因果推断基础
辛普森悖论 提醒我们在分析数据时要仔细考虑分组和混杂因素的影响,而因果推断的作用就是使用适当的方法识别和控制这些因素,从而可以更好地解释数据中的关系,并做出可靠的结论。
相关性与因果性:
- 相关性描述了事物之间存在的关联,因果性则代表了事物之间的内在联系
- 不同于相关性,因果性一般是单向的,即 A 是 B 的因,B 就不应该是 A 的因
- 传统模型一般学习的只是相关性,这也是导致模型泛化能力不足的重要原因
偏差项是导致关联性不等同于因果关系的重要因素 $$ E[Y|T=1] - E[Y|T=0] = \underbrace{E[Y_1 - Y_0|T=1]}_{ATT} + \underbrace{{ E[Y_0|T=1] - E[Y_0|T=0] }}_{BIAS} $$
- $T$ 表示干预方案,$T=1$ 表示进行干预;$Y_{1}$ 表示存在干预下的结果
- 上式左侧描述的是关联性测量,即实验组结果与对照组结果间的差异
- 右侧 $ATT$ 描述了实验组的实验效应,即实验组干预前后的结果变化
- 偏差项 $BIAS$ 表示实验组和对照组在未接受干预的情况下的差异
- 理想情况下,实验组和对照组在干预前是完全一致的($BAIS=0$),则在对实验组进行干预后,两组结果的差异(关联性)描述了干预对结果的因果效应(因果性)
当 $E[Y_0|T=0]=E[Y_0|T=1]$ 时,表示对照组结果等于实验组的反事实结果,也就意味着没有偏差($BAIS=0$),此时关联性就转化为因果关系
偏差项
因果关系的三个阶段(由易到难):
- 关联性 Associational:传统 ML 任务,根据输入 X 预测输出 Y
- 干预性 Interventional:预测干预效果,根据动作 X 预测效果 Y
- 反事实 Counterfactual:对“已经发生”的事件,进行干预效果的想象
因果推断的三类任务:
- 因果效应评估(Causal Effect Estimatation):从数据中推断一个变量对另一个变量的影响程度
- 因果关系发现(Causal Discovery):从数据中识别出变量之间的因果关系
- 因果纠偏:通过因果的手段对数据或者模型进行处理,去除偏差的影响
因果推断的框架
因果推断的两个主流框架
- 潜在结果框架(Potential Outcome Framework)
- 结构因果模型(Structural Causal Model,SCM)
潜在结果框架 POM
潜在结果框架(Potential Outcome Framework):
- 通过学习因果效应(causal effect)来确定某个具体的干预(Treatment)对应的结果(Outcome)的变化,估计不同干预下的潜在结果(包括反事实结果),以估计实际的干预效果
- 主要用于解决因果效应评估,研究“因”的改变能带来多少“果”的变化
- 淡化/忽略了因果关系,强调因果效应的评估,适用于变量较多的复杂场景
下文将以医学实验为例,对潜在结果框架进行说明
符号定义:
- $T$ 表示干预方案,$X$ 表示混淆变量, $Y(t)$ 表示干预效果
- 第 $i$ 个患者施加干预方案($T=1$)后的结果为 $Y_{i}(1)$
- 第 $i$ 个患者不施加干预方案($T=0$)后的结果为 $Y_{i}(0)$
潜在结果框架的前提假设:
- 可交换性(Exchangeability,Ignorability);可交换性意味着在没有干预的情况下,干预组和对照组的潜在结果是相同的,即如果将干预组和对照组的个体交换,他们的结果不会改变
$$(Y(1),Y(0))\perp \! \! \!\perp T$$ 2. 条件可交换性(Conditional Exchangeability,Unconfoundedness);由于可交换性假设在现实世界很难满足,因此对其弱化而提出的条件可交换性,即假设干预方案 T 和结果 Y 之间是互相独立的 $$(Y(1),Y(0))\perp \! \! \!\perp T|X$$ 3. 正值假设(Positivity/Overlap and Extrapolation);拥有不同的混淆变量 X 的分组,干预方案 T 所获得的结果是一定的;该假设是为了确保不同类型的人群的干预效果都可以被观察到,避免极端外推 $$0<P(T=1\mid X=x)<1,\forall x\in X$$ 4. 无干扰假设(No Interference):个体的治疗不会影响其他个体的结果 $$Y_{i}\left(t_{1},\ldots,t_{i-1},t_{i},t_{i+1},\ldots,t_{n}\right)=Y_{i}\left(t_{i}\right)$$ 5. 一致性假设(Consistency):治疗 T 和潜在结果 Y 是一致对应的 $$T=t\Longrightarrow Y=Y(t)$$
第 $i$ 个患者的因果效应 individual treatment effect (ITE) $$\tau_{i}\triangleq Y_{i}(1)-Y_{i}(0)$$
干预方案的平均因果效应 average treatment effect (ATE) $$\tau\triangleq\mathbb{E}[Y_{i}(1)-Y_{i}(0)]=\mathbb{E}[Y_{i}(1)]-\mathbb{E}[Y_{i}(0)]$$
ATE 有时也叫做 ACE(average causal effect)
需要注意, $E[Y_{}i(1)]−E[Yi(0)]$ 是一个因果量,而 $E[Y|T=1]−E[Y|T=0]$ 是一个关联量,他们二者是不等价的
ATE 的计算依赖于以上假设,将因果表达式转化成统计表达式: $$\begin{array}{r l}{A T E=\mathbb{E}_{X}[\mathbb{E}[Y\mid T=1,X]-\mathbb{E}[Y\mid T=0,X]]} \\ {={\displaystyle{\frac{1}{n}}}\sum_{i}\left[\mathbb{E}\left[Y\mid T=1,X=x_{i}\right]-\mathbb{E}\left[Y\mid T=0,X=x_{i}\right]\right]}\end{array}$$ 而 $\mathbb{E}\left[Y\mid T=t,X=x_{i}\right]$ 则一般依赖传统机器学习模型来实现预测
结构因果模型 SCM
结构因果模型(Structural Causal Model,SCM):
- 通过构建关键要素的因果图,结合结构方程来描述变量之间的因果关系
- 主要用于解决因果关系发现问题,也可以定量地进行因果效应评估
- 因果关系直观,结果置信度高,但不适合变量较多、关系复杂的情况
概率图 VS 因果图
- 概率图模型 通过图结构的形式来研究随机变量之间的关系,是统计模型
- 因果图通过有向无环图的方式来建模变量之间的因果关系,是因果模型
- 因果模型的很多算法可以直接借鉴概率图,比如概率图的有向图模型/贝叶斯网络
因果图的假设:
- 局部马尔可夫假设(Local Markov Assumption):给定节点 X ,假定其父母节点为 P,那么 X 和所有非 P 后代节点都是独立的
- 严格的因果边假设(Causal Edges Assumption):在有向图中,由父节点指向子节点的所有边都代表了父节点是子节点的一个因(cause);非严格的因果边假设将允许一些父节点可以不是其子女的因(cause)
有向无环图(Directed Acyclic Graph,简称 DAG)的因果性

- 对于链结构(Chain)和叉结构(Fork),$X_{1}$ 和 $X_{3}$ 之间存在因果关系
- 对于 immorality 结构,$X_{1}$ 和 $X_{3}$ 之间是独立的,二者不存在因果关系;但给定 $X_{2}$ 的取值后,$X_{1}$ 和 $X_{3}$ 之间就不是独立的,二者之间的因果路径(cause path)也就从阻塞(block)变为了非阻塞(unblock)
变量间的相关性只会在非阻塞的因果路径中传递
结构方程可用于表示因果关系或因果图(有向无环图 DAG),以吸烟 X 和肺癌 Y 的关系为例,同时考虑年龄 Z 作为混淆变量,则对应因果图为:
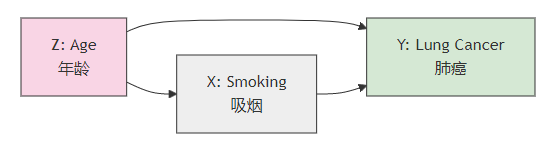
- $Z \to X \to Y$:年龄影响吸烟习惯,吸烟导致肺癌
- $Z\to Y$:年龄也直接影响到肺癌发生的风险
该因果图对应的结构方程可以表示为: $$\begin{array}{r}{X=f_{X}(Z,U_{X})} \\ {Y=f_{Y}(X,Z,U_{Y})}\end{array}$$
- 其中 $f$ 是某种确定性函数(可以是非线性的),表示因果机制
- 变量 $X,Y,Z$ 的集合统称为内生变量,函数 $f$ 负责他们之间的映射
- 变量 $U$ 用来表示未观测因素,也被称为噪声或外生变量
概念补充 1:d-分割(d-separation)
- 定义:对于两个节点 (的集合) X 和 Y,如果存在一个节点集合 Z,使得 X 和 Y 之间所有的路径都被 Z 所阻塞,那么 Z 就是 X 和 Y 的一个 d-分割
- d-分割可以表示两个 (两组) 变量之间的独立性关系
概念补充 2:do-算子(do-operator)
- 定义:$do(X=x)$ 表示对系统进行干预,强制将变量 $X$ 的值设置为 $x$
- 以吸烟和肺癌的因果模型为例,$P(Y|do(X=1))$ 表示强制让所有人吸烟后肺癌的概率,而 $P(Y|X=1)$ 则表示观察到吸烟的人中肺癌的概率
- do-算子能通过模拟干预,来实现干预分析和反事实推断
概念补充 3:后门路径(Backdoor Path)
- 定义:指从因果关系的起点(例如 X)到终点(例如 Y)的所有路径中,除了直接的因果路径外,还存在其他可能引入混淆的路径
- 以吸烟和肺癌的因果模型为例,$X\rightarrow Z\leftarrow Y$ 就是一条后门路径,该路径中 $Z$ 会同时影响 $X$ 和 $Y$,可能导致错误归因;比如说分组 A 相比于分组 B 的吸烟率更高,但肺癌率更低,这可能是因为分组 A 对应的人群,相比于分组 B 的人群更年轻
概念补充 4:后门准则(Backdoor Criterion)
- 定义:通过识别并阻断后门路径的影响,从而正确的估计因果效应
- 以吸烟和肺癌的因果模型为例,为了阻断 $Z$ 对应的后门路径,需要不断调整 $Z$ 的取值来进行分层分析(即需要考虑不同年龄段情况下,吸烟与肺癌的关系),具体计算如下:
$$P(Y\mid d o(X=x))=\sum_{z}P(Y\mid X=x,Z=z)P(Z=z)$$
因果关系发现算法
常见的因果关系发现类算法:
利用因果图中节点之间的条件独立性来推断因果关系
- 条件独立性测试:通过统计检验来判断变量之间的条件独立性关系
- PC 算法:这是一个经典的基于条件独立性的算法。它通过一系列的条件独立性测试来逐步构建因果图。首先构建一个完全连接的无向图,然后逐步删除边以反映条件独立性,最后确定边的方向
- IC(Inductive Causation)算法:也利用条件独立性测试来推断因果关系
通过定义评分函数来寻找因果图,即评分函数最大的有向无环图(DAG)
- 贝叶斯信息准则(BIC)评分:结合似然函数和模型复杂度来评估因果图的质量
- 最大似然估计(MLE)评分:直接使用似然函数作为评分标准,寻找似然函数最大的 DAG
- 结构学习算法:如贪婪等价搜索(GES)算法,通过在因果图空间中搜索来优化评分函数
通过引入更多的假设信息来推断因果关系
- 加性噪音模型(ANM):假设两个变量之间的关系可以表示为一个函数加上噪音项,即 $Y = f(X) + N$,其中 $N$ 是独立于 $X$ 的噪音。通过这种假设,可以推断出因果方向。
- 非线性因果分析:利用非线性模型来捕捉变量之间的因果关系,适用于线性方法无法处理的复杂关系
- 信息论方法:如利用互信息或条件互信息来推断因果关系。
因果效应评估算法
因果效应评估算法分类
一、黄金标准:1_study/CausalInference/随机实验
二、基于“可观测变量”的方法 (Selection on Observables)
- 适用场景:所有影响结果和分组的因素(混淆变量)都已经在数据里
- 比如倾向得分匹配法 PSM、熵平衡、双重稳健估计
三、基于“不可观测变量”的方法 (Selection on Unobservables)
- 适用场景:数据中存在被遗漏或无法直接控制的混淆变量
- 比如1_study/algorithm/回归算法进阶/回归内生性问题 #3 双重差分法 DID、工具变量法 IV、合成控制、断点回归
四、其他进阶方法
- 结构因果类的模型:基于因果关系构建模型,如因果图或结构化方程
- 元学习:通过调整 treat 来观察结果,直接估计条件平均干预效果(CATE)
- 树形方法:通过构建树状结构来分裂样本,使得左右节点上的因果效应差异最大化
- 因果表征:将人群进行表征学习,并消除混淆因素和保存 treat
因果推断的算法假设
独立性假设:对实验组/对照组的分配,应该与潜在结果相互独立;即探究城市存款额与银行广告投放之间关系时,不能只在存款额较高的城市进行广告投放
平行趋势假设:对实验组/对照组的分配,应该与潜在结果随时间的增长无关;即探究城市存款额与银行广告投放之间关系时,可以只在存款额较高的城市进行广告投放,不能只在存款额增速较快的城市进行广告投放
条件无混杂性:所有混杂因素都必须已知且可测量,这样的条件化处理效果才能接近随机化
不同方法的前提假设:
- 双重差分法 DID 只需要满足平行趋势假设,而不需要满足独立性假设
- 子分类估计器或倾向得分匹配法 PSM 需要同时满足独立性假设和条件无混杂性
- 当条件无混杂性不满足时,可以考虑工具变量法 IV
- 对于面板数据,算法依赖的条件无混杂性可以弱化为平行趋势假设
因果推断的总结
现实挑战:
- 因果关系在很多场景中很弱,甚至和随机噪声处于同一量级,建模难度大
- 算法的前提假设很难满足,缺少充足的随机测试数据,存在未观测到的混杂因素
- 当面对多个处理方案时,如何合理分配资源也成为了一个复杂的问题
- 预测预测的影响因素很多,而这些影响因素还与处理方案相关联
- 某些场景下模型的评价测试周期长,很难在上线前实现对模型效果的充分评价
未来趋势:
- 借助大规模的学习来处理更复杂的非线性关系,比如元学习或多任务学习
- 因果表征通过从因果关系的角度理解数据生成过程,更符合真实世界的因果机制
- 强调表征学习中的解耦和模块化思想,实现模型更好的可迁移性和泛化能力
- 寻找通用性更强、适用多领域的算法模型,降低实际应用场景下的模型落地门槛
进阶阅读:
其他参考:
因果推断两大算法框架解析
Causality05-StructuralCausalModel
因果推断综述及基础方法介绍(二)
因果推断(一):因果推断两大框架及因果效应