1 背景知识
本文内容主要摘自:
《Is something better than pandas when the dataset fits the memory?》
代码地址
性能对比主要围绕5个操作展开:
- 读取700M CSV文件:load_transactions
- 读取30M CSV文件:load_identity
- 基于某列(string格式)进行merge操作:merge
- 分别对六列数据进行聚合操作(sum,mean):aggregation
- 对merge后的数据进行排序操作:sorting
后续分析不考虑内存不足的情况:
2 Pandas VS Dask
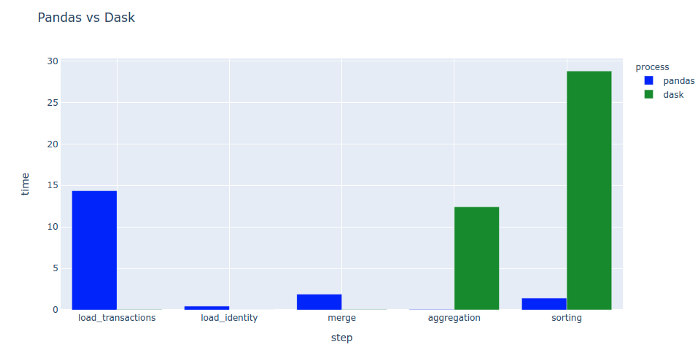 Dask的读取优势主要由于其预加载机制导致的,可以很好地避免内存溢出的情况。除了对并行化有更好地支持外,在聚合与排序方向没有很明显的优势。
Dask的读取优势主要由于其预加载机制导致的,可以很好地避免内存溢出的情况。除了对并行化有更好地支持外,在聚合与排序方向没有很明显的优势。
3 Pandas VS PySpark
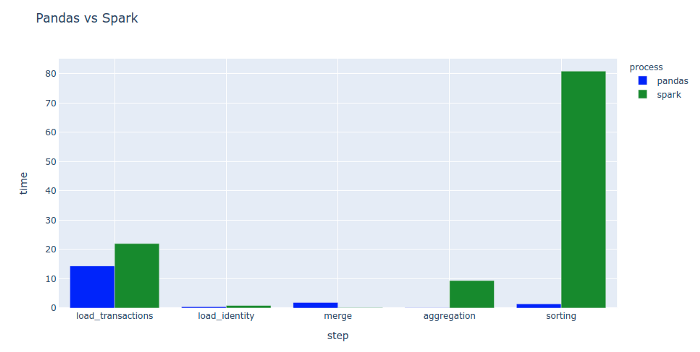
PySpark主要为分布式计算设计,在小规模数据中并不存在明显优势
4 Pandas VS Vaex
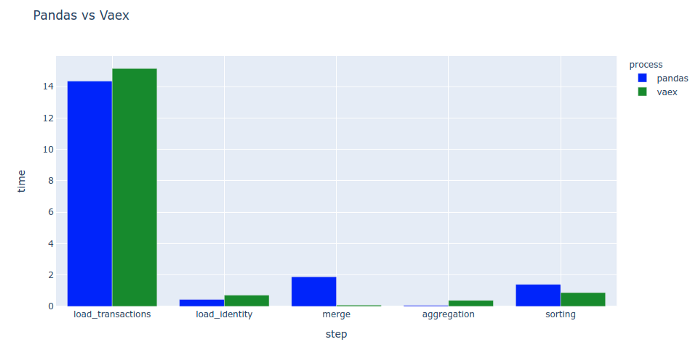
Vaex在某些基础数据分析方面可能存在优势
5 Pandas VS Julia
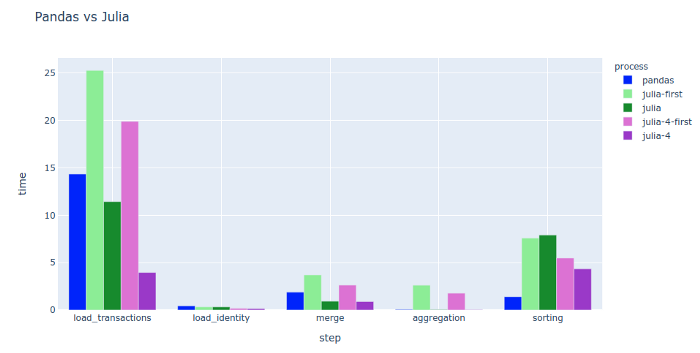
Julia是一种在数据科学界颇受欢迎的编译语言,所以在首次运行代码时会进行即时编译,所以需要多次对比取平均值,同时作者也尝试了在4核处理器上的运行结果(默认是单核)。最终结果不存在明显优势,但是多核处理方面可能确实有出彩之处。
6 结论
Pandas 模块暂时还是没有足够优秀的替代品~
补充
不同读取 csv 文件方式的效率对比(Python 脚本):
| Description | File / Function | Time (seconds) |
|---|---|---|
| Pure Python looping with csv module using int types | pure_python_int | 3.4547557830810547 |
| Pure Python looping with csv module using float types | pure_python_float | 3.8738009929656982 |
| pandas with C engine | pandas_c | 1.50089430809021 |
| pandas with Python engine | pandas_python | 8.328583478927612 |
| pandas with PyArrow engine and NumPy dtypes | pandas_pyarrow | 0.31276631355285645 |
| pandas with PyArrow engine and PyArrow dtypes | pandas_pyarrow_arrow | 0.29172492027282715 |
| Polars in lazy mode | polars_lazy | 0.10555672645568848 |
| Polars in streaming mode | polars_streaming | 0.11504125595092773 |
| Polars with SQL API | polars_sql | 0.09796714782714844 |
| DuckDB with SQL API | duckdb_sql | 0.8167853355407715 |
| DataFusion with SQL API | datafusion_sql | 0.20633697509765625 |
| NumPy with loadtxt function | numpy_loadtxt | 1.8354885578155518 |
- 从默认的 C 引擎更改为使用 PyArrow 引擎(C++ 实现的多线程 CSV 解析)可使任务速度提高 5 倍,但也会使 pandas 的安装大小增加了约 100 Mb
- DuckDB 是一个不需要运行服务器的分析数据库(通常称为分析的 SQLite)。 Datafusion 是一个在其上构建分析数据库或数据框架库的引擎。 Polars 主要是 pandas 的替代品,但总的来说速度更快