中文标题:基于图与词向量构建语义向量
英文标题:Making Sense of Word Embeddings
发布平台:ACL
发布日期:2017-08-10
引用量(非实时):156
DOI:10.48550/arXiv.1708.03390
作者:Maria Pelevina, Nikolay Arefyev, Chris Biemann, Alexander Panchenko
文章类型:journalArticle
品读时间:2022-02-21 16:05
1 文章萃取
1.1 核心观点
本文通过词向量和相关词对网络进行聚类,并从中归纳出语义向量,最终表现接近当前(论文发表时)表现最优的无监督WSD(语义消歧,word sense disambiguation)系统
1.2 综合评价
- 基于WC算法和自我中心网络构建语义向量
- 实验对比丰富,结果可靠,有开源代码
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
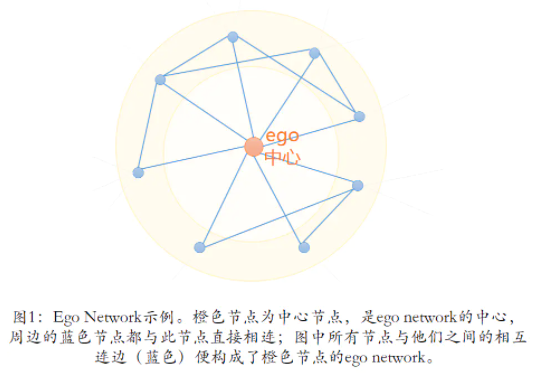
ego Network,即自我中心网络,此网络节点由唯一的中心节点(ego),以及中心节点的邻居(alters)组成,边只在ego与alter之间,以及alter与alter之间存在
早期的语义消歧采用的信息主要以相似度或者TFIDF为主,然后借助期望最大化 EM 算法或其他聚类方法建立语义的聚合。后来随着预训练词向量的兴起,才出现了基于词向量诞生的语义向量,
常见的词向量预训练方法:Skip-Gram(给定输入词,预测上下文)、CBOW(给定上下文,预测中间词)和Glove(在普通Word2vec基础上融合一些全局统计信息)
语义词典:WordNet,专业机构建立的根据词义组织词汇信息的词典,可以作为模型前置知识
Chinese Whisper算法:[[1_study/algorithm/常见聚类算法/图聚类 ChineseWhispers]]
2.2 语义向量
建立语义向量的总体流程图:
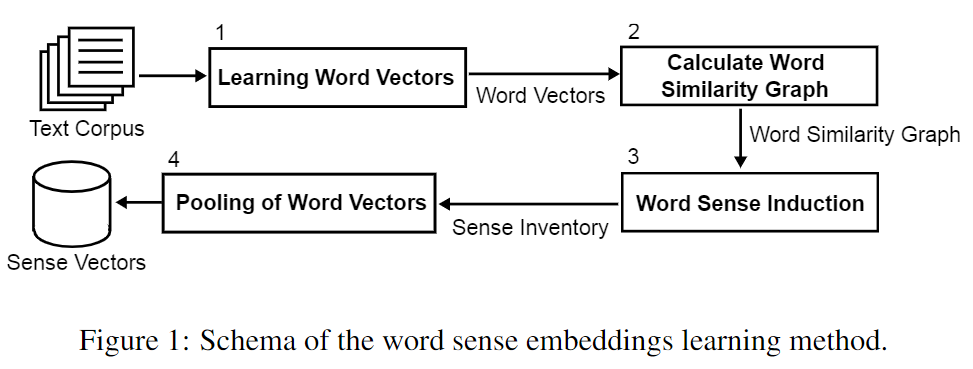
上述主要流程是可以随时调整的,比如第一步可以直接使用现成的预训练词向量;第二步的图相似度也可以选择相关特征或者更精准的计算方式;如果使用众包的方式构建语义列表,则可直接忽略第二步、第三步
2.2.1 训练词向量
本文的词向量训练主要依赖于已有的word2vec工具包,选择从词向量模型为CBOW,词向量维度包括100维和300维;滑动窗口为3;最小词频为5;训练数据集使用了Wikipedia和ukWaC
实验时,本文稍微修改了word2vec工具包,用于保留文本向量
2.2.2 根据相似度构建邻近图
本文主要使用了两种方式计算相似度:
基于词向量的余弦相似度计算(此过程可进行矩阵运算加速)
基于JoBimText(JBT)的相似度计算(一种无监督方法,先通过MaltParser从存在依赖关系的图数据中提取稀疏特征,然后使用LM1方法进行归一化,最后根据前1000个特征中的共有特征占比作为相似度的衡量依据)
本小节最终得到的将是无向有权图$T$,节点涵盖了所有的词,边的权重即为词之间的相似度
2.2.3 基于自我中心网络进行语义归纳
基于上一节构建的图$T$,对每一个节点(单词)分别构建自我中心网络,然后借助ChinesesWhispers算法,进行无监督图聚类,用聚类结果解释节点可能存在的多重语义

初始化自我中心网络:对于单词$t$,本算法会选择$N$个最相似的邻近单词来组成$t$的自我中心网络$G(V,E)$,$|V|=N+1$;而初始化刚刚完成的自我中心网络没有边,即$|E|=0$;
为自我中心网络添加边:遍历节点集合$V$,对于任意的单词$v$,选取$n$个最相似的邻近单词,并过滤掉其中不属于$V$的邻近单词,在剩余邻近单词和单词$v$之间构建边
对自我中心网络进行图聚类:借助无监督的图聚类算法——ChinesesWhispers,生成自我中心网络的聚类结果,最终结果仅保留簇内单词数大于$k$的簇
以单词"table"为例,最终的聚类结果可能如下所示:
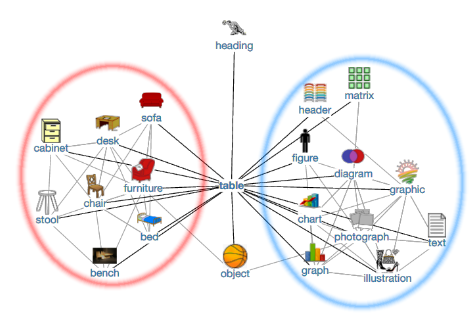
本小节共涉及三个超参,其中$N$表示自我中心网络的尺寸,即节点总数;$n$表示自我中心网络中节点的最大连接数;$k$表示最终聚类结果中每个簇的最小长度。
在本文中设定$N=200;n=50,100,200;k=5,15$
2.2.4 根据归纳结果聚合语义向量
每一个单词都得到一个聚类结果,结果中可能包含一个簇或多个簇
当然不同的相似度计算方式可能得到的结果也是有差异的,还是以单词"table"为例:
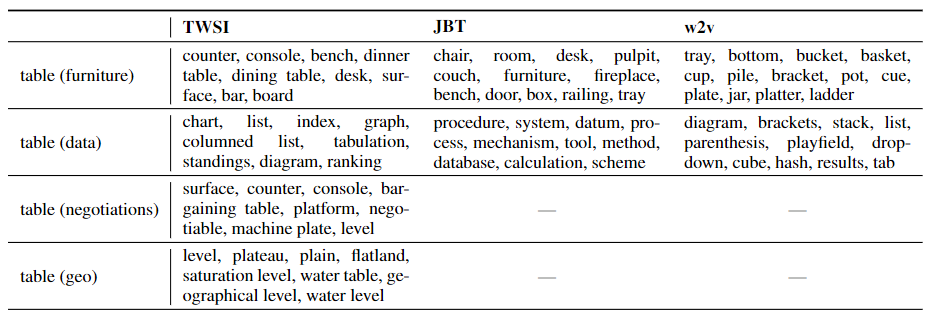
其中$TWSI$表示基于维基百科的众包方法;可以发现三种方式得到的语义聚类结果都还行~
最终的语义向量既可以是簇内简单求平均值,也可以进行簇内加权平均(以余弦相似度为权重)
2.3 语义消歧
语义向量最常用的场景就是语义消歧,也就是根据上下文找到最合适的语义向量
设单词$w$其可能的语义为$S={s_1,...,s_n}$,其对应的上下文单词为$C={c_1,...,c_k}$
策略1:基于最大概率的语义消歧(借助sigmoid函数)
$$s^{\ast}=argmax_iP(C|s_i)=argmax_i\frac{1}{1+e^{-\overline{c}\times s_i}}$$ 策略2:基于最大相似度的语义消歧(类似于余弦相似度)
$$s^{\ast}=argmax_isim(s_i,C)=argmax_i\frac{\overline{c}\cdot s_i}{||\overline{c}||\cdot ||s_i||}$$ 需要注意的是策略1中的$\overline{c}$是上下文向量的均值(mean of the context embedings),而策略2中的$\overline{c}$是上下文中的词向量的均值(mean of the word embedings),(虽然我觉得都差不多)
借助以上公式,可以计算上下文中每个词在不同语义中的影响程度,从而量化消歧能力
2.4 实验评价
评价数据集:众包收集得到的带有语义标注的TWSI(由于TWSI本身数据中,有79%为常用语义,所以考虑进行分布的无偏修正,得到Balanced TWSI);公用SemEval数据集
使用F值作为评估指标,无偏修正前后数据实验结果如下:
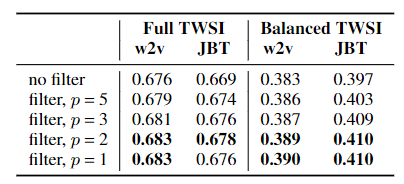
其中$p=2$表示语义消歧时使用前后2个字作为过滤依据,此时效果最好
超参选择实验结果如下:
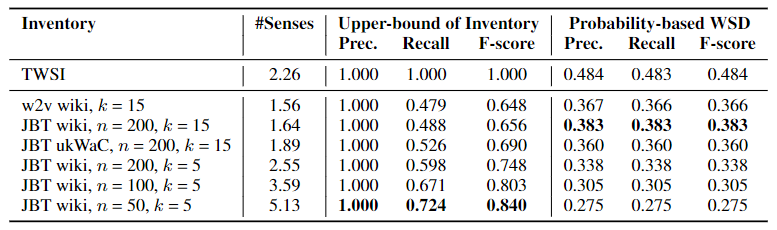
其中#Sense表示语义平均数量,Upper-bound of Inventory表示语义匹配(语义存在的前提下)的任务,Probability-based WSD表示语义消歧的任务。由此可知,语义匹配任务需要调整超参选择更细致的颗粒度,而语义消歧则需要调整超参选择更宽泛的覆盖范围。
不同词向量、聚合方法对应的最终模型表现如下:
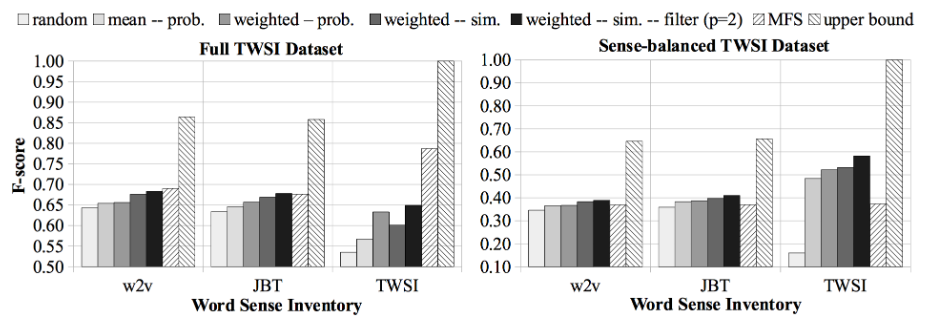
其中random表示随机选择一种语义;MFS(Most Frequent Sense)表示选择出现频率最高的一种语义;upper bound表示理论最优。综合来看,加权聚合语义向量+最大相似度选择语义的方式最终效果最优秀。
在SemEval数据集上与其他模型的对比结果:
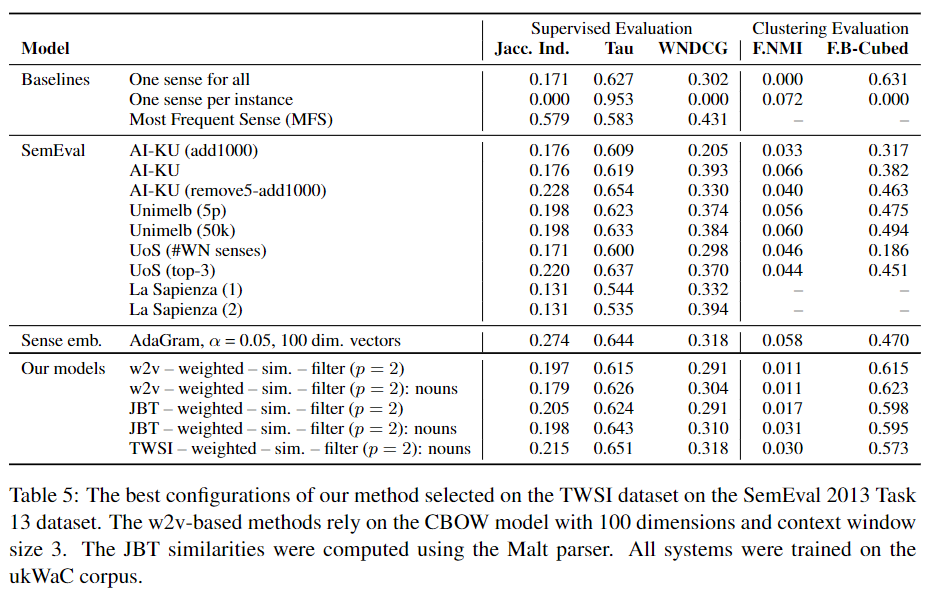
其中有监督评价指标包括:Jaccard Index, Tau and WNDCG ; 聚类评价指标包括 Fuzzy NMI and Fuzzy B-Cubed 。实验证明最终的模型在语义归纳和消歧任务上与当前其他先进模型效果相当
相关资源
参考: