中文标题:基于USMLE评估大规模语言模型ChatGPT在AI辅助医学教育的潜力
英文标题:Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models
发布平台:PLOS Digit Health
发布日期:2023-02-09
引用量(非实时):17
DOI:10.1371/journal.pdig.0000198
作者:Tiffany H. Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, Victor Tseng
文章类型:journalArticle
品读时间:2023-02-21 22:44
1 文章萃取
1.1 核心观点
- 本文评估了大规模语言模型 ChatGPT 在美国医学执照考试 (USMLE) 中的表现,发现在没有任何专门的训练或强化下,ChatGPT在其中是三项考试中均达到或接近60%准确度(也是正常情况下人类的及格水平)。
ChatGPT 展示了可理解的推理和有效的临床见解,很可能在医学教育环境中帮助人类学习者,并作为未来融入临床决策前奏
1.2 综合评价
- 验证过程较为严谨,但对测试样本独立于ChatGPT的训练集这一点存疑
- 相关测试样本与结果均开源(在原论文附录中),结果的可靠性较高
- ChatGPT配合不同的提示工程所能发挥的效果上限不同,结果存在改善空间
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
目前临床护理应用的局限性
- 文本信息混杂,缺少规范化约束
- 卫生IT系统之间沟壑较多,协通不便
- 算法所需的结构化数据匮乏,质量不一
- 模型开发周期长,成本高,需要特定领域的数据
美国医学执照考试 (USMLE):
- 一项对医学执业影响深远的综合性三阶段的标准化考试计划
- 涵盖医师所需的全部知识范围:基础科学、临床推理、医疗管理和生物伦理学
- 问题的难度和复杂性经过高度标准化和规范后,成为人工智能测试的理想输入基板
USMLE的三个阶段:
- Step 1考试通常由完成两年理论教学和问题导向学习的医学生参加,主要关注基础科学、药理学和病理生理学
- Step 2 CK考试通常由已完成1.5到2年临床轮转的四年级医学生参加,主要关注临床推理、医疗管理和生物伦理学
- Step 3考试由通常已完成至少0.5到1年研究生医学教育的医师参加。
ChatGPT,OpenAI推出的通用大语言模型
2.2 数据和方法
数据源说明:USMLE-2022
- 摘自 2022 年 6 月发布的样本考试中的376 个公开试题,可从 USMLE 官方网站获得。
- 确保所有输入均为 ChatGPT 模型的训练外样本。(ChatGPT 训练数据集可访问的最后日期是2022 年 1 月 1 日,通过抽样确保在这之前没有任何答案、解释或相关内容被谷歌索引)
- 删除包含临床图像、医学摄影和图表等包含视觉信息(ChatGPT不支持)的问题
- 过滤后,最终保留了350 道 USMLE 题目(Step 1:119,Step 2CK:102,Step 3:122)
题目的三种编码:
- 开放式 (OE) 提示:通过删除所有答案选项,添加可变的疑问句来创建。这种格式模拟自由输入和自然的用户咨询。示例包括:“根据所提供的信息,患者的诊断是什么?”;或者“在您看来,患者瞳孔不对称的原因是什么?”
- 多选单选题(MC-NJ)提示,无需强制性解释:通过逐字复制原始USMLE问题创建。示例包括:“以下哪项代表最合适的下一步管理措施?”;或“患者病情主要是由以下哪种病原体引起的?”
- 多选单选题(MC-J)提示,需要强制性解释:通过添加可变的引导式命令或疑问句来创建,要求 ChatGPT 为每个答案选项提供理由。示例包括:“以下哪项最可能是患者出现夜间症状的原因?解释每个选项的理由”;或“对该患者最合适的药物治疗最有可能通过以下哪种机制起作用?为什么其他的选择都不对?”
每个题目都会进行三种编码,并进行结果的差异性(ANOVA,方差分析)评估;在提示中创建可变的命令或疑问句,避免措辞严格或固定引起的系统错误;实际测试时,每个题目都会启动一个独立的聊天会话;
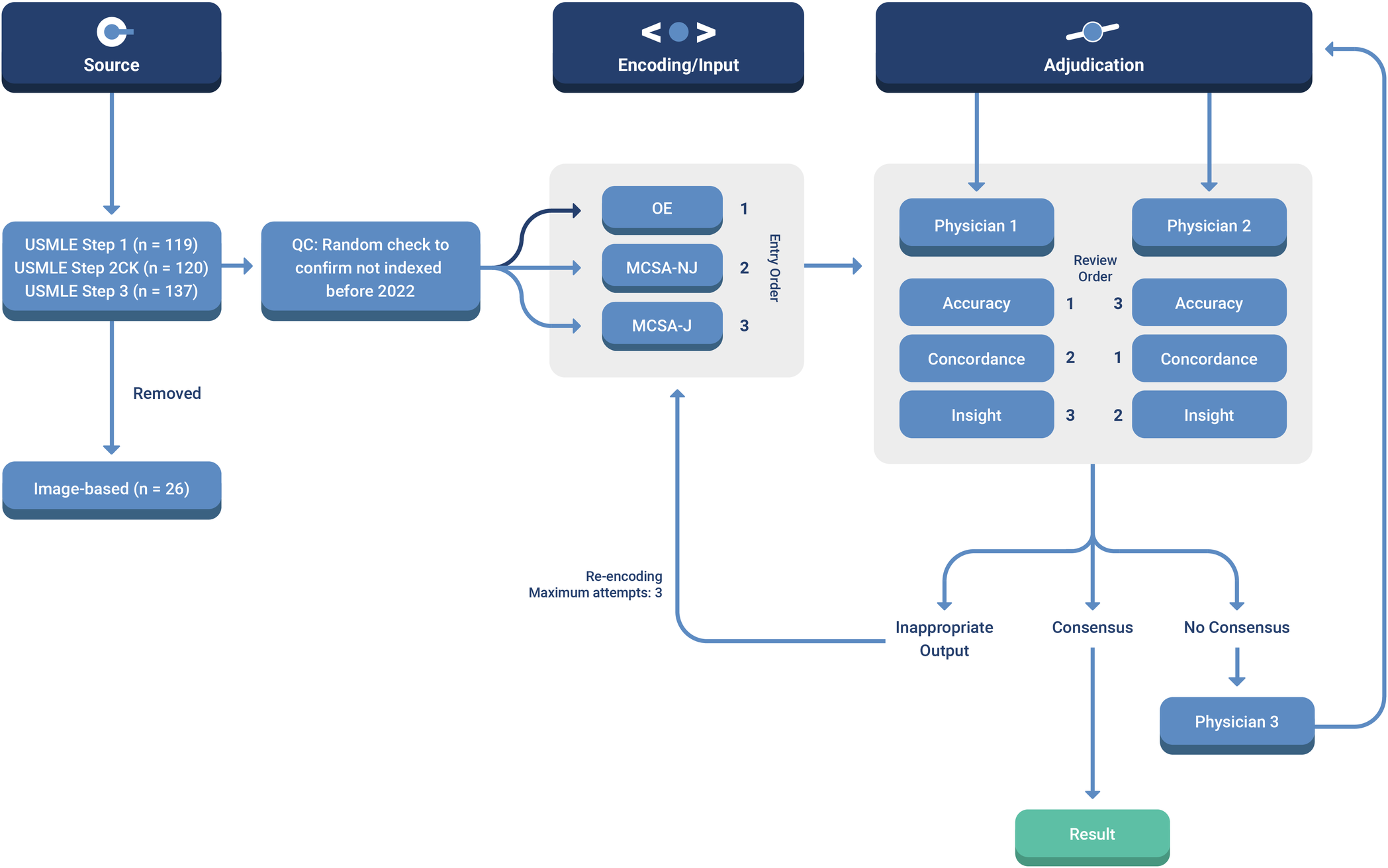 结果的裁定:
结果的裁定:
- AI 输出的准确性、一致性和洞察力 (ACI) 由两名医师评审员进行独立评分
- 20 个 USMLE 问题的子集用于裁判员培训。医生并没有对这个子集设盲,但通过强制交错审查输出措施来抑制评估者之间的交叉污染。(例如,医师 1 判定准确性,而医师 2 判定一致性。然后轮换角色,以便每个题目都得到完整的评价)
- 如果所有三种评分没有达成共识,则该项目将提交给最终的医师裁决员。最终有 21 道题目(占数据集的 6.2%)需要第三位医生进行仲裁
一致性通过计算OE和MC问题的模型评价#1.4 kappa值进行评
2.3 结果和分析
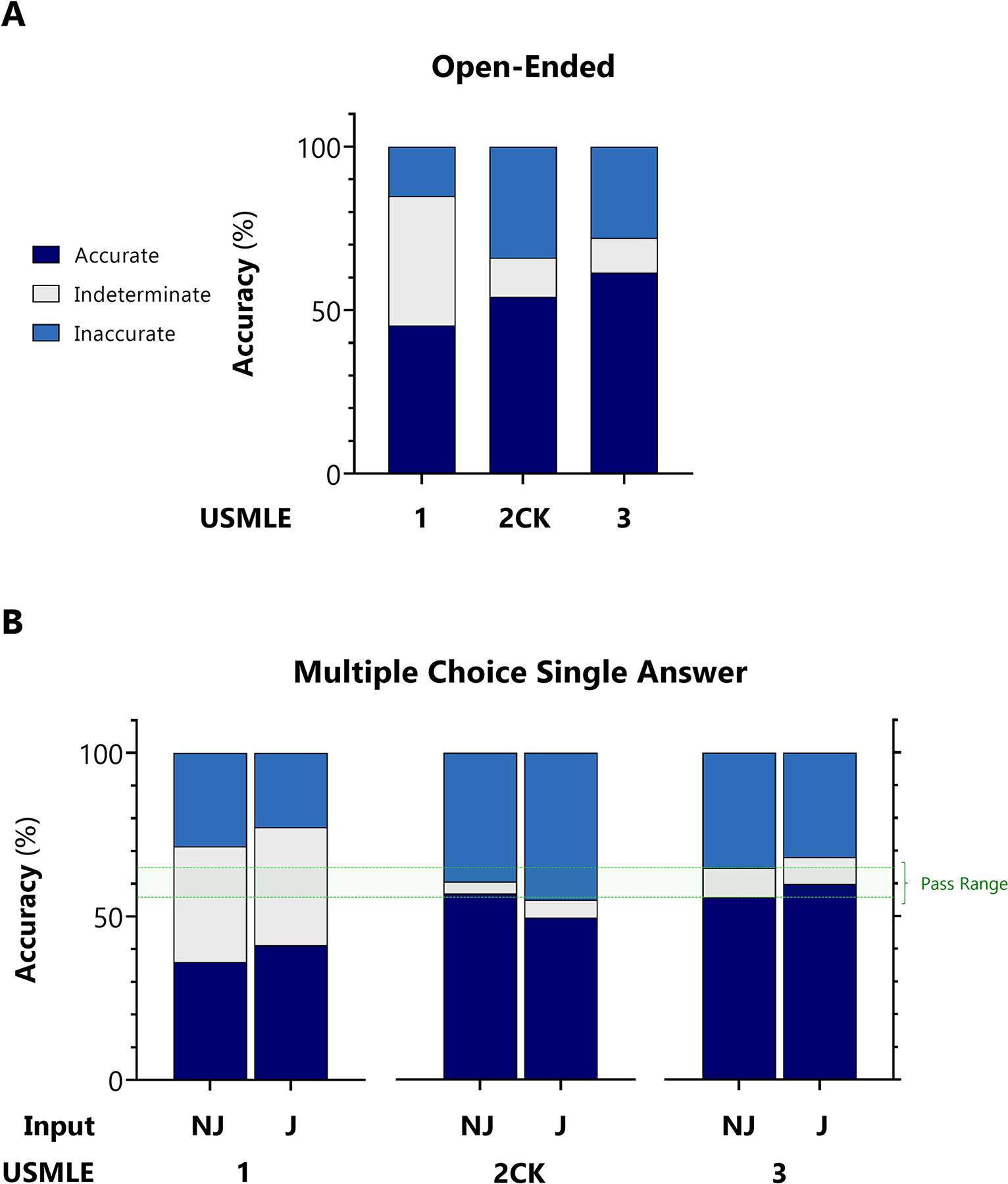
ChatGPT在其中的三项考试中均达到或接近60%准确度(也是正常情况下的及格水平)
在编码阶段,编码器和问题提示类型之间没有统计学上显着的交互作用(ANOVA)。ChatGPT 输出的答案和解释在所有问题中的一致性为 94.6%(Kappa值)。在洞察力方面,ChatGPT 在 88.9% 的所有回复中产生了至少一种重要见解
洞察密度 (DOI):通过将独特见解的数量与可能的答案选择数量进行标准化来定义的
- 高质量的产出通常以 DOI >0.6 为特征(即,在5 个选择选项中有 >3 个提供了独特的、新颖的、非显而易见的和有效的见解)
- 低质量产出通常以 DOI ≤0.2 为特征。DOI 的上限仅受文本输出的最大长度限制
- 准确回答的问题项目的平均 DOI 明显高于错误回答的问题项目(0.458 对 0.199)
基本结论:
- ChatGPT 能够执行多项与处理复杂医疗和临床信息相关的复杂任务
- ChatGPT 的准确性不断提高,接近或超过了 USMLE 的及格门槛
- ChatGPT这种 AI 有可能产生新的见解,可以在医学教育环境中帮助人类学习者