前置知识:因果推断入门
随机实验(Randomised Experiments)
- 将总体中的个体随机分配到实验组或对照组
- 随机化通过使潜在结果与治疗无关来消除偏差:$(Y_0, Y_1) \perp!!!\perp T$
- 因此随机实验可以直接得到平均因果效应 $ATE$ $$
ATE=E[Y|T=1] - E[Y|T=0] = E[Y_1 - Y_0] $$
常见的随机实验:
- 随机对照试验(RCT)是获得因果效应最可靠的方法,简单直接且极具说服力
- 在线对照实验(A/B Test)常用于互联网产品在线优化,快速、低成本比较版本差异
- 集群随机实验(CRT)以群体为最小干预单位的 RCT,常见于教育或政策评估
随机对照实验
随机对照试验(RCT),评估因果效应的金标准
RCT 的基本步骤
- 明确研究问题,设计干预方案与结局指标,评估样本量
- 对受试者进行严格的随机化分组,划分为实验组与对照组
- 对实验组的受试者进行干预,并收集所有受试者的结局指标
- 比较组间结局差异,并使用统计检验方法判断差异的显著性
单盲实验:受试者不知道分组信息,但是实验者知道分组信息 双盲实验:受试者不知道分组信息,实验者也不知道分组信息
RCT 的局限性:
- RCT 的问题在于其实验成本可能非常昂贵或违背道德
- 成本昂贵:比如在评估《估计信用额度对客户流失的影响》时,不能为银行客户提供完全随机的信用额度,这样的操作成本和代价会非常高
- 违背道德:比如在评估《怀孕期间吸烟对婴儿出生体重的影响》时,不能强迫一部分孕妇在怀孕期间吸烟,而天然吸烟的孕妇群体又可能是存在特定规律的(比如受教育水平更低或者经济水平偏低,而这些因素也是有可能影响到婴儿出生体重的)
- 因此许多 RCT 实验设计很难做到完全的随机化,也就得不到理想的实验结论
在线对照实验
在线对照试验 (Online Controlled Experiments),也称为 A/B 测试
A/B 测试基本步骤
- 确定需要测试的改动和预期提升的核心指标(如点击率、转化率)
- 设计测试方法,包括流量分割比例、受众筛选条件、实验时长等
- 将用户随机分流,分配到不同版本的产品,并进行灰度测试
- 监控核心指标和护栏指标(限制可能的负面影响,避免影响业务)
- 分析指标差异,包括显著性和效应值;决定是否全量发布或回滚
RCT 与 A/B 测试不存在显著区别,也存在术语混用的情况
集群随机实验
集群随机实验(CRT)
CRT 基本步骤
- 明确实验设计,寻找合适的随机化集群,并进行基线测量
- 对集群进行严格的随机化分组,划分为实验组和对照组
- 对实验组的集群(包含集群内的所有个体)进行干预
- 对实验组和对照组结果进行差异分析,注意考虑集群内相关性
CRT 的步骤和 RCT 基本一致,只是干预的目标从个体改为集群
随机实验示例 1
以一个简单的 A/B 测试为例
- 实验目的:分析线上/线下授课对学生成绩的影响
- 实验设计:(1)将学生随机划分为两组,一组进行线上授课,一组进行线下授课(2)记录两组学生在实验一段时间后的成绩(3)对比实验结果的差异并分析
- 差异分析方法(1)基于 z 统计量进行假设检验,H0 为两组结果的差异为零,当 p 值<0.05 时拒绝 H0(2)通过两组结果的置信区间对比来评估差异,需要指定置信水平(3)构建是否进行线上授课的 0-1 虚拟变量,通过线性回归得到虚拟变量的平均效应
Python 实现代码如下
import pandas as pd
import numpy as np
from scipy import stats
# 读取数据并随机分组
data = pd.read_csv("data/online_classroom.csv")
online = data.query("format_ol==1")["falsexam"]
face_to_face = data.query("format_ol==0 & format_blended==0")["falsexam"]
confidence=0.95, h0=0
mu1, mu2 = test.mean(), control.mean()
se1, se2 = test.std() / np.sqrt(len(test)), control.std() / np.sqrt(len(control))
diff = mu1 - mu2
se_diff = np.sqrt(test.var()/len(test) + control.var()/len(control))
# 基于z统计量进行假设检验,H0为两组结果的差异为零
z_stats = (diff-h0)/se_diff
p_value = stats.norm.cdf(z_stats)
def critial(se): return -se*stats.norm.ppf((1 - confidence)/2)
# 输出不同组别的置信区间和最终的假设检验结果
print(f"Test {confidence*100}% CI: {mu1} +- {critial(se1)}")
print(f"Control {confidence*100}% CI: {mu2} +- {critial(se2)}")
print(f"Test-Control {confidence*100}% CI: {diff} +- {critial(se_diff)}")
print(f"Z Statistic {z_stats}")
print(f"P-Value {p_value}")
# 通过线性回归直接估计虚拟变量(是否线上授课)的平均因果效应
result = smf.ols('falsexam ~ format_ol', data=data).fit()
result.summary().tables[1] # 系数为负,表示线上授课对成绩存在负面影响
在实际操作过程中,可以引入更多的混淆变量(对因果变量都存在影响的变量)来修正平均因果效应 ATE 的估计;其他优化技巧可参阅回归内生性问题
随机实验示例 2
对 2 家医院进行药物疗效实验
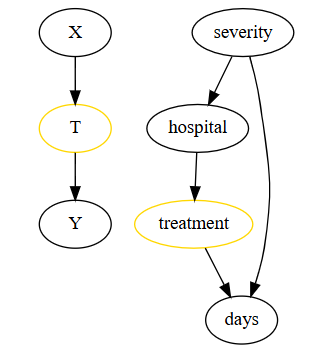
- 医院 A 的随机分组策略:90% 的患者接受药物治疗,10% 的患者接受安慰剂
- 医院 B 的随机分组策略:10% 的患者接受药物治疗,90% 的患者接受安慰剂
- 实验目的:新药物治疗(treatment)是否能有效减少患者的住院天数(days)
- 单因素分析阶段,发现治疗会增加住院时长(反直觉),深入分析后发现是因为医院 A 相比于医院 B 通常会接收病情更严重的患者,而医院 A 的药物治疗占比也更高,因而导致了错误的结论
- 合理思路:将病情严重程度(severity)作为混淆变量纳入模型,显著改善预测效果,同时得到新结论:治疗(treatment)会减少住院时长
- 不合理思路:将医院类型(hospital)作为变量纳入模型,结果变差;而 hospital 作为治疗的预测因子,与住院时长是不直接相关,因此将其纳入模型会增加治疗效果的估计误差
合理的混淆变量必须同时影响干预和结果;severity 满足这一点,hospital 不满足
随机实验示例 3
分析催收邮件对客户还款行为的影响
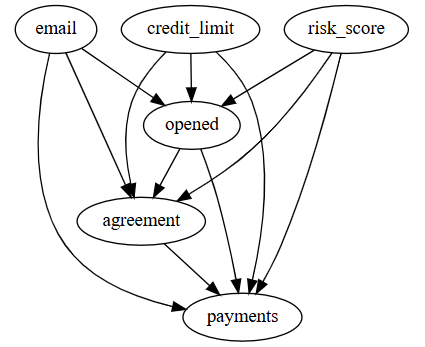
- 对 5000 位欠款客户进行随机分组,实验组会收到还款提醒的邮件
- 实验目的:通过催收邮件(email)是否能增加欠款客户的还款金额(payments)
- 单因素分析阶段,发现催收邮件会减少还款金额(反直觉),深入分析后发现是因为影响还款金额的因素太多,而催收邮件的影响较小,因此存在较大的估计误差
- 合理思路:将客户的信用额度(credit_limit)和风险评分(risk_score)作为补充特征,纳入模型;最终预测结果得到明显改善,而新的 ATE 估计方差也小了很多
- 不合理的思路:将客户点击(opened)和客户同意(agreement)作为补充特征,纳入模型;中介特征是指在因果图中处于干预到结果之间的路径中的特征节点,将其纳入模型会导致选择偏差
当一个特征是结果的有效预测因子,即使它不是混淆变量(同时影响干预和结果),将其纳入模型也是有好处的,能明显降低干预效果的估计方差