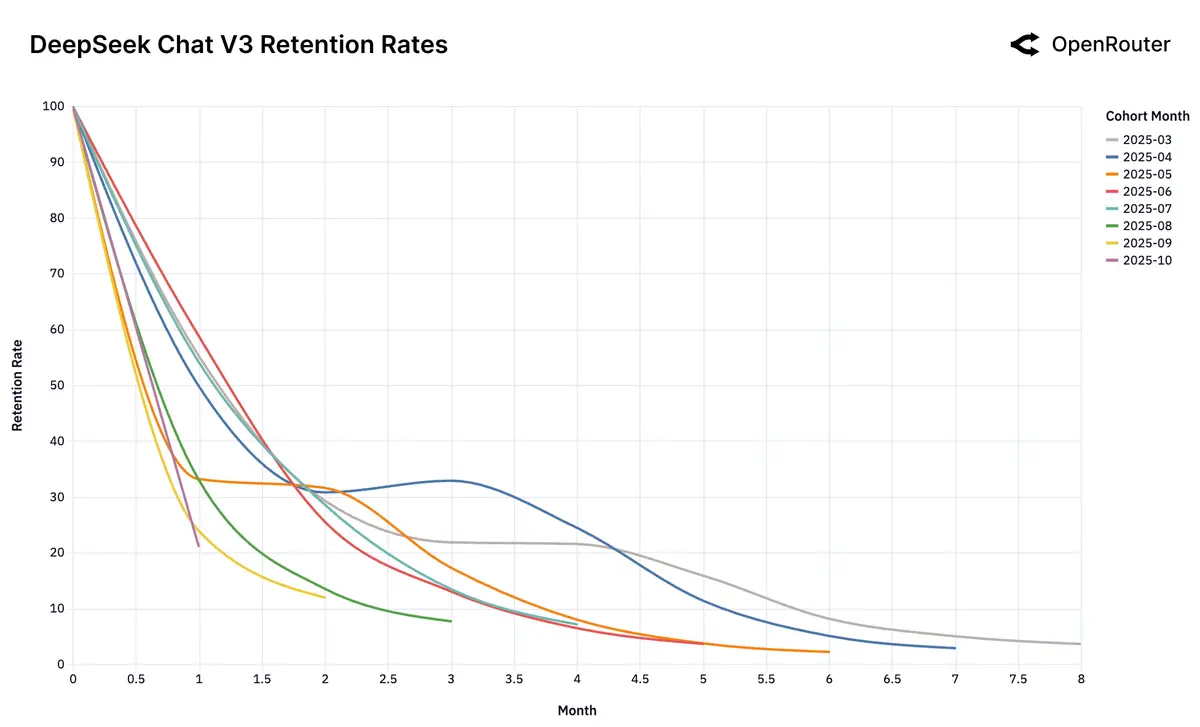
DeepSeek 则表现出更复杂的用户留存模式,其早期流失用户在一段时间后出现明显的回流现象;这类情况可能是舆论的影响,也可能说明了模型存在技术性能、成本效益或其他独特特性:
AI 成本与用量分析
按用途类别划分的 AI 成本与用量的四象限图:
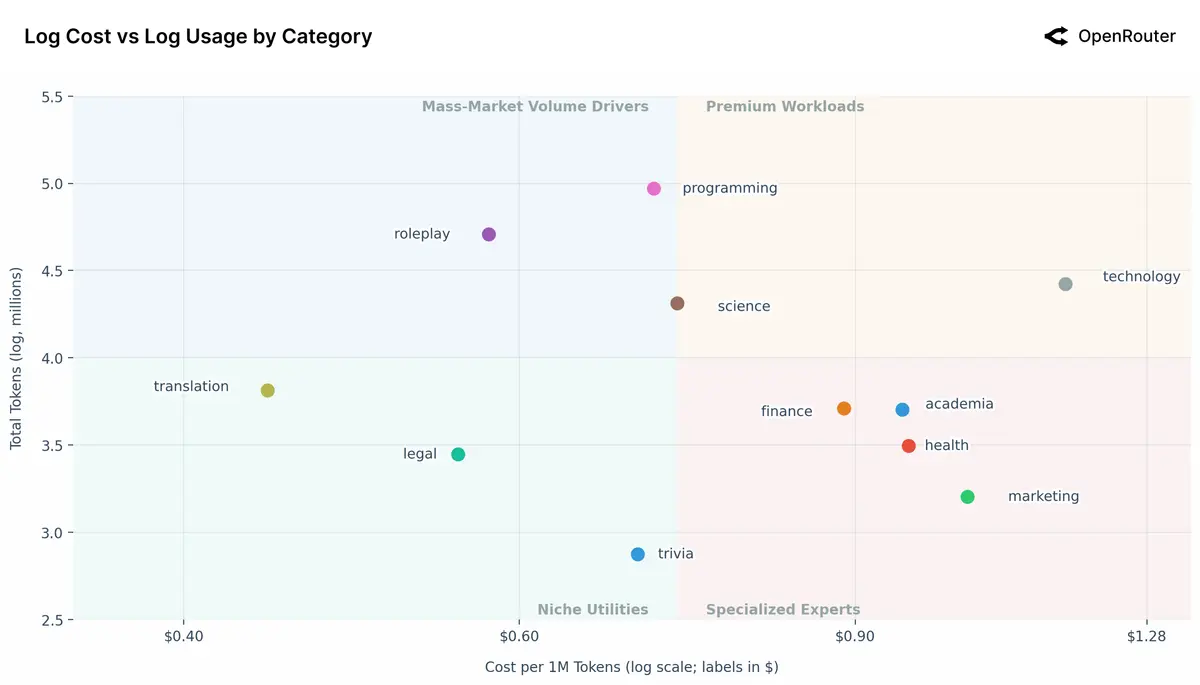
- 右上(高用量,高成本),主要包括科学和技术类用途,用户愿意为 AI 专业能力支付溢价
- 左上(高用量,低成本),覆盖了编程和角色扮演等更偏向大众化的消费场景,也对应着目前 AI 模型最主要的两个应用方向;开源模型在这类成本敏感型的场景中具备相对优势
- 右下(低用量,高成本),包括金融、学术、健康和市场营销等细分专业领域,对模型的稳定性和准确性要求高
- 右下(低用量,低成本),包括翻译、问答等小众实用的工具,容易会被更廉价的可靠方案所替代
按模型是否开源划分的 AI 成本与用量的四象限图:
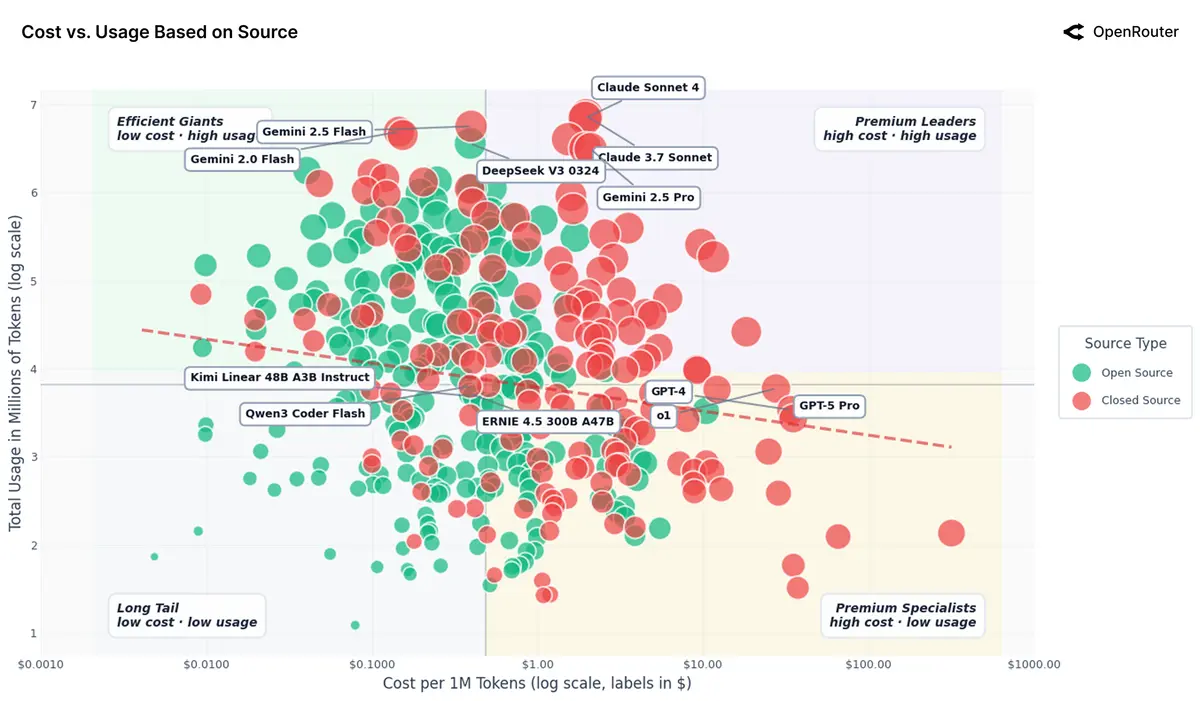
- 闭源模型趋向高成本高用量的象限,而开源模型则主导低成本、高用量的象限
- 拟合的趋势线几乎平坦(红色虚线),显示出成本与总用量之间的相关性有限
总结与讨论
- 生态活跃而用途丰富:不同厂商、不同用途的模型都保持多样性,市场竞争激烈,用户可选择性多
- Agent 的发展进步趋势明显,推理模型和工具调用的情况更加常见,AI 模型逐渐以任务完成为导向
- AI 的使用变得全球化和去中心化,中国开源模型成为 AI 生态重要组成,AI 需要更好的文化适用性
- 闭源模型不断推动模型的高效推理和前沿专业能力,捕捉高价值的工作负载;闭源模型则在计算质量和成本之间平衡,主导低成本和高用量的应用场景,推动整个市场的进步和趋同
- 在这个日新月异的市场中,只有能够率先实现创新性突破并解决用户痛点的模型,才能推动更深层、更广泛、更粘稠的用户采用,从而建立出优秀的用户留存曲线(衡量产品防御力的核心指标),并形成品牌的护城河